1. 引言
草原生态系统是陆地生态系统的重要组成之一,其植被类型分布广泛,占陆地生态系统约三分之一的净初级生产力。内蒙古锡林郭勒草原位于内蒙古高原锡林河流,气候类型属于大陆性气候中的温带半干旱草原气候,它不仅是我国重要的畜牧业生产基地,同时也是重要的绿色生态屏障。放牧是草地生态系统主要的利用方式,是影响草地演替和生态系统服务及功能的重要因素。适度放牧能改善草原土壤质量、增加草原生物量和生物多样性,刺激植物群落超补偿生长。但过度放牧会导致草原植被结构破坏,土壤盐碱化程度加重,甚至造成草场退化、土地沙漠化。因此,合理的放牧强度和方式对维持生态系统稳定和可持续性利用具有重要意义 [1] 。
目前,学术界对不同放牧策略下草原植物群落生物量和土壤性能的变化开展了较多研究。许宏斌等以羊草草甸草原为例研究不同放牧强度对植物群落地上、地下生物量分布的影响,得出轻度或中度放牧利用该区域草地比较合理的结论 [2] 。张倩等的研究表明不同放牧模式(选择划区轮牧、禁牧、轻度放牧和生长季休牧)显著影响了高寒草甸土壤养分和物种多样性,同时不同放牧模式下土壤全钾含量、含水量、容重和pH值是影响群落物种多样性的重要因素 [3] 。本文以内蒙古锡林郭勒草原为研究对象,研究不同放牧方式和不同放牧强度对该区域的植被群落生物量、土壤理化性质等草地生态系统的影响,探讨温性草原植物群落应对不同放牧强度的响应机制,从草原生产力和多样性维持角度探寻适宜的草地管理模式,以便为锡林郭勒温带草原的放牧管理提供科学参考。
2. 不同放牧策略对土壤湿度和植被生物量的影响
草原放牧通常考虑放牧方式和放牧强度两个因素。其中,放牧方式分为五种:全年连续放牧、禁牧、选择划区轮牧、轻度放牧、生长季休牧,放牧强度分为对照、轻度放牧强度、中度放牧强度、重度放牧强度。首先针对放牧强度对土壤湿度和植被生物量的影响展开分析,然后将放牧方式对土壤湿度和植被生物量的影响反映到比例系数上。针对资料的分析可知,放牧方式中的禁牧与轻度放牧与放牧强度中的两项含义重复,因此可不单独考虑;此外,放牧策略对草原的影响强调的是时间上的影响,空间上的影响体现在草原的固有性质中,所以作为自变量的放牧方式实际上只考虑全年连续放牧以及选择划区轮牧为简化模型,放牧方式通过模型中的比例系数来体现 [4] 。
土壤湿度又称为土壤含水量,影响因素有气象因素、土壤特征、植被状况、人为活动等,而根据Woodward等建立的关于放牧与植物生长的模型,反映出载畜率对植被生物量的作用 [5] ;基于土壤含水量–降水量–地表蒸发模型可知,降水与地表蒸散发率会对土壤湿度产生影响;针对土壤–植被–大气系统的水平衡基本方程可以看出,草地的植被直接决定放牧的强度,而植被的截流量能最好反映植被的生长能力 [6] [7] 。另外本文选取了土壤鲜重、土壤蒸发量、植被指数(NDVI)、放牧强度和径流量五个因素为自变量,对土壤湿度展开分析。植被生物量即为植物地上生物量,其大小可以从植物的干重上间接体现出来,因此本文将基于科研工作者采集的样品中的干重数量对植被生物量展开研究,得出不同放牧强度对植被生物量的影响。
2.1. 数据预处理
根据上述思路,利用python软件将数据表进行合并,得到包含10 cm土壤湿度、40 cm土壤湿度、100 cm土壤湿度等变量的综合数据集,并对数据进行相关预处理。
2.1.1. 缺失值处理
本文“鲜重(g)”和“株/丛数”等指标存在少量缺失值,基于回归插值法,根据同一指标的现有数据,对缺失值进行估算。具体思路为构建自变量
与目标变量Y的关系,则第k个缺失值的插补估算值可由公式(1)计算,其中Ƹ指随机因素。
Ƹ
(1)
2.1.2. 异常值、重复值处理
异常数据可能来自数据本身、存储或转换过程,可删除记录或视为缺失值。本文采取
原则、绝对中位差法和分位数法对各指标进行处理,其中
