1. 前言
随着现在科技进步,个人电子产品和服务已经普及,从早期PDA、计算机,到现在的智能手机、智能手表、智能眼镜、网络银行和电子钱包等,人们开始仰赖这些产品及服务,相对地个人的隐私权及资料的安全性越来越被重视。身份的验证在信息安全的议题上一直被重视与探讨,林咏章、黄明祥等人 [1] 指出,其类型分为三大类,分别为证件验证、生物特性验证、以及通行密码验证,证件验证及通行密码验证一旦遗失、被他人窃取或冒用将会造成极大的不便与财务的损失,即失去其身份验证的目的。生物特征验证常见的方法有指纹识别、人脸识别、声纹识别、虹膜识别等,生物特征主要有生理结构唯一性,很难找到两个有相同特征的人,因此生物特征常被用来做身份鉴别,其中人脸识别被用于许多的领域,如安全管理、监控系统、多媒体互动等,其具有广泛的应用、研究空间。人脸检测与识别相关的研究在计算机视觉上一直是个相当热门的研究题材,而应用的领域也相当的广泛。至今已有许多学者提出各种方法来进行人脸的检测与识别,以人脸检测而言,目前以Adaboost最广泛用于系统中。一般在开发人脸检测系统时,除了正确率以外,速度也是一个很重要的考虑因素。因此如果利用Adaboost在建置人脸检测器时,如果能用较少量的弱分类器建置而成,对整个系统的运作速度必能有效的提升。而在建置一个Adaboost人脸检测器时,通常是以灰阶影像为输入数据,然后让每一个弱分类器针对这些输入数据的分类能力,逐一去挑选最佳的弱分类器,进而建置出一个强分类器。然而在分类器的训练过程中,输入的影像样本即扮演着一个相当重要的角色,因为良好的影像样本能使系统以较少的弱分类器即建置出效果近似甚至更佳的强分类器,进而建置出人脸检测器。
卷积神经网络(Convolutional Neural Networks,CNN)是人脸识别方面最常用的一类深度学习方法 [2] [3] [4] [5]。深度学习方法的主要优势是可用大量数据来训练,从而学到对训练数据中出现的变化情况稳健的人脸表征。这种方法不需要设计对不同类型的类内差异(比如光照、姿势、面部表情、年龄等)稳健的特定特征,而是可以从训练数据中学到它们。深度学习方法的主要短板是它们需要使用非常大的数据集来训练,而且这些数据集中需要包含足够的变化,从而可以泛化到未曾见过的样本上。幸运的是,一些包含自然人脸图像的大规模人脸数据集已被公开,可被用来训练CNN模型。除了学习判别特征,神经网络还可以降维,并可被训练成分类器或使用度量学习方法。CNN被认为是端到端可训练的系统,无需与任何其它特定方法结合。
在训练过程中,本文采用了CNN所产生的特征映像(Feature Map)来当作人脸检测器的输入数据 [6] [7]。而从实验结果得知,所提出的方法能利用较少量的弱分类器建置出一个检测速度快的人脸检测器。在人脸识别方面,则分别由人脸识别流程与特征空间转换两个面向来降低人脸识别中因姿势、光线以及表情所带来的负面影响。其中,在人脸识别流程方面,提出了三阶段人脸识别流程,第一阶段首先利用小波转换对人脸进行影像前处理,取出低频较不受干扰的区域,接着在第二阶段中将第一阶段的低频影像取出5个部分以及全部人脸,以期利用较不受光线变化影响的区域能提高识别率,而第三阶段则分别将5部分进行特征空间转换,最后,将5个人脸识别结果以加权方式加总得到最终识别结果。而在特征空间转换部分,本文中提出了最近特征空间转换,最近特征空间转换法是以点到点、点到线、点到面等最近距离的向量作为共变异数计算的基础,其所构成的共变异数矩阵具有较佳的特征空间,即特征空间较传统点到点所求得的特征空间让投影到其中的样本点更具有一般性与代表性。
2. 两阶段串联式人脸检测器
