1. 引言
我国作为世界上最大的二氧化碳排放国,曾在第75届联合国大会上承诺,到2030年达到碳排放峰值,到2060年实现碳中和。碳金融是实现减碳目标的重要且不可缺少的金融手段。碳排放权交易(简称碳交易)体系的建立,可以通过市场对碳排放进行调节,但由于我国碳交易市场起步较晚,有很多学者的研究是基于发展更为成熟的欧盟碳交易体系进行,并不完全适配我国碳交易市场的发展现状,因此需要对我国自己的碳交易市场进行研究。碳交易市场中碳排放权交易价格(简称碳价)的预测,是碳交易市场研究的重要部分。
2. 研究现状分析
碳排放权交易市场是利用市场机制控制和减少温室气体排放的政策工具 [1] 。碳排放权交易通过显性碳定价原则,也称“污染者付费”原则,将排放的负外部效应内部成本化,为处理经济发展与减排关系难题提供了一种解决方案。当前国际上发展最成熟,影响力最大的是欧盟排放交易体系,因此有很多的研究是基于欧盟的碳价数据进行的。2011年10月,我国正式批准了包括北京、天津、重庆、上海、湖北、广东和深圳在内的七省市率先开展碳排放权交易市场试点,并于2021年7月正式启动全国碳市场。随着我国碳市场的不断完善,也需要针对我国本土的碳交易体系进行研究分析,从而可以更加科学稳妥的发展,早日实现减排目标。
目前针对碳价预测,有很多学者从多方面进行研究。传统的统计学方法主要包括自回归差分移动平均模型(ARIMA)、广义自回归条件异方差模型(GARCH)、自回归模型(AR)、线性回归方法等,在使用传统的统计模型方面。Heiea和Haraldur [2] 首先引入了多元线性回归模型来对碳价进行预测,Byun和Cho则提出了基于不同GARCH类型的预测模型来预测碳期货的波动率 [3] 。随着研究的不断深入,Sanin等提出了在ARMAX-GARCH模型中引入时变跳跃概率 [4] ,随后进行实证并取得了较好的预测结果。然而,由于碳价具有非平稳非线性的特点,在利用传统统计学模型进行预测之前,需要先对碳价数据进行处理使得其平稳后才可以进行预测。考虑引入基于人工智能的预测方法。其中,常见的用于碳价预测的单一模型主要包括人工神经网络(ANN)模型 [5] 、最小二乘支持向量回归(LSSVR) [6] 等。但常常由于价格序列的噪声大,波动幅度强,导致单一模型的预测性能并不是很准确。所以目前更多的碳价模型是集成模型,Zhu [7] 提出了基于EMD算法来分解数据并利用ANN来预测的模型,有效地提高了碳价的预测精度。随后,高杨和李健 [8] 构建了基于EMD-PSO-SVM算法的误差矫正模型,发现该模型对欧盟碳价和欧盟的减排量价格都具有较高的预测精度。2022年,魏宇等 [9] 运行多种模型进行对比,在经典预测模型、动态模型选择和动态模型平均方法中发现,动态模型选择的结果更加准确。随后2023年,朱亮亮等 [10] 也对ARIMA模型、多项式回归算法和LSTM模型进行对比,最终效果最好的模型是PCC-LSTM模型。
LSTM模型对于时间序列的处理能力很优秀,可以捕捉到非线性关系以及序列中的长期依赖性,而金融数据又是典型非线性的时间序列数据,并且金融市场的很多趋势都会跨越较长时间,因此可以推断LSTM模型可以很大程度上提高对金融数据的预测,例如丁文绢 [11] 分别利用ARIMA模型与LSTM模型分别对一只股票数据进行预测,得出针对于股票的预测精度而言,LSTM模型的结果优于ARIMA模型。但LSTM模型又存在一些不可避免的缺点,例如LSTM模型的内部比较复杂,极其容易发生过拟合的现象;金融数据包括大量噪声,LSTM模型也可能学习到这些噪声,从而影响预测的准确率;模型的结构特点也容易造成局部最优化的缺点。而宽度学习BLS的提出也为序列预测提供了新的思路,BLS具有不用进行大量计算,直接计算权重,泛化能力强的特点,CHEN等 [12] 也在理论层面证明了该方法在涉及时序数据的预测上有很好的函数逼近能力,并通过具体实验得到与现在的几种算法相比,BLS模型在回归方面更加优越。