原则为设各指标在不同时间的取值为
,算出各指标平均值
及取值的误差
和指标标准差
。
若某测量值
的剩余误差
满足
,则认为
应予修正。由于数据量较大,合并难免会产生相同的行数据,以每一行数据为基础,剔除完全相同的行,便于后续的数据分析。
2.1.3. 数据归一化
本文为消除不同量纲的影响,采取归一化方式对数据标准化,使得原始数据结果映射到0~1之间,即公式(2):
(2)
此为多指标面板数据,
表示第i个指标在t时刻的第j个指标的原始观测值。
为标准化结果,
和
分别为指标的最大值和最小值。
2.2. 模型建立与求解
2.2.1. 相关性分析
本文选取土壤鲜重、土壤蒸发量、植被指数(NDVI)、放牧强度和径流量作为自变量,因变量是四种不同深度的土壤湿度。针对上述变量进行相关性分析,绘制热力图如图1所示。

Figure 1. Heat map of correlation coefficients between variables
图1. 变量的相关系数热力图
由热力图可知,不同深度土壤的湿度存在较强的相关性,所以在进行分析相关因素对土壤湿度的影响时,可以逐步添加变量,比如在分析40 cm土壤湿度受各因素的影响时可以将10 cm土壤湿度纳入模型,在分析100 cm土壤湿度受各因素的影响后可以将10 cm和40 cm的土壤湿度纳入模型,在分析200 cm土壤湿度受各因素的影响后可以将前三种深度土壤湿度纳入模型 [8] 。此外,由图1可知鲜重、土壤蒸发量、植被指数等5个变量间的相关性并不高,且根据资料表明各变量对土壤湿度存在影响,因此将这5个变量同时纳入模型是切实可行的。
2.2.2. 岭回归模型简介
1962年,Hoerl首次提出岭回归,并在1970年和Kennard进一步对岭回归模型做出了详细讨论,证明自变量间存在多重共线性,岭回归是改良后的普通最小二乘估计,通过对最小二乘估计进行了改进,以达到消除共线性影响的效果 [9] 。它是一种改良的最小二乘法,实际上是在线性回归的损失函数后加一个L2正则化项,以达到消除共线性影响的效果,能根据回归结果分析各因素对因变量的影响程度和方向。
(3)
公式(3)中,X是输入的特征矩阵;y是输出矩阵;w是模型的参数向量;C是大于零的常数。在公式(3)中加入拉格朗日乘子法,将有约束的优化问题转换为公式(4)的无约束的惩罚函数优化问题。
(4)
岭回归的解为:
2.2.3. 岭回归模型建立与求解
根据是否带变量交叉项,针对10 cm土壤湿度和放牧强度等5个因素进行两次岭回归分析,得出两次回归的判定系数如表1所示,同理对其他三种土壤湿度作相同操作。对比可知,本次岭回归应包含交叉项,进一步对回归的各系数大小进行可视化展示如图2所示。

Table 1. Model evaluation of ridge regression based on soil moisture at different depths
表1. 基于不同深度土壤湿度岭回归的模型得分表

Figure 2. Regression coefficient plot of 10 cm soil moisture ridge regression
图2. 10 cm土壤湿度岭回归的回归系数图
根据岭回归的结果可知,5种因素对10 cm湿度的回归方程为:
其中,X1表示鲜重(g),X2表示土壤蒸发量(mm),X3表示植被指数(NDVI),X4表示放牧强度,X5表示径流量(m3),
为滞后项,用于拟合前期数据对当期数据的影响。
2.3. 结果分析
2.3.1. 基于不同深度土壤湿度的分析
根据岭回归方程各参数可知,植物鲜重与10 cm土壤湿度(本段下同,均针对10 cm的土壤分析)呈现正相关,植物鲜重越大土壤湿度越大;土壤蒸发量的二次项系数为负,说明土壤蒸发量越大土壤湿度越小;在一定范围内,植被指数越大土壤湿度会相应加大,在范围之外土壤湿度会相应减小;放牧强度和径流量在草原可承受的区间范围里,对土壤湿度的影响也与植被指数所产生的相应规律类似。
