1. 引言
贫困问题一直是人类社会发展以来面临的经济问题,推进精准扶贫,消除贫困人口,是社会主义制度本质的内在要求。农业科技扶贫是扶贫工作的重要内容、是贫困农牧民3,087,849人,在未来的减贫道路上依然很艰巨,2016年,安徽全省农林牧渔业增产增收的重要手段、贫困地区良性可持续发展的重要途径。习近平总书记在湘西考察时首次提出了精准扶贫,后来又在多种场合进一步阐述并丰富其内涵,形成了系统的思想。精准扶贫是马克思主义中国化的又一个重要的最新成果,具有深远的实践意义和广泛的理论意义。党的十八大和十八届二中、三中、四中、五中全会明确指出要把精准扶贫、精准脱贫作为国家扶贫战略的基本方略,到2020年要使7000多万农村贫困人口实现脱贫。2016年,中国超过1000万人告别贫困,这意味着“十三五”脱贫攻坚首战告捷;2015年一年以来,安徽减贫人数为922,151人,减贫幅度达23%,贫困发生率降到5.71%,但是,安徽省2015年的贫困人口数还有总产值4655.5亿元,按可比价计算,增长3.4%。其中,农业2234.1亿元,增长2.5%;林业291.1亿元,增长4.9%;牧业1375.7亿元,增长2.0%;渔业513.2亿元,增长3.1%;农林牧渔服务业241.5亿元,增长22.8%。农林牧渔业增加值2693.2亿元,增长3.4%。2016年安徽的第一产业的经济发展稳定,对于由此考虑的进行考虑第一产业的产业脱贫方式具有一定的基础的支撑,而且第一产业的稳定发展对于该省贫困县的农民的脱贫具有很好的新生循环能力,也对于当地居民的造血功能有了很大的能力的提升。而且很少有学者研究第一产业的发展对精准扶贫的影响,本文的研究在具体的实施上具有很好的可实施性和一定的经济研究价值。
倪志良,郝志景(2007)从政府的角度研究财政扶贫支出对该贫困县扶贫效果的分析,他认为应该加大教育与培训投入,提高贫困人口的自我生存能力,这样才可以更好的具有长期的减贫效果 [1] ;沈能,赵增耀(2012)研究发现,科研方面的农业支出能够显著的减贫,但是存在门槛,减贫效应随着经济发展和支出强度而降低 [2] ;Zaman (2013)基于1964~2011年间巴基斯坦的亲贫式增长政策,来揭示农村、城市、国家层面经济增长,不平等和贫困的关系,研究表明,基尼系数的增加,经济增长会减少农村和城市的贫困,在收入不变基尼系数增加的情况下,会加大农村和城市的贫困,并且城市的贫困比农村增加的多,经济增长过程并没有普遍有利于穷人 [3] ;Azhar Khan等(2014)通过考察2005~2010年间特定138个国家贫困指数、不平等指数与月人均收入的长期关系。发现经济增长可以有效的减少贫困,而收入不平等能增加贫困 [4] ;李逢春,唐端(2015)以陇南为例,分析农产品电商的发展对农产品增收的影响,进而通过农产品产业发展来研究对精准扶贫效应的影响 [5] ;张蓓(2016)借鉴发达国家农产品供给侧结构性改革的成功经验,应着力夯实供给侧基础,提高供给侧效率,开拓供给侧空间,保障供给侧安全和增加供给侧价值,推动我国农产品供给侧结构性改革的顺利进行 [6] ;程蕾(2016)以安徽省贫困县为例,从政府的角度对公共支出的减贫效应进行实证分析,并得出结论,医疗卫生支出、社会保障支出、农业性支出具有很好的直接减贫效应,而教育支出的直接减贫效应不显著 [7] 。
2. 模型介绍
固定效应模型(Fixed Effects Model,简记FE)是一种控制面板数据中随个体变化但不随时间变化的一类变量方法有n个不同的截距,其中一个截距对于一个个体。可以用一系列二值变量来表示这些截距。固定效应回归是一种控制面板数据中随个体变化但不随时间变化的一类变量方法。固定效应模型具有如下的特征
(1)
其中
为不随时间而变的个体特征(即
);
可以随个体及时间而变。扰动项(
)两部分构成,称为“复合扰动项”,而(1)方程也称为“复合扰动项方程”。其中,不可观测的随机变量
是代表个体异质性的截距项,故方程(1)也称为“不可观测效应模型”。
如果
与某个解释变量相关,则进一步称之为“固定效应模型”(FE)。在这种情况下,OLS是不一致的。解决方法是将模型转换,消去