由于良好的训练样本往往能让训练出来人脸检测器有较好的检测效果,但在现实环境中对一个即将面对训练或检测的影像却未必总是如此理想,当被部署在无约束条件的环境中时,由于人脸图像在现实世界中的呈现具有高度的可变性(这类人脸图像通常被称为自然人脸,所以人脸识别也是最有挑战性的生物识别方法之一。人脸图像可变的地方包括头部姿势、年龄、遮挡、光照条件和人脸表情。图1给出了这些情况的示例,也因此许多学者提出各种不同的前处理,来将这些影像所受到的噪声干扰及位置变化的影响减低 [8] [9] [10] [11]。
然而在一般的状况下,影像所受到的干扰种类通常是未知的,因此系统在做检测时,也很难决定该使用何种前处理来尽量将影像的噪声及光影干扰降低。所以与其将这些干扰因素降低的高度不确定性,也有学者就直接将较明确的影像特征直接强化出来,以利于人脸检测器的训练,但这仍然存在一个问题,对于一个想要检测的人脸来说,很难决定出哪些是有利于一个检测器做分类的特征。因此这里采用学习的机制,让训练程序能从所搜集的训练样本自行强化出有利于人脸检测器做分类的特征,而其中Garcia提出以CNN做人脸检测中的特征映像即扮演此角色。因此CNN在本系统中也被拿来针对影像做特征的强化及撷取,而其中FMc和FMs分别为CNN经过Convolution和Maxpooling运算后的结果,如图2所示。
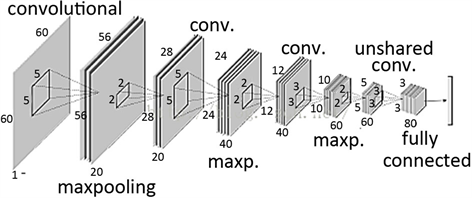
Figure 2. Process of convolutional neural networks
图2. CNN架构
人脸识别技术这些年已经发生了重大的变化,传统方法依赖于人工设计的特征(比如边和纹理描述量)与机器学习技术(比如主成分分析、线性判别分析或支持向量机)的组合。人工设计在无约束环境中对不同变化情况稳健的特征是很困难的,这使得过去的研究者侧重研究针对每种变化类型的专用方法,比如能应对不同年龄的方法、能应对不同姿势的方法、能应对不同光照条件的方法等。近段时间,传统的人脸识别方法已经被基于卷积神经网络(CNN)的深度学习方法接替。深度学习方法的主要优势是它们可用非常大型的数据集进行训练,从而学习到表征这些数据的最佳特征。网络上可用的大量自然人脸图像已让研究者可收集到大规模的人脸数据集,这些图像包含了真实世界中的各种变化情况。使用这些数据集训练的基于CNN的人脸识别方法已经实现了非常高的准确度,因为它们能够学到人脸图像中稳健的特征,从而能够应对在训练过程中使用的人脸图像所呈现出的真实世界变化情况。此外,深度学习方法在计算机视觉方面的不断普及也在加速人脸识别研究的发展,因为CNN也正被用于解决许多其它计算机视觉任务,比如目标检测和识别、分割、光学字符识别、面部表情分析、年龄估计等 [12] [13] [14] [15] [16]。
人脸识别系统通常由以下构建模块组成:
1) 人脸检测。人脸检测器用于寻找图像中人脸的位置,如果有人脸,就返回包含每张人脸的边界框的坐标。如图3(a)所示。
2) 人脸对齐。人脸对齐的目标是使用一组位于图像中固定位置的参考点来缩放和裁剪人脸图像。这个过程通常需要使用一个特征点检测器来寻找一组人脸特征点,在简单的2维对齐情况中,即为寻找最适合参考点的最佳仿射变换。图3(b)和图3(c)展示了两张使用了同一组参考点对齐后的人脸图像。更复杂的3D对齐算法还能实现人脸正面化,即将人脸的姿势调整到正面向前。
3) 人脸表征。在人脸表征阶段,人脸图像的像素值会被转换成紧凑且可判别的特征向量,这也被称为模板(template)。理想情况下,同一个主体的所有人脸都应该映像到相似的特征向量。
