1. 引言
文本分类问题是数据挖掘最重要的任务之一。现有的文本分类任务通常遵循一个通用的框架:从训练样本学习一个模型,然后利用该模型预测新的实例。现有的框架依赖以下假设:训练数据标签必须全部进行标注,并且训练标签集合必须覆盖被预测的实例类别。但是在实际应用中,我们经常会收集到这一类型的数据:只有有标注的正例样本,而其余剩下的大量样本数据均为未标注数据。这类问题被称为PU分类 [1] 问题。目前已经有许多国内外学者对PU分类问题进行了研究,提出一系列新的分类方法。主要可概括为两类:1) 仅使用训练集中的正例,完全忽略未标注数据集。这类方法又称之为单类分类方法 [2] [3] ,这类方法的核心思想是构造一个近似覆盖训练集的最小区域,而位于区域之外的实例都属于反类。2) 使用正例与未标注数据集中的部分样例来构建最终的分类器 [4] [5] [6] [7] 。这类方法的核心思想是利用正例样本识别未标注样本中的可信度较高的反例样本,然后基于正例样本与反例样本迭代使用EM算法或者SVM算法建立最终的分类器。
Hu等人 [8] 提出一种可以评估未标注数据中数据分布的算法Auto-KL,其核心思想是先利用当前分类任务所提供的数据样本生成不同数据分布比例的模拟数据,然后根据模拟数据训练数据分布评估分类模型,最后根据当前数据进行数据分布估计。从而保证从未标注数据中抽取的足够多的有用信息,同时也尽量避免抽取到错误信息。但是剩余的未标注数据中仍有大量数据未被利用,从而使训练出来的分类器泛化能力不强。
针对上述问题,本文提出了在Auto-KL算法的基础上改进提出了一种数据分布估计下基于相似度的PU文本分类算法Auto-KLBS (Auto-KL Based Similarity)。首先通过评估样本中数据分布情况,采用集成机制从未标注样本中抽取出合适比例可靠反例数据,其次利用相似度抽取有代表性的正例微簇和反例微簇,在获取足量的正反例样本后,将PU问题转换为二元分类问题。数值实验表明方法的有效性。
2. 研究现状
近年来,国内外学者针对PU分类问题取得了一系列的成果,其中根据对未标注数据集的使用情况可以概括以下2类方法。
1) 忽略未标注数据集,例如Tax等人 [2] 提出的SVDD方法,Mabevtz等人 [3] 提出了一种单类SVM [6] 方法用于文本分类中。这类方法由于完全忽略了未标注数据集,从而丢失了未标注数据集中隐藏的有用信息,例如未标注数据集中存在可靠的反例样本时,忽略这类信息极易出现过拟合的现象。
2) 利用未标注数据集中有效信息增强训练模型。针对第1类方法的不足,显而易见的方法是考虑将无标签数据加入到训练集中,利用已有的正例样本和加入无标签数据中的知识可以训练获得到更有效的分类器。考虑从无标注数据中提取反例数据,结合已有的正例样本可以训练一个标准的二元分类器。Yu等人 [4] 提出了PEBL算法来解决PU分类问题,它首先利用1-DNF [4] 技术来识别未标注数据中的反例数据,然后利用SVM算法训练分类模型。Liu等人 [1] 提出S-EM算法,利用Spy [1] 技术识别未标注数据中的可信度较高的反例数据,然后使用EM算法来进行训练模型。Li等人 [5] 将传统的PU问题应用到流式数据环境下,提出了一种基于聚类的PU学习算法。Xiao等人 [6] 提出了一种基于相似度的PU学习算法,首先利用正例样本提取未标注样本数据集中可信度较高的反例样本,然后基于正例样本与提取的反例样本,计算剩余未标注样本分属正例与反例的概率,基于以上数据建立带有概率权重的SVM分类器。Ren等人 [7] 提出了一种基于相似度PU学习算法应用于虚假评论识别领域。但是由于未标注样本正反例样本分布未知,最终分类器效果也会受到抽取反例参数的影响。