同理,针对40 cm土壤湿度、100 cm土壤湿度和200 cm土壤湿度展开岭回归分析,通过对比是否考虑交叉项所得的两种模型得分确定最终模型,相应的回归系数图如图3、图4和图5所示,相应的回归方程可参考10 cm土壤湿度的岭回归结果给出,据此也可得出类似的规律。

Figure 3. Regression coefficient plot of 40 cm soil moisture ridge regression
图3. 40 cm土壤湿度岭回归的回归系数图
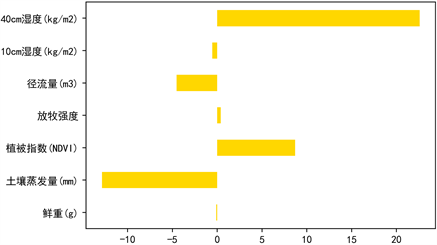
Figure 4. Regression coefficient plot of 100 cm soil moisture ridge regression
图4. 100 cm土壤湿度岭回归的回归系数图
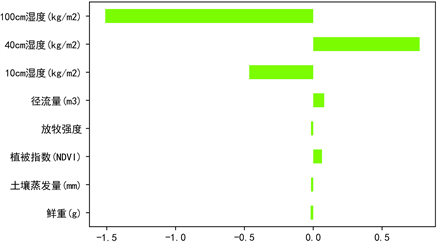
Figure 5. Regression coefficient plot of 200 cm soil moisture ridge regression
图5. 200 cm土壤湿度岭回归的回归系数图
2.3.2. 基于植被生物量的分析
根据预处理过后的监测数据集,将各年份6月1日的数据代表5月的监测数据。首先根据放牧强度将监测结果进行分组,然后以月为频率对数据进行重采样,最后对植物的干重进行求和汇总得到不同月份在不同放牧强度下的植被生物量,对所有月份的植被生物量计算均值,结果如表2所示。
Table 2. Average vegetation biomass under different grazing intensities
表2. 不同放牧强度下植被生物量均值情况
由表可知,随着放牧强度的加大,植被生物量呈现先增后降的趋势,即轻牧条件下对植被生长的促进能力最强,重牧则会对植被造成破坏。然后不同放牧强度下,根据各月份的植被生物量绘制柱形图如图6所示,可以看出每年的7、8、9月份的植被生物量达到峰值,这可能与植物的自身生长规律有关,另外也能清晰发现无牧和重牧条件下的植被生物量相比轻牧和中牧条件下更少,也能间接反映出轻牧条件下对植被生长的促进能力最强,重牧则会对植被造成破坏。
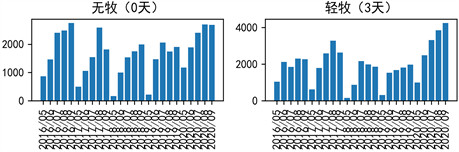
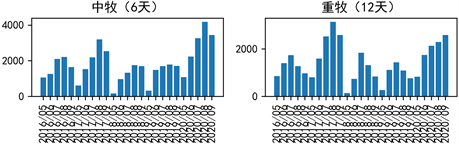
Figure 6. Vegetation biomass under different grazing intensities
图6. 不同放牧强度下的植被生物量
2.3.3. 基于放牧方式的分析
根据前文的分析可知,在已有与放牧强度有关的分析的基础上,可以通过加入一个比例系数展开讨论,如草原的放牧方式为全年连续放牧时,相当于放牧强度按照一定程度加大;只选择生长季放牧时,等价于放牧强度按照一定程度减小,其对土壤湿度和植被生物量的影响会相应减小。
3. 不同深度土壤湿度的预测模型
通过2012~2022年土壤湿度、土壤蒸发量及锡林郭勒盟气候的相关数据,建立数学模型,用来预测2022年、2023年4种不同深度下的土壤湿度值,将土壤湿度在不同深度的数据作为预测输出值,土壤蒸发量和草原气象等数据作为输入值。气候变化通过影响区域降水量、蒸发量而引起水资源供需平衡的变化,从而影响区域水资源可持续利用与农牧业可持续发展。
