1. 引言
1.1. 项目开发背景
通过极光大数据可得,截止2017年8月,在线教育app市场规模达到2.76亿,行业整体渗透率为29.3%,而随着国人自我增值需求的不断加强,这个市场仍然有巨大的发展潜力。根据极光大数据统计,截至2017年8月最后一周,渗透率top3的综合教育类app分别是网易公开课、腾讯课堂和中国大学MOOC,其市场渗透率分别为0.46%、0.30%和0.20% [1] 。这些综合类教育app仅提供网课平台学习服务,大多与高校教学脱节。
与此同时,根据腾讯2018年一季报数据,微信及WeChat合并MAU达到10.4亿,超过2017年底我国7.53亿的手机网民规模,微信已实现对国内移动互联网用户的大面积覆盖。2017年微信登录人数已达9.02亿,较2016年增长17%,日均发送微信次数为380亿,微信已成为全民级移动通讯工具。微信已成为国内最大的移动流量平台之一。根据智研咨询集团提供的微信小程序2017年12月Top200的行业分布,教育占比仅有1%,且多为工具性质 [2] 。
1.2. 项目开发内容及目的
根据综合类教育app的现状和微信便捷高效的特点,本团队使用微信开发者平台,设计并开发了一款以提供一体化教学服务为目标的教学辅助平台。该平台不仅可以为学生提供与高校紧密结合的教学服务,高校教师还可以通过此平台上传相关教学课程,学生还可以根据自身需求利用此平台进行网课学习。此外,通过基于用户的协同过滤算法,本项目还为平台设计并训练了一个推荐系统,能够根据学生的行为信息为学生个性化推荐课程,充分实现了学生的个性化教育。该系统还可以统计在校学生和教师的各种数据,为高校的教育提供准确、及时的学生信息,同时也为高校对学生的教育提供引导信息。
2. 系统分析与设计
2.1. 系统功能设计
基于微信的智能网课学习平台为不同用户提供不同的入口。管理员通过后台管理端进行学习平台信息管理,教师通过教师端进行教学管理,学生通过学生端进行课程学习。具体功能模块如图1所示。
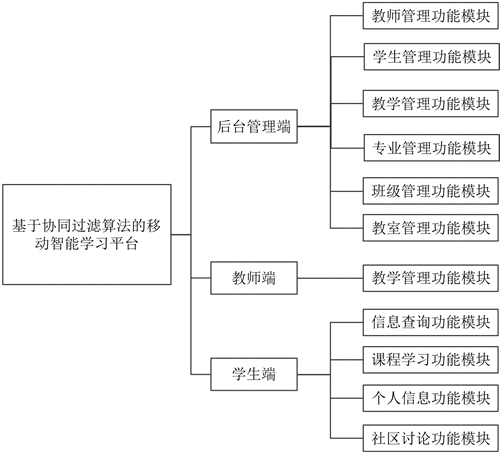
Figure 1. The functional module diagram of system [3]
图1. 系统功能模块图 [3]
2.2. 系统架构
系统有由三个子系统组成。分别为后台子系统,课程推荐子系统,用户客户端子系统。
用户通过用户客户端子系统发出请求数据,后台子系统处理请求数据并返回用户想要的数据,并通过多样的形式将数据呈现在浏览器或微信小程序上。随着用户访问该平台次数的增加,产生的用户日志也随之增加。课程推荐子系统会在线下根据用户日志分析用户行为信息,计算用户的课程推荐列表,并将用户的课程推荐列表数据传输到后台子系统,后台子系统对推荐列表数据进一步处理后呈现到用户客户端。
1) 后台子系统
后台子系统从下往上依次由底层数据库,数据模型层,数据访问层,业务逻辑层,控制层组成。数据库负责存储数据;数据模型层实现对象关系映射(ORM);数据访问层对数据库进行增删改查;业务逻辑层处理应用的业务逻辑和业务校验;控制层处理用户请求数据,实现业务功能。