3. 数据分布估计下基于相似度的PU文本分方法
3.1. 问题定义及符号标注
给定一个训练集P,P中只含有正例样本,不含有任何反例样本,训练集P中标签集合为
;未标注数据集U中则同时含有正例样本和反例样本,即存在样
,
;我们的任务就是在训练集
上构建一个分类器
;
,其中P和U是分类器
的输入,
是分类器
的输出。算法主要分为四个步骤:1) 对仅含有正例和未标注
数据抽取可信正反例样本;2) 计算代表性样例;3) 确定U中剩余样例(称为间谍样本)的类别标签;4) 建立最终分类器。
3.2. 抽取可信正反例
由于数据集中只包含正例和未标注数据,使得传统算法失效。因此,算法的首先要解决的问题是从未标注数据中提取一些可信的反例,Yu等人 [4] 提出PEBL的方法中采用1-DNF技术去识别未标注数据中的反例数据,由于1-DNF技术基于正例样本特征来识别反例数据,因此在正例数据较少的情况下,识别反例数据的效果较差。Liu等人 [5] 提出了Spy技术的来识别反例数据,这方法对初始阈值十分敏感,所提取的反例数据可信度不高。Sha等人 [10] 提出基于最大熵的方法来识别反例数据。许等人 [11] 提出了基于KL距离的反例识别方法用于不平衡的PU分类问题中。Hu等人 [12] 通过大量实验证明了在未标注数据分布未知情况下,采用不同的方法来抽取未标注数据中的反例数据,以及从未标注数据中抽取反例数据的数量,都会影响到最终的分类模型性能。本文选取了Auto-KL算法 [9] 来提取反例数据,该算法通过评估未标注数据分布,自适应抽取反例数据,有效降低反例提取数目这一参数的敏感性。在得到未标注中反例数据比例后,将Spy和Rocchio两种识别反例的方法集成,从未标注数据中自适应抽取合适数量的正负例数据。记正例数据集合为RP中,负例数据集合记为RN中。抽取完正负例数据后,未标注数据集U中剩下的样例,称为间谍样例,记为数据集合US。
3.3. 计算代表性正负例原型
第一步中获得可信反例集合RN与可信正例集合RP,加上训练集中原本已有的少量正例数据集合P合并成新的训练样本,在此基础上即可初步训练一个分类器,但是,该分类器的泛化性能不高,主要原因是未标注数据集U中仍有大量有用的数据样例未被充分利用,即间谍样例集合US仍然包含大量有用信息,这些样本信息可进一步提升分类器的性能,为了进一步将间谍样例加入到训练数据中,首先需要确定间谍样例的类别标签,这里我们首先需要计算出代表性正负例原型,这里使用经典的K-means算法对可信反例RN进行聚类,即RN聚类为RN1,RN2,…,RNm,其中
,根据文献 [5] [6] ,m设置为10,最后使用Rocchio分类器 [8] 分别为正例和反例计算出10个代表性样例,如算法1所示:
算法1:计算代表性样例原型算法。
1) 输入:P和RN
2) 输出:
和
,
。
3) 将RN聚类成10个子类:
;
4) FOR
DO
5)
;
6)
;
7) END FOR
算法1中:步骤2)中每个样例使用TFIDF [13] 这一特征权值的计算方法建立向量空间模型
,
和
分别代表正例和负例的代表性样例原型,根据文献 [5] [6] ,α和β分别设置为16和4。
3.4. 确定间谍样例的类别标签
为了进一步扩充训练样本,我们必须正确计算方法剩余未标注数据US(即间谍样例)的类别标签。将US中类别标签为正例的样例数据记为LP,将US中类别标签为负例的样例数据记为LN。从而整个间谍样本集合