为了对不同深度的土壤湿度值进行预测,首先绘制不同深度土壤湿度值的时间序列图,如图7所示。其次,分别构建BP神经网络、随机森林和XGBoost模型,使用2012~2021年数据训练模型,并选择最优模型作为最终预测模型。然后,采用ARIMA模型根据以往数据对2022~2023年的各自变量值进行预测。考虑用时间序列模型进行自变量未来值的预测,之后输入到预测模型中对最终结果进行回归预测。最后,将ARIMA模型预测出来的自变量值输入到训练好的机器学习模型中,对不同土壤深度的湿度值进行回归预测,并得到最终的预测结果表。具体实现路线如图8所示。
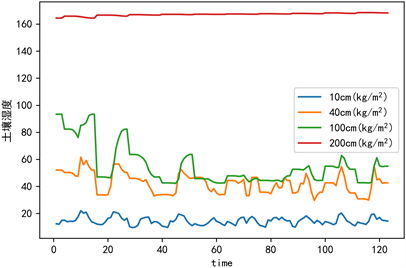
Figure 7. Time series plot of soil moisture at different depths
图7. 不同深度土壤湿度值时间序列图
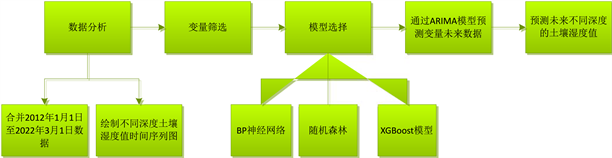
Figure 8. Prediction process of soil moisture at different depths
图8. 不同深度土壤湿度预测过程
3.1. 模型建立与求解
3.1.1. 变量选择
2012~2022年土地蒸发量数据中所包含两个指标:土壤蒸发量(W/m2)和土壤蒸发量(mm),由于两个指标之间可以相互转换,故选取其一土壤蒸发量(mm)作为自变量。分析锡林格勒气象条件数据,发现平均最大瞬时风速(knots)、最大瞬时风速极值(knots)、积雪深度(mm)和平均温度 ≥ 35℃的天数变量存在缺失值过多或取值全为0,因此选择平均气温(℃)、平均最高气温(℃)、平均最低气温(℃)、最高气温极值(℃)、最低气温极值(℃)、平均气温 ≥ 18℃的天数、平均气温 ≤ 0℃的天数等20个草原气候变量为自变量。
考虑土壤深度为10 cm、40 cm、100 cm和200 cm时,土壤湿度不仅与气候条件、土壤蒸发量有关,不同土壤深度之间也存在相关性。在不同的土壤深度下,水分会有着不同的沉降、上升等情况,某一湿度值会受到其他土壤深度和湿度的影响。所以选择某一土壤湿度值作为预测模型的因变量时,其余三个不同土壤深度的湿度值也看作自变量 [10] 。综上所述,选取区别于自变量的另一深度土壤湿度值作为因变量,自变量和因变量均为连续性变量。具体选取变量如图9所示。
3.1.2. 算法简介
1) 随机森林模型
随机森林(Random Forests, RF),又名随机决策森林,其基本思想是通过随机形式建立由很多棵彼此之间没有任何联系的决策树组成的一个森林。创建好了森林,每当新样本进入随机森林,会使得每颗决策树对其进行判定,最终得出新样本的类别 [11] 。
随机森林模型的优点如下:(a) 随机森林可以同时处理数值特征和分类,随机森林可以用在解决回归和分类问题方面。(b) 具有较强的抗过拟合能力,利用平均决策树的作用,从而降低过拟合的风险性。(c) 随机森林模型较稳定,因为它只会影响到一颗决策树,所以不容易对整个随机森林产生影响。(d) 随机森林模型鲁棒性强,对数据有很好的包容性。
2) XGBoost模型
XGBoost算法是基于梯度提升树的集成学习算法 [12] 。其基本的组成部分是CART树,每一棵新树的建立都是为了尽可能多地减小损失函数值,以此对目标函数进行优化和估计。在合理的参数设置下,需要生成一定数量CART树才能达到令人满意的预测准确率。将含m个特征、容量为N的数据集
,所有CART树的集合记为
。其中,q代表样本映射到相应的叶子结点的决策规则,T代表一棵树的叶子结点数量,w代表叶子结点的得分。f代表CART树,包括树的结构q和叶子结点的得分w。基于XGBoost算法的
的预测值可以表示为:
(5)
其中,
,K为CART树的数量。XGBoost算法在每一次模型训练时保留前面t − 1轮的预测不变,加入新函数
到模型中,