后台子系统为用户和后台数据库的交互提供支持,从而为不同用户提供不同的功能和服务。同时记录用户的行为信息并生成用户日志。
2) 课程推荐子系统
课程推荐子系统由应用层,云平台计算层,终端感知层组成。
根据后台子系统提供的用户日志,课程推荐子系统对用户行为信息进行预处理,在终端感知层量化用户行为信息;在云平台计算层运用协同过滤算法得出推荐列表;在应用层预测用户行为,优化推荐列表。为用户推荐个性化课程。
3) 用户客户端子系统
分别采用B/S架构实现后台管理。管理员使用浏览器登陆后台管理网站完成各项后台管理操作。采用C/S架构为教师和学生提供界面交互和平台服务。教师和学生使用微信小程序,通过授权访问学习平台。
系统架构图如图2所示:
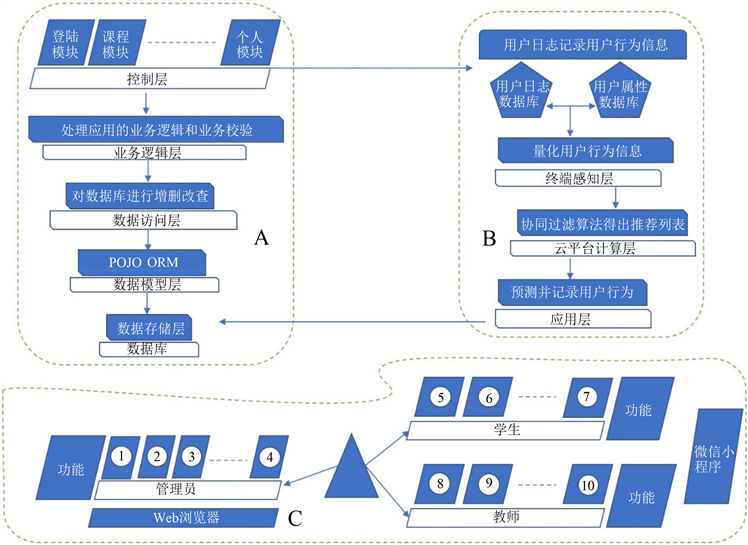
Figure 2. System architecture diagram [4]
图2. 系统架构图 [4]
图2中字母A代表后台子系统;字母B代表课程推荐子系统;字母C代表用户客户端子系统;数字1代表学生管理;数字2代表教师管理;数字3代表教学管理;数字4代表权限管理;数字5代表个人信息;数字6代表课程学习;数字7代表信息查询;数字8代表回答问题;数字9代表发布通知;数字10代表学生考勤。
2.3. 数据流图
数据流程是数据在系统中产生、传输、加工处理、使用、存储的过程 [5] 。
数据流程分析即是系统功能模块详细设计的基础,也是数据库设计的基础。开发者可以通过分析数据流明确数据传输和处理过程。该系统的数据流图分为顶层,一层和二层。顶层数据流图如图3所示 [6] 。
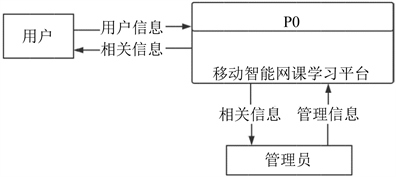
Figure 3. Top-level data flow diagram [7]
图3. 顶层数据流图 [7]
将处理P0展开,得到第一层数据流图如图4所示。
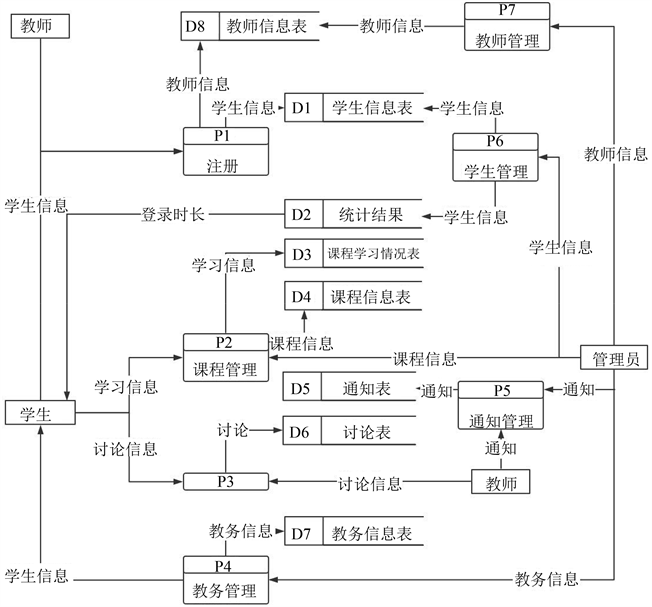
Figure 4. First-level data flow diagram [7]
图4. 第一层数据流图 [7]
二层以P5为例,将P5展开得到二层数据流图,如图5所示。
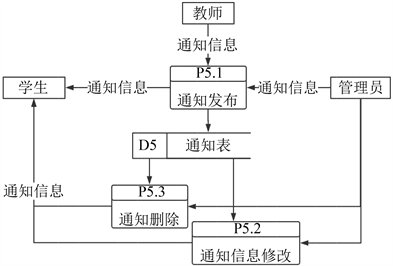
Figure 5. Second-level data flow diagram [7]
图5. P5展开数据流图 [7]
3. 系统数据库设计
3.1. 数据库概念设计
数据库是一个系统的基础,是系统数据的源头,所以系统数据库的设计至关重要。通过需求分析得出,学生,教师,课程,专业,学院,通知等实体以及对应属性。根据实体之间的依赖关系,设计系统概念模型,遵循了完整性约束,三范式原则 [6] 。系统E-R图如图6所示。
3.2. 数据库逻辑结构设计
根据概念模型E-R图对数据库实现具体表的详细设计 [8] 。
以用户信息表为例。用户信息表保存了用户的基本信息,包括其所在学校信息和作为微信用户的信息,并标记用户身份类型(学生,教师,管理员)。
字段名,数据类型,数据长度等详细信息见表1。