综上分析,本文利用BLS模型高效的优点,结合LSTM在金融数据上优秀的表现能力,构建基于LSTM-BLS模型的碳价预测模型。通过将LSTM模块的输出特征承接BLS模型,以防止出现梯度爆炸,局部最优等问题,从而建立更加高效准确的碳价预测模型。
3. 模型结构
3.1. 宽度学习
宽度学习(Broad Learning System, BLS)是澳门大学陈俊龙教授在2018年基于随机向量函数链神经网络(Random Vector Functional-Link Neural Network, RVFLNN)提出的一种灵活结构网络 [13] 。BLS有很好的泛化能力,并且如果需要加入新的数据,也有很快的进行扩展,不需要重新训练模型。其网络结构如图1所示。
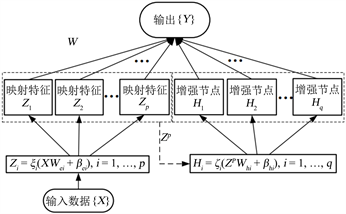
Figure 1. Broad learning system network structure diagram
图1. 宽度学习网络结构
假设数据集X,包含N个样本,每个样本有M个维度,Y是属于
的输出矩阵,Q是输出的维度。利用公式(1),特征映射为
,得到特征层的各个特征节点
可以表示为:
(1)
式中,
和
分别为随机生成的稀疏化链接权重和偏置;n为特征层特征节点的组数。
表示所有特征节点
。随后把所有特征节点
作为增强层的输入,经过非线性激活函数
,得到增强层的各个增强节点
可以表示为:
(2)
式中,
和
分别为随机权重和偏置。BLS的增强层节点可以表示为
。结合特征节点和增强节点,BLS的公式可以表示为:
(3)
式中,W为BLS模型的输出权重,可由加权岭回归的求解方法得到:
(4)
其中,
为正则化系数,I为单位矩阵。
3.2. 长短期记忆网络
长短期记忆网络(Long Short-Term Memory, LSTM)是循环神经网络(Recurrent Neural Network, RNN)的一种特殊情况,是1997年由Hochreiter和Schmidhuber首次提出。LSTM模型在处理时间序列数据方面由明显的优势,其和RNN模型中不同的组成部分可以减少RNN在处理长序列数据时产生的梯度爆炸或梯度消失的问题。所有的LSTM都具有一种重复神经网络模式的链式形式,重复的结构模式都是一个结构,可以如图2所示。

Figure 2. Long short-term memory structural principle
图2. LSTM模型结构原理
其中,
是输入的数据向量,
是时间为t时的输入状态,
为时间为t时的单元遗忘状态,
为时间为t时的输出状态,
和
是时间为
时中的隐藏状态和单元状态。LSTM模型是通过引入tanh和sigma为激活函数
的公式加入非线性特征。具体流程计算公式为:
(5)
(6)
(7)
(8)
(9)
(10)
其中,
、
、
、
分别为遗忘门、输入门、输出门以及记忆单元的权重矩阵,
、
、
、
分别代表遗忘门、输入门、输出门以及记忆单元的输出值,其中符号
是指Hadamard积。LSTM模型的关键在于其单元状态,用来对数据进行存储和筛选。
3.3. LSTM-BLS模型
融合LSTM模型和BLS模型的优势,提出LSTM-BLS相结合的数据预测模型,将预处理后的数据输入LSTM模块提取输入数据的特征,将输出的数据作为BLS模型的输入数据进行输入,再次提取数据的特征,同时自动生成特征节点和增强节点,输出最终的预测结果。
4. 模型实证检测
4.1. 数据准备
我国全国性的碳交易市场于2021年7月开始,数据量较少,考虑选取发展时间更长,数据量更多的湖北碳市场,时间选取为2014年4月28日至2023年9月1日,共计2209个数据,选择前80%时间序列数据为训练集,后20%的序列数据为测试集。由于交易市场仅在交易日开放,存在部分时间缺失问题,本文在数据预处理阶段剔除空缺数据,构建更加可靠的序列数据并利用公式(11)对数据进行归一化处理,公式为:
(11)
其中,
和
