1. 引言
人类所获取的知识种类繁多,有些是能够清晰表达的,例如人类是一种哺乳动物,有些信息是隐含的、难以用语言表达的,例如描述人类的心理状态。神经网络依靠其多层的网络结构能够从简单到复杂表示不同的概念,擅长存储隐性知识,所以神经网络在模式识别任务中可以取得很好的效果 [1] [2] 。然而神经网络却难以记住非常明确具体的事实 [3] ,例如在输入序列中陈述了“开会时间是三点半”,而输出结果依赖于这一事实时,神经网络通常无法给出满意的结果。尽管可以对输入做出直观的反应,但对于现代人工智能来说,推理能力是至关重要的 [4] 。
很多人工智能问题可以归纳为序列问题,循环神经网络(Recurrent Neural Network, RNN)过去在机器翻译、文本生成等序列任务上取得了非凡的成就,得益于其能够在时间序列中学习到如何转换和表示输入数据。但是标准的RNN会遇到梯度消失的长期依赖问题,长短期记忆网络(Long Short-term Memory, LSTM)通过学习控制输入和隐藏状态,使反向传播的梯度可以在更长时间序列中进行,从而避免了这一问题 [5] 。另外,由于RNN使用网络结构本身存储过去时刻的内容,仍会遇到无法精确地存储具体事实的问题,对于某些需要记录和推理的任务,改进过的LSTM网络依然无法取得好的结果,主要原因是被编码在隐藏状态和权值参数中的事实记忆过于微弱。
解决这一问题的方法是为神经网络添加额外的内存模块,类似人类为实现一些目标而明确保存和操作相关信息片段的行为,将神经网络作为控制器控制内存模块中的写入位置,在需要的时候取出对应位置的信息,从而在少量训练样本中提取更关键的推理信息 [6] 。Weston等人因此提出了记忆神经网络 [7] [8] ,描述了拥有内存模块的神经网络的基本结构,Graves等人 [9] 利用RNN的图灵完备性 [10] 提出了神经图灵机(Neural Turing Machine, NTM),仿照冯诺依曼的计算机结构,使用外部内存模块扩展了RNN,使其能够完成对输入数据的复制和排序等功能。与神经图灵机的注意力机制不同,神经随机读取机 [11] 采用强化学习的训练方法,在离散的内存模块上进行训练,实现了一些简易的算法。可微分神经计算机(Differentiable Neural Computer, DNC) [12] 通过学习相互关联的信息,实现了伦敦地铁路径搜寻、族谱推断等包含复杂推理功能的任务。
由于这些工作将所有的输入数据均视为有效的重要信息,但是并非所有信息都是重要的,例如在自然语言处理中一些名词和动词比介词和副词更加重要。在这种情况下,神经图灵机会遇到收敛速度过慢、训练时间过长的问题。我们在神经图灵机的基础上提出了基于全局内存的读写机制,使控制器网络在任意时刻可以提取过去多个时刻的信息,这对于大部分序列任务来说能够在有限的训练时间内快速收敛。由于网络结构适用于较长的序列,将其命名为长期记忆神经图灵机(Long-term Memory Neural Turing Machine, L-NTM)。
2. 相关工作
2.1. 神经图灵机
神经图灵机模拟冯诺依曼计算机体系,采用外部存储矩阵作为“内存”,使用RNN作为控制器,使用注意力机制与内存进行读写交互 [13] [14] ,其各部分均可导,因此整个网络可以通过反向传播进行训练。利用RNN的图灵完备性,完成了复制、排序等图灵机具备而当前其他神经网络不具备的功能。神经图灵机首次利用外部存储扩展了RNN的功能,使神经网络具备了“记住”短期事实的能力,为推理功能提供了记忆基础。
图灵机作为一种计算模型,可以理解为“建立一个输入纸带到输出纸带的映射”,而神经图灵机就是使用神经网络的方法来“建立从输入纸带到输出纸带的映射”以代替人工编写的程序。神经图灵机在复制任务中完全实现了从输入输出数据中学习到了“复制程序”的过程:将输入数据依次存入内存中,输入结束后,循环的读取内存中的数据并将其输出。
2.2. 可微分神经计算机
作为神经图灵机的升级版,可微分神经计算机(DNC)通过动态分配内存、相关记忆的互相连接等改进,极大地增强了神经图灵机的推理能力。相对于NTM的只能从相邻位置读取信息,DNC能够对内存进行随机读写,且能将相关联的信息使用临时连接关联起来,例如在族谱推理中,父亲和子女会用一些临时连接相互关联,在问到有关父亲的问题时,这些临时连接就会起到非常重要的作用。除此之外,DNC还能够实现更加复杂的推理任务,例如伦敦地铁路线的查询,在描述了伦敦地铁的站点和线路之后,就可以让DNC回答例如“从Bond街出发,顺着Central线沿某方向走一站路,然后沿Circle线按某方向走4站,再沿Jubilee线按某方向走2站,最后你会到达哪一站?”