Table 1. The information of user table
表1. 用户信息表
4. 系统开发
4.1. 系统开发环境
基于协同过滤算法的移动智能学习平台的开发环境为Windows10,64位操作系统。软件使用IDEA集成环境和微信小程序开发平台。开发语言为Java、JavaScript,CSS。MySQL5.7.19作为后台数据库,使用InnoDB存储引擎。
4.2. 开发技术
4.2.1. 客户端技术方案
微信小程序开发使用官方MINA框架编写,前端程序自主开发,贴近核心代码。开发过程中,将对于大量相似却不重复的功能样式,独立开发出区块接口,划分出网络通信,数据储存,数据处理等模块 [9] 。模块涵盖多种功能,扩展性强,二次开发性好。文件符合官网文件系统设定,为不同功能区块,相似UI设定开发出相应文件系统。
4.2.2. 服务器技术方案
服务器采用J2EE,该技术用于开发企业级应用。使用基于SpringBoot的SSM开发框架,对后台进行高度封装。由数据存储层,数据模型层,数据访问层,业务逻辑层和控制层组成。数据存储层存放系统的MySql数据库;数据访问层专注于数据库的增删改查操作;业务逻辑层完成业务处理。控制层通过控制器实现前端和后台的数据序列化传输。同时使用redis缓存技术,提高系统性能和效率。
5. 基于用户行为信息相似度的协同过滤算法
基于scikit-surprise的协同过滤算法
SciPy是一个开源的基于Python的科学计算工具包。Scikit-surprise,是基于SciPy针对机器学习推荐系统领域发展出的一个简便的推荐系统引擎。本系统使用了协同过滤算法,在传统的协同过滤算法上,引入了一个随时间变化的模型来刻画用户的评分之间的相似度 [10] 。传统的协同过滤算法,简单来说是利用用户之间的兴趣相投,共同喜好为用户推荐其感兴趣的信息 [11] ,其基本思想是利用用户对各类课程进行评分获得的矩阵,在用户群中寻找高度相似的用户群,然后综合这些用户对同一信息的评价,预测目标用户对此信息的喜好程度 [11] 。协同过滤的实现一般分为两步:首先,获得用户对其所喜好课程的评价信息,再构造评分矩阵,当用户和课程种类的数量都很大时,由于用户通常只对感兴趣的产品进行评分,因此建立的评分矩阵是个巨大的稀疏矩阵Pm * n,见表2。
Table 2. The information of user's course score table
表2. 用户的课程评分表
-代表用户未对此课程进行评分。
表1的一行的数据代表一个用户对不同电影的评分,也标志了该用户的喜好程度。其次为了分析用户的相似性,即通常情况下,口味相近的人往往喜欢的课程也会比较相似,因此要计算用户的相似性,一般会补全评分矩阵来减少误差 [11] 。此处,该课程推荐系统会优先考虑同一个学院的学生进行相似度推荐,然后再痛选了同一门课的学生进行相似度推荐,从而缩小评分矩阵,降低其稀疏程度。并且发现因为用户行为信息在不断变化,根据用户评级,用户对对应课程的评分也会随之变化,提出了KNNBaseline Model。由
表示
(1)
代表此课程的所有已评分用户的平均得分,