,这里我们利用算法1分别为正例和反例建立10个代表性样例原型,来估计US中每个间谍样例的类别标签。US中标注为正例的间谍样例记为LP,US中反例的间谍样例记为LN。由于算法2中采用的Rocchio算法已经可以初步的分离出正例数据和负例数据。但是正例数据与负例数据的决策边界不一定是线性的,Rocchio作为一个线性分类器会出现分类错误,从而导致间谍样例发生错误标注,进而影响最终的PU分类模型的性能。因此简单计算每个间谍样例同代表性样例的相似度来确定其类别标签将导致一定的错误。本文提使用K-means对间谍样例聚类,即US聚类为NS1,NS2,…,NSm,
其中
,根据文献 [5] [6] ,n设置为30,然后使用了基于样例局部相似度和样例全局相似度这两种方法来评估间谍样例类别,减低标注误差。
3.4.1. 样例局部相似性
样例的局部相似性的基本思想是相同微簇中的样例应有很高类别相同,算法2展示了样例局部相似性,对于US的每个微簇,首先对微簇中的每个样例与算法1中产生的正负代表性样例做正弦相似度计算,将最相似代表性样例的类别标签作为每个样例的临时类别标签,最后通过投票机制决定整个微簇的类别标签。微簇的类别标签作为微簇中每个样例的最终类别标签。
算法2:样例局部相似性的计算算法(Auto-KLBSL)。
输入:
;
输出:
和
。
1)
;
2) FOR每个样例
DO
3) IF
4) THEN pos_vote++;
5) ELSE neg_vote++;
6) END IF
7) END FOR
8) IF pos_vote > neg_vote
9) THE
;
10) ELSE
;
11) END IF
算法2中,
(1)
算法2通过确定微簇的类别标签来确定其内部每个样例的类别标签,该算法考虑微簇中每个样例同正反例代表性样例的相似度,基于投票机制确定微簇的类别标签。但当微簇中正反例样本比例接近时,基于样例局部相似性通过投票机制判别微簇的类别标签,会发生错误标注,从而会导致训练出来的分类模型性能较差。图1所示,间谍样本通过K-means算法的部分聚类结果。
根据算法2,可以发现微簇Micro-C1与微簇Micro-C2很容易确定其子类标签,分别为正例和反例。但是对于微簇Micro-C4,由于其内部正反样例的数目十分接近,若基于算法3来确定子类类别标签会产生一定错误。
3.4.2. 样例全局相似性
样例全局相似性基本思想是:充分考虑US中每个样例同全体正反例代表性样例间的相似度,并忽略样例所在的微簇间的关系。对于每个间谍样例同全体的代表性样例进行相似度计算,求出该样例属于正例和反例的类别概率,如公式2、3所示。选择概率最大的类别作为样例的类别标签。
算法3:样例全局相似性的计算算法(Auto-KLBSG)。
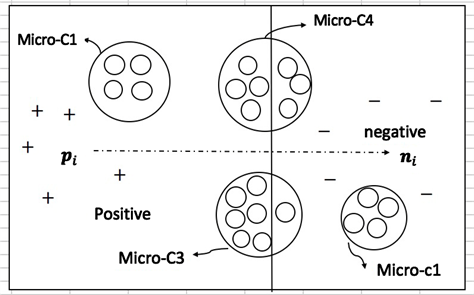
Figure 1. Local similarity of the sample
图1. 样例的局部相似性
输入:
;
输出:
和
。
1)
;
2) FOR每个样例
DO
3) IF proba_positive(e) > proba_negative(e)
4) THE
;
5) ELSE
;
6) END IF
7) END FOR
算法3中,
(2)
(3)
算法3通过计算间谍样例与全体代表性样例的相似度,直接判别样例的类别标签,忽略间谍样例所在微簇的类别标签,在微簇中正反例比例接近的情况下,可有效避免样例标签被错误标注。
3.5. 建立最终的分类器