为第i个样本在第t次模型训练时的预测结果。假设基学习器的误差相互独立,XGBoost算法的学习目标是找到
,最小化以下目标函数式:
(6)
3) BP神经网络模型
BP神经网络是一种按照误差逆传播算法训练的多层前馈网络,由众多的神经元可调的连接权值连接而成,具有大规模并行处理、分布式信息存储、良好的自组织自学习能力等特点,在信息处理、模式识别、智能控制及系统建模等领域有越来越广泛的应用。BP网络可以学习和贮存大量的输入–输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。它的学习规则是使用最速下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小 [13] 。
4) ARIMA模型
时间序列是按时间顺序的一组数字序列。时间序列的预测分为几个步骤,首先需要对历史数据进行预处理(异常值、缺失值等的处理),接下来需要对处理后的数据进行分析,根据其所展现的趋势和方向。时间序列预测模型主要分为两大部分,线性预测模型和非线性预测模型。ARIMA模型比较擅长对线性时间序列进行预测。
ARIMA模型包含3个部分,即自回归(AR)、差分(I)和移动平均模型(MA)。ARIMA模型的构建步骤可以分为:时间序列平稳性检测、非平稳序列处理、模式识别、模型优化和模型检验几个步骤:(a) 平稳性检测;(b) 非平稳序列处理;(c) 纯随机性检验;(d) 模式识别;(e) 模型优化;(f) 模型检验 [14] 。
3.1.3. 回归预测模型建立与求解
本文针对不同深度土壤湿度值选用随机森林模型、XGBoost回归模型和BP神经网络模型建立回归预测模型,并结合交叉验证的方法选择效果最优的模型进行最终预测。评价指标均方误差MSE、R2去评估模型效果,MSE是预测值与实际值之差平方的期望值,其取值越小,模型准确率越高。R2越接近1,模型的效果越好。针对四种不同深度的土壤湿度值的最优回归预测模型如表3所示。
Table 3. Performance table of optimal regression prediction models for soil moisture at different depths
表3. 不同深度土壤湿度的最优回归预测模型效果表
3.1.4. ARIMA模型建立与求解
以变量100 cm湿度(kg/m2)为例,进行ARIMA模型的建立与预测。首先,通过ADF单根检验法来检验时间序列是否平稳,由ADF检验表4可知,在差分为1阶和2阶时,显著性P值为0.003、0.000,水平上呈现显著性,拒绝原假设,通过平稳性检验(1阶差分后的时序图如图10所示)。
注:***、**、*分别代表1%、5%、10%的显著性水平。
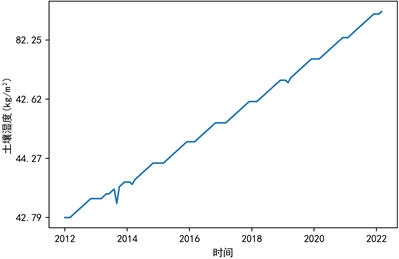
Figure 10. First order differenced time series plot of original data
图10. 原始数据1阶差分后的时序图
然后基于AIC信息准则自动寻找最优参数,确定100 cm湿度(kg/m2)预测模型为ARIMA(0, 1, 1),基于变量100 cm湿度(kg/m2),从表5中Q统计量结果分析可知:Q6在水平上不呈现显著性,不能拒绝模型的残差为白噪声序列的假设,同时模型的拟合优度R²为0.966,效果良好。
Table 5. Test table of ARIMA model (0, 1, 1)
表5. ARIMA模型(0, 1, 1)检验表
注:***、**、*分别代表1%、5%、10%的显著性水平。
最后,用ARIMA(0, 1, 1)模型对100 cm湿度(kg/m2)变量值进行预测。同理,可根据ARIMA模型得出剩余变量的未来预测值。