是用户的偏置,
是item的偏置。
其中
(2)
(3)
6. 课程推荐系统的实现
6.1. 系统开发思想
在此课程推荐系统中,每当用户对软件进行操作,都将被用户日志信息服务器记录并反馈给数据库。由图1所示,我们将用户的操作分成显式和隐式,分别加以权重,最后的用户评分将由这些合成。对所记录的数据,系统首先对数据进行去噪处理,然后进行矩阵补全,生成特征向量,进而利用KNNBaseline实现离线推荐。
6.2. 算法步骤
步骤1:根据用户行为信息,参考用户行为评级列表,见表3,生成评分矩阵
,获取目标用户
的已评分矩阵
和目标用户
的未评分矩阵
Table 3. The information of user rating table
表3. 用户评级列表
步骤2:分别进行目标用户u与同一学院v作和选了同一门课的同学作皮尔逊相似度计算,使用基线(而不是平均值)计算所有对用户(或项目)之间的皮尔逊相关系数(收缩),收缩参数有助于避免在只有少量额定值可用时过度拟合。
(4)
(5)
步骤3:目标用户与同学院的同学KNNBaseline计算,得到推荐列表L1,
(6)
步骤4:目标用户与选了同一门课的同学进行公式2计算,得到推荐列表L2,
(7)
步骤5:将推荐结果L1与L2取并集按分值从高到低排列,根据已评分矩阵
,排除已评分课程,将分值较高的Top-4作为最终的推荐结果。
7. 实验设计与结果分析
7.1. 实验准备
实验使用来自GroupLens的MovieLens ml-100k数据集,数据集含有来自942名用户对1682部电影的10,000条评分组成。每个用户至少评分20部电影。用户和电影从1号开始连续编号。数据是随机排序的,这些数据分成四个列分别代表用户信息,电影信息,评分和时间。这与该系统的评分要求相类似,电影信息包含了电影的类别,这与课程的类别特征相对应。因此,采集该数据集作为本系统的测试数据。 [11] 。
7.2. 实验结果分析
本实验将用十折交叉验证来验证该数据集的误差。十折交叉验证用来测试算法准确性,是常用的测试方法。将数据集分成十份,其中九份作为训练数据,1份作为测试数据,进行实验。实验结果如图7所示。
7.3. 结果分析
该系统中,推荐结果的准确率采用用户的预测评分值和真实评分值的平均绝对误差和均方根误差来评估,平均绝对误差公式(7)和均方根误差公式(8)如下所示
(8)
(9)
分析其中
表示用户对课程的预测评分,
代表用户对课程的实际评分。进行十折交叉验证。误差如图1所示。
由图可知,该算法能良好预测用户对课程喜好度,并能为该课程推荐系统产生不错的个性化推荐结果。
8. 结语
综上所述,本文提出的基于协同过滤算法的移动智能学习平台,目的是满足现代化高校在教学环节中学生对个性化受教育的需求,提高高校数字化教学水平,实现了高校学生的个性化教育,系统地整合了网课平台和教学管理辅助系统,解决了当前市场教育类微信小程序分类复杂,操作繁琐等特点,具有界面风格清晰大方,用户体验效果良好,操作简单易懂,操作实施方便的功能特点。该系统使高校教育和管理工作更加科学化、规范化,在现实中具有良好的应用前景。