4) 人脸匹配。在人脸匹配构建模块中,两个模板会进行比较,从而得到一个相似度分数,该分数给出了两者属于同一个主体的可能性。
 (a) 人脸检测器找到的边界框
(a) 人脸检测器找到的边界框  (b)和(c)对齐后的人脸和参考点
(b)和(c)对齐后的人脸和参考点
Figure 3. Face recognition and alignment
图3. 人脸识别和对齐
虽然CNN可以训练出一个有效的人脸检测器,但是由于它的架构往往过于庞大以至于难以去实现,且需要相当大量的运算在一张影像去做人脸检测,以至于降低检测的速度。而为了让检测速度能有效的提升,Viola P(2014)提出了层级式过滤(Cascade Classifier),是由数个AdaBoost算法训练出的多个强分类器所串联而成,主要被设计用来快速并过滤掉大量的非人脸区域的分类器,如图4所示。而此系统为了能在各个不同位置快速地检测各种不同大小的人脸,并提出了积分影像(Integral Image)来快速计算每个类小波(Haar-Like)特征的值。虽然Cascade Classifier能快速且有效地检测到人脸,但它需要的训练时间往往随着大量的训练样本及特征数而急速增长。因此Wu.J(2018)提出了另一个更快速的特征选取算法(Forward Feature Selection, FFS)来解决上述的问题。即结合了CNN能撷取影像特征与Cascade Classifier快速分类(图5)的优点,提出了以由简至繁(Coarse to-Fine)为基础的人脸检测器,并以FFS当作训练算法,以提升人脸的检测效果并降低分类器的训练时间,其系统架构如图6所示。
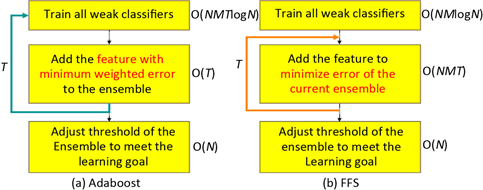
Figure 4. The comparison of Adaboost and FFS
图4. Adaboost和FFS比较
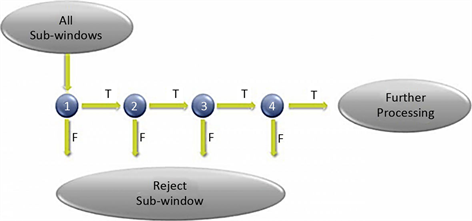
Figure 5. Cascade classifier cascade classifier
图5. Cascade classifier级联分类器
通常在做人脸检测时,所感兴趣的人脸在一张影像中所占的区域并不会太大,所以一开始使用分类能力虽较弱但指令周期快的Coarse-Level分类器来过滤掉大量的非人脸区块。而由于使用的Haar-Like 特征很容易受输入影像维度的增加而大幅上升,以至于Cascade Classifier的训练会相当地耗时。因此将维度较小的特征映像FMs设为Coarse-Level Cascade Classifier的输入,以利于整个检测系统快速地建置及检测。接下来再用以原影像为输入且分类能力更强的Fine-Level分类器做最后的过滤,最后再用群聚算法(Clustering Algorithm)群聚剩下的检测结果并删除掉反应点较少的人脸,以得到最后的结果。
3. 三阶段人脸识别方法
3.1. 三阶段人脸识别架构
本文提出一人脸识别系统架构如图7所示,其目的是希望降低光线及表情等变化所带来的影响。在步骤一中,利用离散小波转换(Discrete wavelet transform, DWT)将高维影像降维,低频中的低频(Low band of Low band, LL)能够保留原影像中不变的特征。而为了降低光线变化的影响,抽取具有一致性光线的区域特征,可以藉由将LL影像等分为4个区块达成此目的,分别是左半脸(L)、右半脸(R)、上半脸(T)以及下半脸(B),此4部分个别表示区域特征以及独立的特征空间。