3.2. 模型预测结果
通过ARIMA模型对2022年4~2023年12月的各自变量值进行预测,并将预测数据代入训练好的最佳模型中,得出在目前放牧策略不变情况下,2022、2023年不同深度的土壤湿度值,具体预测结果详见表6所示:
Table 6. Prediction table of soil moisture at different depths
表6. 不同深度的土壤湿度预测表
4. 不同放牧策略对土壤化学性质的影响
首先使用不同放牧强度下草原监测数据,建立不同放牧方式和放牧强度对锡林郭勒草原土壤化学性质影响的数学模型。选取相关因素作为自变量对土壤有机碳SOC、土壤无机碳SIC、土壤全碳STC建立岭回归模型,对比考虑交叉项和不考虑交叉项时的模型性能,以确定最终选取哪种方式建模。同时,结合模型各指标系数取值情况,分析不同放牧强度对土壤化学性质的影响程度,并通过比例系数反映放牧方式对土壤化学性质的影响。
其次给出12个小区监测点,利用不同放牧强度土壤碳氮监测数据,建立数学模型预测2022年12个放牧小区在四种不同放牧强度下的土壤化学性质数值。由于考虑不同放牧强度对各种化学性质的影响,相当于单变量回归,同时数据包含2012~2020年中偶数年草原监测数据,每个放牧强度设置多个重复,共132条数据,数据量较少,所以该问选择XGBoost模型对五种化合物在不同放牧情况下进行回归预测。
土壤化学性质数据包含土壤有机碳SOC、土壤无机碳SIC、土壤全碳STC、全N、土壤C/N比,而通过分析可知土壤全碳STC和土壤C/N比可通过其余3个指标计算得来,其计算公式如下所示。故选择土壤有机碳SOC、土壤无机碳SIC和全N三项土壤化学性质指标进行分析求解。
土壤全碳STC = 土壤有机碳SOC + 土壤无机碳SIC。
土壤C/N = 土壤全碳STC/全N。
4.1. 模型建立与求解
首先,考虑到数据的可获取性和相关文献,本文考虑上述3个指标作为因变量,自变量是放牧强度和放牧小区。因变量是连续性变量,自变量通过设置哑变量的方式进行变量转换。
根据是否带变量交叉项,针对土壤有机碳SOC与放牧强度、放牧小区哑变量等15个因素进行两次岭回归分析,得出两次回归的判定系数如表7所示。由下表结果对比可知,在无交叉项时岭回归模型得分均较高,因此建模时不考虑交叉项。此外,进一步对回归的各系数进行可视化展示如图11所示。
Table 7. Model evaluation table of ridge regression based on soil moisture at different depths
表7. 基于不同深度土壤湿度岭回归的模型得分表
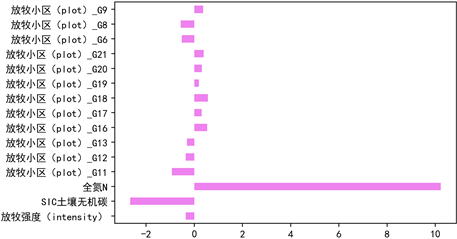
Figure 11. Regression coefficient plot of soil organic carbon (SOC) ridge regression
图11. 土壤有机碳SOC岭回归的回归系数图
由岭回归的结果可知,15种因素对土壤有机碳SOC的回归方程如下:
其中,Y5表示土壤有机碳SOC,X6表示放牧强度(intensity),X7~X18表示12个放牧小区(plot)哑变量,
为滞后项,用于拟合前期数据对当期数据的影响。
4.2. 结果分析
4.2.1. 基于放牧强度的分析
根据方程的系数可知,在其他条件保持不变的情况下,随着放牧强度或SIC土壤无机碳含量的增大土壤有机碳SOC的含量会降低,而全氮N的含量与土壤有机碳SOC的含量呈现正相关,且其含量对有机碳含量的影响显著;而对比放牧小区的情况可知,小区6、小区8、小区9、小区11、小区12、小区13这6个小区相比其他小区而言,有机碳含量相对更低一些。