DNC将神经图灵机的推理能力提高到了更高的层次,同时复杂的结构设计以及对输入信息的处理上使DNC在对待普通任务时同样会受到训练过长、收敛速度慢的问题。
2.3. 记忆神经网络
记忆神经网络以问答系统中的推理机制作为出发点,定义了用可读写的内存模块扩充神经网络的通用结构,包括输入到内部表示的映射、内存更新机制以及内部表示到输出的映射。Weston的《记忆神经网络》更加关注自然语言处理的应用,文中讨论了在应对大文本的内存写入机制,以及当测试集中出现新词时如何应对的问题,同时设计了一些对于非重要信息的遗忘机制,我们在L-NTM中也应用了这一机制。
3. 模型结构
3.1. 基础结构
作为神经图灵机的一个分支,L-NTM的结构如图1所示,包括一个可供读写的记忆存储模块或称为内存模块
和一个神经网络控制器。
是一个
的矩阵,用于存储需要的数据,是记忆的载体,M为内存模块的长度,表示存储数据量的上限,N为每一条存储的维度。
控制器在每一个时刻t都会对
进行读取和写入,它的学习目标就是在不同时刻将不同的输入存储到
中的不同位置,并读取相关的记忆用于输出。为了确保能够使用梯度下降进行端到端的训练,需要在整个计算过程中每一个部分都是可微的,因此控制器输出的地址指针不能指向具体的每某个位置,而是输出一个长度为M的指针向量
,其定义与NTM一致:
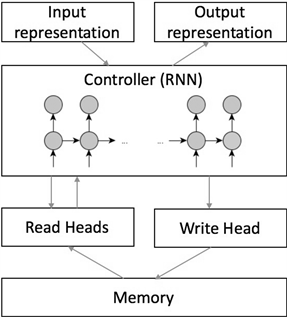
Figure 1. Basic structure of neural Turing machines
图1. 神经图灵机基本结构
#(1)
向量中每一个元素代表在该位置写入的数据量。例如当
,
为
时,控制器会主要在第三个位置写入信息。
L-NTM的控制器中的核心网络采用LSTM网络,LSTM有更好的能力应对序列中的长期依赖问题,从而学习到更好的与外部内存交互的功能。
3.2. 改进的读写方法
通常网络每一个时刻的输出,可能会依赖于多个前期输入,因此在L-NTM中,控制器将会生成多个指针,用于读取多个前期数据。
定义在时刻t第i个读取指针为
,所读取的内容为长度为N的行向量
,其内容为
中每一行对应读取指针的加权叠加:
#(2)
生成读取向量后,控制器中的输出映射函数
会将L-NTM的内部表示映射到具体的输出:
#(3)
写入时,由于在每个时刻只有单个输入,所以只需一个写入指针
,整个写入过程分为两个部分:擦除 [7] 和写入。在时刻t,控制器生成擦除向量
、写入向量
和控制写入量的参数
。其中
和
均为N维向量,且
中所有元素和参数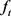 的数值范围均在(0, 1)内。令经过擦除操作的内存为
:
的数值范围均在(0, 1)内。令经过擦除操作的内存为
:
#(4)
当
中的元素越接近于0,则表示上一时刻在对应位置的内容会被保留,越接近于1,这部分内容会越接近于被清除。擦除操作之后会执行写入操作,
为在 时刻将要写入内存的信息,类似于LSTM中的输入门,此处会有一个控制参数
决定当前输入在内存中的存储量。
在一些自然语言处理的任务中,人们的语言中包含了很多对于记忆没有必要的介词等词语,过滤掉这些非关键词是非常重要的。
#(5)
需要注意这里读取指针和写入指针是不相关的,控制器会分别生成两个对应的指针。