此外,再对LL影像进行一次DWT转换,同样取其低频影像为一全脸影像(F),此作法希望能兼顾局部区域不变性,以降低光线因素带来的冲击,同时又能顾及整体人脸影像全貌。取得此5个基于能量转换所得到的部分脸以及全脸影像用以加强数据的鉴别力。在步骤二中,将子空间转换方法应用在5个取出的训练影像中以取得五个独立的特征空间,接下来在步骤三中则是以最邻近特征线方法来识别测试影像的结果。由于5个特征空间分别有5种距离结果,因此,以加权方式将5种距离结果合并,以决定最后的结果。
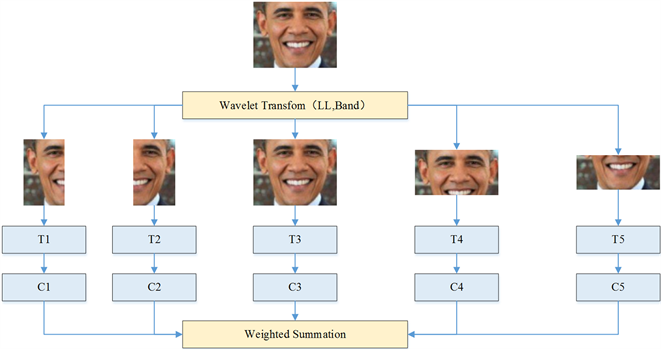
Figure 7. Three stage face recognition framework proposed
图7. 提出三阶段人脸识别架构
3.2. 最近特征空间转换法
在本文中,针对三阶段人脸识别架构中最重要的空间转换提出一个新的算法,此空间转换法的想法是将最近特征空间转换(Nearest Feature Line, NFL)分类器应用到空间转换中。由于NFL已经在先前研究中证明其分类效果远优于传统的最近邻居法(Nearest Neighbor, NN),然而,它的缺点为需要大量的比对时间,因此本文计划NFL的概念应用至空间转换之中,把NFL的优点应用在空间转换上,让数据比点时仍使用原有的NN,因此不仅能够把NFL的优点保留下来,又能够把比对时间降低为NN的比对时间。本模块的系统流程如图8所示:

Figure 8. Flow chart of nearest feature line transformation
图8. 最近特征空间转换流程图
本文整合特征空间转换与NFL分类器技术,于人脸识别器架构中的特征空间转换法进行改善,采用将NFL融入Laplacian Matrix算法中的策略,提出一改良型的人脸特征空间转换架构,如图9示意图所示,主要是从点到线的距离衡量方式取代传统点到点的衡量方式进行特征空间转换;传统Laplacian Matrix Projection在进行特征空间转换时,转换矩阵通常是由衡量点到点的向量所构成,本计划则是将NFL的概念融入Laplacian Matrix中,采用的是以点到其它任意两点配对的直线所形成的向量组成转换矩阵;而此一新的转换矩阵亦可以用Laplacian Matrix表示,因此不仅可以将样本在原空间的拓朴信息保留,更可进一步将样本在原空间中的线性变化关系保留。在特征空间转换的训练过程中,可进一步选择采用点到点、点到线、点到面抑或点到高维空间的向量以决定所要的特征空间转换矩阵,并仅需以参数便可以完成不同策略的训练过程,而在分类比对阶段中,只需在该特征空间中以传统的NN方法进行比对即可。
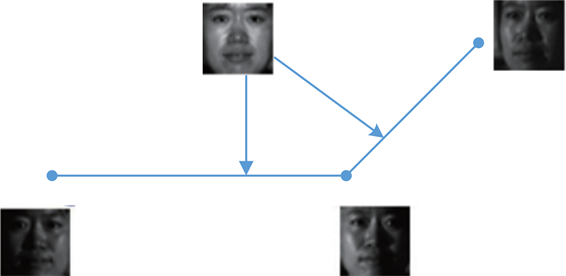
Figure 9. Strategy nearest feature line
图9. 特征空间转换策略
在详细的建置过程中,假设共有N个样本点,首先在特征空间中考虑某一特定的样本点
,而点到特征空间上的距离可定义为
,其中fp是一由p个样本所构成的特征子空间(例如p = 2时,即为线),而
则是
在该特征子空间上的投影点,则对
来说总共有
个配对可以进行投影。而点到特征子空间上投影所形成的向量即可以用来计算散布矩阵(Scatter Matrix),此种计算Scatter Matrix的方式,称之为NFS Embedding,接着可以建立两种目标函式如下:
(1)
其中权重值