同理,我们对土壤无机碳SIC、全N含量展开岭回归分析,相应的回归系数如图12和图13所示,相应的回归方程可参考土壤无机碳SIC的岭回归结果给出,据此也可得到类似的规律。
4.2.2. 基于放牧方式的分析
根据上述推理可知,在已有与放牧强度有关分析的基础上,可以通过加入比例系数展开放牧方式对土壤化学性质影响的研究得出结论:如果草原的放牧方式为全年连续放牧时,相当于放牧强度按照一定程度加大;只选择划区轮收时,等价于放牧强度按照一定程度减小,其对土壤化学性质的影响会相应减小,其他规律也可参考以上分析相应给出。
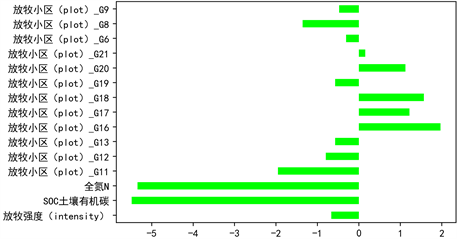
Figure 12. Regression coefficient plot of soil inorganic carbon (SIC) ridge regression
图12. 土壤无机碳SIC岭回归的回归系数图
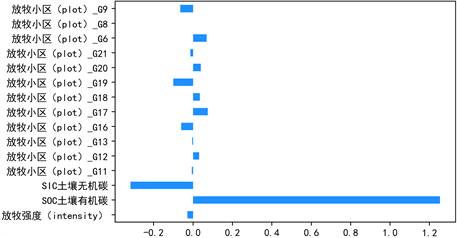
Figure 13. Regression coefficient plot of total N ridge regression
图13. 全N岭回归的回归系数图
4.3. 基于土壤化学性质的XGBoost预测模型
4.3.1. 模型建立
选择土壤有机碳、土壤无机碳和全氮建模,根据三种土壤化合物预测结果计算土壤全碳和土壤C/N比。此外,数据不存在异常情况,因此不需要进行预处理操作。采用XGBoost算法建立单变量回归预测模型,用来预测2022年12个小区的土壤化合物值。每一个小区包含2012、2014、2016、2018和2020这五个年份的放牧强度和土壤化合物值。由于每一个小区只对应一个放牧强度,在此不考虑放牧强度,根据12个小区进行分类,针对每个小区依次使用XGBoost算法构建三个土壤化合物对应的单变量回归预测模型,分别对应对3种土壤化合物的预测。将年份作为自变量,每一个化合物作为因变量单独构建回归预测模型。
数据集的特征与模型的选取决定了预测结果准确度的上限,而对模型参数的调整能够帮助无限接近准确度的上限值。为了进一步提高XGBoost回归预测的准确率,本文对建立的基于XGBoost算法的回归预测模型进行了参数调优,主要选取三个超参数:learning_rate (控制每个弱学习器的权重缩减系数)、max_depth (基学习器的树最大深度,该参数用于避免过拟合)和n_estimators (梯度增强树GB的数量,也等于最大迭代的次数作为优化目标)。XGBoost取max_depth = 3,n_estimators = 100,learning_rate = 0.1,其余参数为默认参数。
4.3.2. 模型预测结果
根据本文建立的XGBoost回归模型,对2022年锡林郭勒草原监测样地在四种放牧强度下的土壤化合物有机碳、无机碳、全N进行预测,计算相应的土壤全碳和土壤C/N比,将结果展示如表8所示。
Table 8. The prediction table of soil chemical properties in 2022
表8. 2022年土壤化学性质预测表
5. 结语和未来工作
本文以锡林郭勒草原为例,根据监测点数据,采用岭回归分析、BP神经网络和XGBoost回归模型等机器学习方法,通过Python、Matlab以及SPSS等软件进行求解,得出如下结论:一方面,随着放牧强度的加大,植被生物量呈现先增后降的趋势,同时无牧和重牧也不利于植被生长;另一方面,针对2022年4月~2023年12月不同深度的土壤湿度值进行了预测,也分析得出锡林郭勒草原监测样地在不同放牧强度下2022年土壤同期有机碳、无机碳、全N、土壤C/N比的值,对实施可持续发展的草原放牧策略具有战略意义。为提高模型的实用性,后续研究会考虑到部分特征间的相关性。