3.3. 改进的写入寻址机制
与NTM对读写采用同一种寻址机制不同,L-NTM分别对读写采用了不同的寻址机制。对于写入指针,受DNC的启发,在确定写入位置时,应考虑整体内存的使用情况和记忆的存储分布。卷积运算提供了一种基于局部并可在整体上进行特征提取的方法 [15] ,因此首先使用二维相同(same)卷积核K生成一个长度为N的向量
,其中K的输入通道数为N,设卷积核大小为k。
#(6)
其中,
,
,且
。
k的大小决定了对内存模块局部特征提取的范围,k越大,内存中对应行的特征会关注更大的局部区域,同时边缘内存对全局的影响会降低。在我们的实验中内存长度比较短,因此更需要关注局部的内存特征,k的取值不需要过大,在实验中均取为3。
由卷积核提取的特征向量
的元素有正有负,不符合指针向量的要求(所有元素均大于等于0,且和为1),因此我们采用softmax函数令每一个元素符合指针要求:
#(7)
如果内存模块中的存储比较分散,例如[[0.2, 0.3], [0.1, 0.4], [0.4, 0.3]],而不是[[0.9, 0.8], [0.1, 0.4], [0.2, 0.3]]这种结构非常清晰的存储模式,这会导致
中的位置过于分散,例如[0.3, 0.3, 0.4],而不是[0.8, 0.1, 0.1]。分散的存储在规模较小的内存结构中不会存在太大问题,但当内存的长度即N较大时,相对于有限数量的读取指针,分散的存储不利于信息的读取。因此控制器会生成一个大于1的参数
用于写入指针的聚焦:
#(8)
L-NTM与NTM都有指针的聚焦操作,L-NTM的目的是避免在规模较大的内存中的写入位置过于分散,这会导致读取指针数量不是足够大的时候无法获取到大部分有效信息,而NTM的聚焦更倾向于聚焦到某一行中,对于同样的输入,NTM会出现[0.05, 0.9, 0.05]这样的指针,而[0.25, 0.5, 0.25]对于L-NTM就已经足够。由于聚焦程度的不同,经过一段时间读写的内存状态也会有所不同。如图2(a)所示,在NTM中,会更倾向于在某一个位置写下信息,此时的内存状态按倒序依次在内存中进行写入,在其他地方的数据量则会很小,图2(b)所示为L-NTM的内存状态,聚焦程度较小时,写入的信息量会比较分散。
在NTM中,内存模块的初始化全部为接近于0的非常小的数,例如
,这会导致卷积运算的结果
除了边界元素都相等,这会对写入指针的聚焦操作造成很大的困难,因此在L-NTM使用高斯分布对内存模块进行初始化,不同位置的存储越不相同,卷积运算后提取的特征越不一致,这将使最终的写入指针更加聚焦与某一位置。
完整的流程如图3所示,首先利用卷积运算提取出内存的特征,之后利用softmax函数令向量满足指针形式,最终利用聚焦运算将写入位置聚集到某几个位置上。
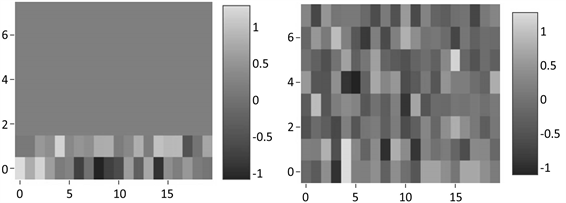 (a) NTM内存示例 (b) L-NTM内存示例
(a) NTM内存示例 (b) L-NTM内存示例
Figure 2. Example of memory
图2. 内存示例,(a)为NTM的内存示例,在NTM中,内存会偏向于按顺序读写,而在L-NTM中,则更加偏向于全局读写
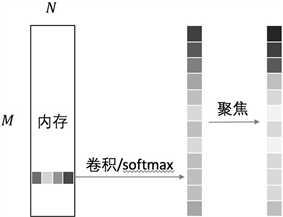