将已有的正例数据集合P和算法第二步提取的可信正例数据集合RP与可信反例数据集合RN,以及算法第三步提取的间谍样本中的正例数据集合LP,反例数据集合LN,组成最终的训练数据。即可训练最终的SVM分类器。但是考虑到传统的SVM算法采用一个核函数,不足以解决样本数据含有异构信息,或者数据高维特征空间分布不平坦时情况。本文使用多核SVM算法来进行训练最终的分类器,进一步提升分类器的性能。
多核学习 [14] [15] [16] 利用多个核函数将输入空间变换为高维特征空间,转化为凸优化问题。文献论述 [14] [15] [16] 已经证明了多核学习能获得比单核模型更好的性能。在本文提出的PU框架下,分别使用多核学习算法SimpleMKL [16] 进行实验,建立最终分类器算法如下:
算法4:建立最终分类器
输入:P,RN,LP和LN;
输出:分类器FSimpleMKL
1)
;
2)
;
3) 使用SimpleMKL在P+N,训练最终分类器FSimpleMKL。
4. 数据分布估计下基于相似度的PU文本分类方法
4.1. 实验与分析
4.1.1. 实验设置
针对文本实验数据,Auto-KLBS主要跟性能比较好的Spy-SVM [1] ,Roc-EM [8] ,LELC [5] ,AutoKL [12] 共4种方法相比较,全部实验运行在2.50 GHz的处理器和4 GB的内存台式机上。
为了能更好地比较不同分类方法的优劣,根据文献 [6] ,使用评估分类算法性能的F-score作为分类器的评价指标,其定义如下:
,其中p和r分别为正确率(precision)和召回率(recall)。F-score同时考虑了查准率和查全率。只有当正确率与召回率越大,F-score值也越大。F-score越接近于1,这证明该算法分类效果越好。
在实验中,使用两个真实文本数据集20-NewsGroup和Reuters corpus (表1)。
对于20Newsgroups数据,首先,根据文献 [11] 从中选择了4个计算机相关主题以及2个科学相关主题,比如:{comp.graphics, comp.ibm.hardware, comp.mac.hardware, comp.windows.x} × {camsci.crypt, sci.space},共
组数据。从中选出一组数据作为正例数据,我们把剩余数据的所有数据都作为反例加入到无标注集中。在Reuters corpus数据上进行同样的处理,选取的主题组合为{acq-crude, acq-earn, crude-interest, crude-eam,earn-interest, interest-acq}。以graphics × sci.crpypt为例,从中随机选主题相同的文本作为相应的正例样本,其余部分作为未标注数据中的正例数据。然后从剩余18个主题中随机抽取作为反例数据放进未标注数据U中,其数量为
,
为比例参数,首先设置
,然后在
递增的条件下,
依次实验,验证算法的有效性。
4.1.2. 特征提取
在构造完PU文本数据后,我们对文本数据建立向量空间模型。特征选择是文本分类任务中极为重要的一个环节,它能有效剔除冗余特征和无效特征,从而达到特征降维的效果,从而可以提升整个分类模型的分类效果。本文中使用TF-IDF [13] 对数据集建立的向量空间模型。在剔除停用词后,选取每个主题下TF-IDF值最高的150个单词作为该主题的特征代表词。对多个主题合并为一个正例的时候,对主题特征空间进行并集操作。
4.1.3. 实验结果与分析
对于生成的实验数据,本文采取无放回抽样随机选取60%的实例数据作为训练数据,剩余的则作为测试数据,进行10折交叉验证。为了避免采样误差,对上述过程重复10次,然后计算平均的F-score,实验中