可以用来表示点到特征子空间上投影点之间的连结状况,1表示将该向量纳入计算,而0则表示不将该向量纳入计算。其中式1表示所有的点与其相对应的投影点所形成的向量相加以后平方,而式2表示所有的点与其相对应的投影点所形成的向量平方以后相加。当P = 1时,式1即为区域线性嵌入(Locally Linear Embedding)的目标函式,而式2即为区域保留投影(LPP)的目标函式。为简化表示,权重值
可进一步以一个N by NP的矩阵表示,例如当P = 2时,
可以找到
个点到线的投影向量,而权重
与
是不相同的,而
,
与
不存在。接着以P=2时为例推导最近特征空间转换法以Laplacian通式表示。首先投影点 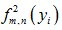 可以表示为点
与
的线性组合表示为:
可以表示为点
与
的线性组合表示为:
(2)
其中
且
。而从线
到点
的向量可以表示如下:
(3)
,若从
条线中挑选出K个最近特征线则目标函数(1)可以表示如下:
(4)
其中:
(5)
(6)
其中
且
。另一方面,将目标函数F2分解成K个元素,其中每一个元素代表点到第K个最近特征线的距离平方,例如第一个元素矩阵
,代表点
到最近特征线
,
,
,的关系。其中
且
,因此目标函数F2可以表示如下:
(7)
以Laplacian Matrix表示点到Feature Space后,就可以进一步得到衡量区别信息的Scatter Matrix,并得到最后的特征空间转换矩阵,而本模块的重点为找出一个一般化的通式,此通式能将Laplacian Matrix以及LLE中最重要的权重矩阵M以及W中的权重值以所宣称的点到点、点到线、点到面以及点到空间的形式来表现,换句话说,本模块主要是提出一个通式,此通式能求出Laplacian Matrix以及LLE中M以及W的权重值,而此权重值可在物理意义上表现出点到点、点到线、点到面以及点到空间的向量,并进一步求出其相对应的Scatter Matrix。
本文提出的特征空间转换法可同时降低人脸识别中光线变化、表情变化以及姿势变化的冲击,其算法架构采用将NFL融入Laplacian Matrix策略,建构一个特征空间转换的机制,于训练过程中,利用点到任意其它两点配对直线的垂直向量建构出WithinClass Scatter以及Between-Class Scatter并求得转换矩阵,利用此一转换矩阵所得到的特征空间,可以在低维空间中把不同类别的影像予以分割,而各类别的样本亦保留了原空间中的拓朴信息以及线性变化的关系,因此此一特征空间是相当适合用来进行分类识别的,此外,将NFL在分类上的优点融入至特征空间转换的训练过程后,于特征空间中只需以NN方法进行比对即有相当好的识别能力,可大幅节省NFL在进行比对时所需要的时间。
4. 实验结果
在实验部分分别对所提出的人脸检测与人脸识别算法进行效能评估,并与其它著名算法进行比较,见表1。

Table 1. Detect of FFS, Adaboost algorithm, and three stages
表1. FFS、Adaboost 算法及提出的三阶段串联式人脸检测器MIT库的检测

Figure 10. Face detection results and test results
图10. 人脸检测结果及误检结果
在基于三阶段人脸识别算法的检测实验中,如图10,可以看到所有的人脸都检测出来了,但是其中还有一个误检测(图10右)。
致谢
衷心地感谢本文所引用的这些优秀文章的作者,他们的文章提供很大的帮助,同时也感谢一路走过的朋友提供了一个好的环境。
基金项目
诚挚地感谢衢州科技计划项目赞助该项课题(No2018k25)和“2017年浙江省高职高专院校专业带头人培养对象人才项目”资助。
参考文献