Figure 3. Addressing mechanisms of writing heads
图3. 写入指针的寻址机制
3.4. 改进的读取寻址机制
生成读取指针的过程分为内容寻址和全局寻址两个过程。内容寻址与NTM一致,控制器生成一个N维行向量
,利用相似度度量方法
与
中每一行
进行比较,生成基于内容的读取指针
:
#(9)
其中
是一个用于增强或减弱这一时刻的基于内容的寻址权重。内容寻址的目的是在该时刻想要获取什么样的记忆存储,与精确地取得记忆不同,获取大致的想要的内容不需要大量的数据用于训练,同时又足够灵活能够应付更多种类的输入情况。
全局寻址采用的方法同样使用了卷积运算,与写入机制寻址的方法不同的是,在读取的全局寻址中使用多个卷积核,这是为了能够更好的分析内存模块以多种特征向量,同时针对不同的特征向量
,生成不同的控制参数
,
的范围在(0,1)内,用于将
与
结合起来:
#(10)
上述所有的操作均为可微的,因此L-NTM可以使用梯度下降进行端到端的训练。由于中间有大量的卷积运算,得益于卷积运算可以并行计算的特性,L-NTM的训练和运行都会以更快的速度执行。图4展示了读取指针的寻址机制。
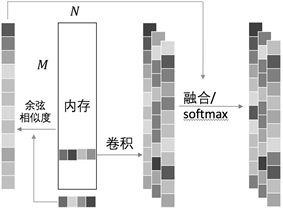
Figure 4. Addressing mechanisms of reading heads
图4. 读取指针的寻址机制
从强化学习 [16] [17] 的角度来看,将内存模块视为状态(state),那么写入机制是对状态转换的函数进行建模,读取机制则为依据当前状态进行动作(action)选择 [18] 。通过端到端的学习训练,读取机制会逐渐学习到不同内存状态下的读取位置,而写入机制则会学习到依据上一时刻的内存状态判断当前的写入位置。一旦某一个机制趋于稳定,那么后续训练则会按照类似于强化学习的训练过程不断优化以达到最优结果。
4. 实验
bAbi数据集 [19] 是包含一系列推理任务的问答数据集,数据形式为故事陈述、问题和答案组成。我们使用了其中“Single Supporting Fact”和“Two Supporting Facts”两个子数据集用于NTM和L-NTM的比较,在“Single Supporting Fact”任务中,答案仅与陈述中的一句话有关联,只需一个事实支撑即可得到正确答案,在“Two Supporting Facts”中,为获取答案需要两句陈述支持,并且需要一定的推理才能完成。形式如图5所示。
对于问答形式的任务,通常会使用两种处理方法 [19] [20] :1) 序列到序列的方法;2) 陈述语句和问题分为两部分模块;如图6所示。在这里采用第一种方法,相比于第二种方法,第一种方法对应更长的序列和更加通用的序列任务,这可以在一定程度上检验模型的泛化能力。
我们使用LSTM和NTM作为基线,整个数据集包括10,000条训练数据和1000条测试数据,使用PyTorch实现模型并在一块NVIDIA P100的GPU上进行训练。
内存参数设为$M = 8,N = 20$来初始化NTM和L-NTM的内存结构,在L-NTM中,分别设置了读取指针书量为8、16和32,从图7中可以看出,NTM的收敛速度在L-NTM的8个读取指针和16个读取指针之间,小于32个读取指针的收敛速度。