是未标注数据中反例数据所占比例。例如
表示未标注数据中含有10%的反例。表2显示了6组子数据下实验的F-score。
注:URL1:http://www.daviddlewis.com/resources/testcollections/;URL2:http://people.csail.mit.edu/jrennie/20Newsgroups/。

Table 2. 6 sets of sub-datasets on each algorithm F-score
表2. 6组子数据集上各算法F-score
鉴于本文篇幅限制,如表2所示,选取了本文提出的Auto-KLBSL (样例局部相似性)和Auto-KLBSG (样例全局相似性)在6个子数据集上有5个子数据集上效果优其他对比算法。这是因为我们的Auto-KLBS方法首先利用Auto-KL算法评估了未标注数据中的正反例数据分布比例,提取合适的可信正反例,降低了分类器对反例提取数目的参数敏感性,同时利用相似度方法对剩余的大量未标注样例进行标签评估,进一步扩充了训练数据集,相对于单核SVM,使用多核学习构建了更高性能的分类器。对比PU-BSDS两种不同采取两种不同的样例相似度计算策略,Auto-KLBSG (样例全局相似性)通常在子数据集上的分类效果要比Auto-KLBSL (样例局部相似性)的分类效果好,这是因为前者基于样例所在子类的局部关系,但当子类中正反例样本比例接近时,基于投票机制会出现类标签错误标注,后者计算样例与全体代表性样例的相似度,直接判别样例的类别标签,忽略间谍样例所在子类的类别标签,在子类中正反例比例接近的情况下,可有效避免样例标签被错误标注。
图1,图2分别展示了随着α增大,在两组20-NewsGroup和Reuters corpus数据上各算法的实验结果。
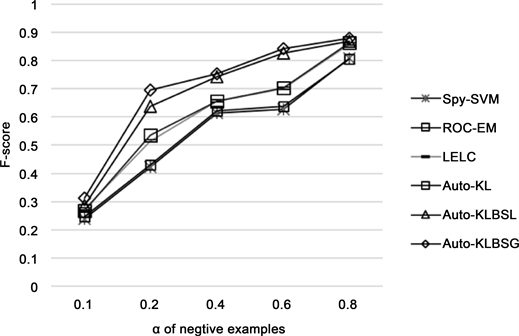
Figure 2. Classification performance comparison on 20-Newsgroup
图2. 20-Newsgroup上分类性能比较
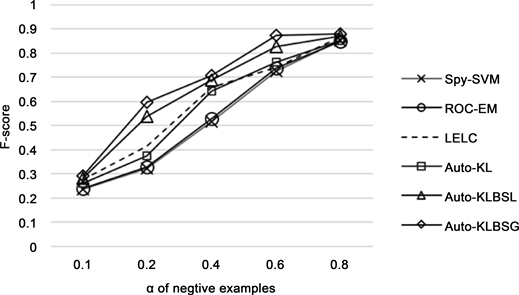
Figure 3. Classification performance comparison on Reuters corpus
图3. Reuters corpus上分类性能比较
如图2,图3所示随着α增大,即未标注数据中反例样本比例增加,各个算法F-score均有所提高,即未标注数据中反例样本比例增加,各个算法的F-score均有所提高,这是因为随着未标注数据中反例样本增加,通过反例提取算法从未标注数据中收集的反例数据也随之增加,最终构建的训练集的有用信息 也更加丰富,所以从训练集学习的模型性能也越强,从而相应的分类效果越好。同时可以明显观察到在同一 值下,本文提出的两种算法均优于其他几种对比算法。
5. 数据分布估计下基于相似度的PU文本分类方法
本文提出了一种数据分布估计下基于相似度的PU学习方法,首先利用数据分布评估算法估计未标注数据中正反例数据的分布比例,并利用集成机制从未标注数据提取可靠负例样本,对于剩余仍存在的间谍样本利用两种相似度策略,提取正负微簇,从而极大的丰富了训练集,最后利用多核学习训练分类器。数值实验证明了本文所提方法的有效性。未来考虑将本文方法拓展到流式数据环境中。
基金项目
国家自然科学基金:(61503112);国家重点基础研究发展计划(973)项目(2016YFC0801406)。