分别代表数据中的最大值和最小值。在归一化处理之后,考虑使用窗口滑动法对序列数据进行处理,窗口滑动法可以提取序列的局部特征,这对于捕捉时间序列中的短期依赖关系和模式非常有用。
4.2. 实验设置
实验的参数设置,针对LSTM模块,考虑2209个数据量不算庞大,本研究选择了较小的参数,其中参数含义分别为:Layers (层数)是指LSTM模型中堆叠的LSTM层的数量,每一层都包括一定数量的神经元;Number of neurons (神经元数目)每一层中的神经元数据,神经元是LSTM的基本单元;batch size (批量大小)是指每次模型参数更新前,一次训练所需的样本数;Epoch (迭代次数)是指数据集完整送入网络几次;Activation (激活函数),针对LSTM常用tanh和sigmoid作为激活函数;Loss (损失函数)用于量化预测值和真实值之间的误差,对于回归问题,常用MSE作为损失函数;Optimizer (优化器)则是决定了如何对权重进行更新以达到最优效果,Adan是通用选择。随后,将Dense层链接LSTM模型和BLS模型,其中BLS模型参数中的N1表示每个窗口的特征映射层的节点数,它决定了每个窗口生成的特征数量;N2表示窗口的数量,每个窗口都会生成一组特征;N3表示增强层的节点数,用于进一步提取特征;s表示收缩参数,用于控制增强层输出的范围;c表示正则化参数,用于控制输出权重的平滑度。经过多次调整参数信息,最终得到最优参数,如表1的参数信息。
本文选取3个指标进行模型效果对比,分别为MAE,RMSE,R2_score,其公式分别为:
(12)
(13)
(14)
其中,
、
以及
分别表示实际值、预测值和平均值。
4.3. 结果分析
通过python编程实现LSTM-BLS模型的结果,并给出与基线模型:ARIMA和SVM模型以及单一LSTM模型的预测结果对比,见表2。可以看出,基线模型相比LSTM-BLS模型在具体数据的表现上存在明显差距。SVM模型在处理金融数据这类较复杂的数据时存在一定缺陷,LSTM模型对于金融序列数据处理能力较好,但存在一定的梯度问题,ARIMA模型对于处理平稳数据具有优势,但由于碳价数据具有非平稳非线性的特点,需要经过差分后进行处理,对碳价的预测准确率也比不上本文提出的模型。

Table 2. Comparison of results between the LSTM-BLS model and baseline models
表2. LSTM-BLS模型与基线模型结果数据对比
5. 结束语
关于碳价的预测一直是研究我国碳交易市场的重要组成部分,碳价受诸多因素影响,尤其受到政策制定的影响,但碳价的走势也影响市场制度制定者的决定。随着我国碳交易市场的不断发展,2024年1月5日,国务院发布了《碳排放权交易管理暂行条例》,自2024年5月1日起施行。这个条例的目的是为了规范碳排放权交易及相关活动,加强对温室气体排放的控制,并促进经济社会绿色低碳发展。促进低碳发展,早日达成减碳目标,都离不开碳市场的发展。对于普通投资者而言,碳价也是最为直观信息体现。因此,如何高效准确地预测碳价也是我们一直以来不断研究的领域。本文将宽度学习与深度学习中针对时序数据表现良好的循环神经网络模型相结合,提出了融合LSTM和BLS的碳价预测模型。通过实例对比,发现BLS模型可以有效地解决LSTM会在预测中出现的拟合效果差等问题,从而提高整体模型的预测准确率。同时,BLS具有高效的优点,仅BLS模型的预测运行时间不到0.01秒,同时BLS模块对于运行环境的要求相较于其他复杂的神经网络更加宽松,针对数据量不大的碳价数据,正常的笔记本电脑即可进行实现。因此,LSTM-BLS模型同时具备准确率高和运行速度快的优点。
但是,本文仅考虑了基于碳价的历史数据进行预测,并未考虑引入其他影响碳价因素的数据,例如原油价格、欧盟碳价、天然气价格、全球范围内的政策等因素,同时,由于我国是先在地方进行试点,所以关于各个试点和全国碳价之间的联系也应该考虑在内。在后续工作中,会考虑多因素的深宽网络模型结果的碳价预测,从而提供更准确的预测数据。