读取指针的数量越多,所能提取内存特征也越多,误差的下降速度也会更快,同时由于参数的增多,所采取的正则化项也更严格。实验结果见表1,括号中的时间为一次迭代所需的时间。
在训练速度上L-NTM相对于NTM来说提高了6倍,得益于GPU的并行计算,读取指针的数量增加几乎不会增加训练时间,因此读取指针分别为8、16和32时,一次迭代的训练时长均为4分40秒左右。
对于L-NTM能够取得如此效果的一个可能的原因是大部分序列任务本不需要过于精确地读写,大致的范围就已足够实现目标。由于序列中有很多“to”、“the”等单词,这些无用信息不需要被精确地存储下来,而NTM将这些信息都存储下来,浪费了存储空间和读取的时间。
接下来仅使用LSTM作为基线与L-NTM在“yes/no questions”、“simple negation”、“basic deduction” 和“agent’s motivation”任务中进行比较,实验结果为表2。表明了L-NTM在推理任务中的表现要优于
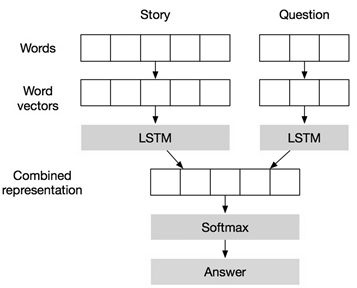 (a) 序列到序列的模型
(a) 序列到序列的模型 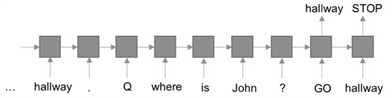 (b) 陈述与问题分开式的模型
(b) 陈述与问题分开式的模型
Figure 6. Structure of question answering models
图6. 问答模型结构,(a) 采用序列化方法,使用特殊符号作为故事陈述和问题的分隔符,在特殊符号“Q”后为问题序列,特殊符号“GO”之后的输出为答案;(b) 将故事陈述和问题分开为两个模块,分别经过LSTM序列化处理最终联合起来共同生成答案
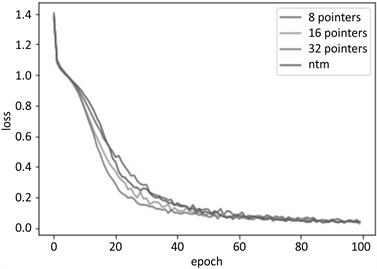
Figure 7. Training results of “Single Supporting Fact”
图7. “Single Supporting Fact”训练结果

Table 1. Experiment results of LSTM, NTM and L-NTM
表1. LSTM、NTM和L-NTM的实验结果
Table 2. Experiment results of LSTM and L-NTM
表2. LSTM和L-NTM的实验结果
LSTM,这表明了具体的记忆存储可以提高推理任务的准确率。在简单的问答任务中,L-NTM将陈述的事实内容存储在内存空间中,在问题中序列中通过搜索存储内容进行推理,得到了更好的结果。因此在一些类似的序列任务中,L-NTM在一定程度上能够替代LSTM。
5. 结论
以神经图灵机为基础改进了写入方法和读写指针的寻址机制:在写入方法中加入了用于控制写入量的控制参数,一些相对于实体名词含有信息量较少的副词、介词等输入将不会占用过多的内存空间,减少了推理行为中对于无效信息的处理;在寻址机制中,使用卷积运算提取内存模块的多种特征和基于内容寻址的相互结合,在某一时刻可以提取更多的事实依据用于推理;以上改进在bAbi数据集的实验中不仅加快了收敛速度,同时也在训练速度上提升了6倍,并且在更长的序列中得到了更高的准确率。在与LSTM的对比中,L-NTM体现了更强的推理能力,在所有的推理任务中均取得了最佳结果。