后获得一致估计量。
对于固定效应模型,给定个体i,将(1)方程两边对时间取平均可得
(2)
将方程(1)减去平均后的方程(2)可得原模型的离差形式
(3)
定义
,
,
,则
(4)
由于(4)式中已经将
消去,因此只要
与
不相关,就可以用OLS一致地估计β,称为“固定效应估计量”,记为
。由于
主要使用了每位个体的组内离差信息,因此也被称为“组内估计量”。即使个体
与解释变量
相关,只要使用组内估计量,就可以得到一致估计,这也是面板数据的一大优势。
如果在原方程中引入(
)个虚拟变量来代表不同的个体,则可以得到与上述离差模型同样的结果,因此,FE也被称为“最小二乘虚拟变量模型”(Least Square Dummy Variable Model,简记LSDV)。
3. 实证分析
3.1. 数据选取
考虑到安徽地区的实际情况,模型估计所使用的观测变量包括:每个县的第一产业中的农业生产总值,林业生产总值和渔业生产总值,所使用的数据频率为年度数据,样本区间为2011年至2015年,样本为安徽的17个国家级贫困县,分别是:利辛县、砀山县、萧县、灵璧县、泗县、临泉县、阜南县、颍上县、寿县、霍邱县、舒城县、金寨县、石台县、潜山县、太湖县、宿松县和岳西县。
考虑到数据的可得性,本文主要是选取从2011年到2015年期间,17个国家级贫困县的第一产业指标中的农业,林业,渔业的地区生产总值所组成的面板数据,考虑到stata软件的指标输入,本文对安徽17个国家级贫困县进行编号,按利辛县、砀山县、萧县、灵璧县、泗县、临泉县、阜南县、颍上县、寿县、霍邱县、舒城县、金寨县、石台县、潜山县、太湖县、宿松县和岳西县这个顺序依次对其进行1, 2, 3, ∙∙∙, 17来进行一一对应。然后对各个指标进行再命名,用county代表县,pov表示每个县的贫困发生率,nong代表农业的地区生产总值,lin代表林业的地区生产总值,yu代表渔业的地区生产总值,year代表年份,然后再对各县第一产业的3个地区生产总值指标取对数。
3.2. 数据的描述性统计
由表1中安徽17个国家级贫困县每个县的贫困发生率、林业、农业和渔业4个指标数据的描述性统计值可以看出,该指标具有一定的平稳性,没有太突出的值,说明该数据的平稳性很好。
3.3. 数据平衡性的检验
经面板数据的平衡性检验,安徽17个国家级贫困县的各个指标数据为平衡的面板数据,而且由于该数据的时间周期很短只有5年,而数据的样本有17个县,因此该数据为短面板数据。
为了更直观的观测每个县的贫困发生率的变化,我们得到下表所示的图像,图1是从2011年到2015年这5年期间的安徽省的17个国家级贫困县的贫困发生率的一个清晰的图示:从下图可以看出17个国家级贫困县的各个县的贫困发生率在近5年期间的动态变化,而且从图中可以清楚的看出,不同县的贫困发生率变化的趋势不一样,有些县成近似直线下降趋势,例如前10个县,而另外一些县是成折线下降趋势的。在一定程度上,不同县的贫困发生率的差异有助于估计决定省贫困发生率下降的因素。而且考虑到实际情况也是这样,安徽省的每个贫困县都会有每个县不同的致贫的影响因素,因此每个县的情况各异,减贫效应也不一样。详细结果见图1。
本文主要是选取从2011年到2015年期间,17个国家级贫困县的第一产业指标中的农业、林业和渔业来进行实证分析。
3.4. 豪斯曼检验
由表2检验结果:p = 0000 < 0.05,故应该强烈拒绝原假设,认为不应该使用随机效应模型而是固定效应模型。
3.5. 模型结果
考虑到实际情况各个县的致贫原因不同,影响因素也不相同,可能存在不随时间而变的遗漏变量,因此本文对安徽省的17个国家级贫困县进行固定效应模型进行实证分析。首先我们对该数据先进行简单的OLS回归,来作为结果的对照组,然后在进行组内估计值估计结果记为FE_robust,而且得到的rho=0.99453618,因此复合扰动项(
)的方差主要来自个体效应
的变动。因此对于模型是使用混合模型还是固定模型要进行一定的检验,因此对该模型进行固定效应回归,得到对于原假设“
”,固定模型回归结果对于上述假设的p为0.0000,因此强烈拒绝原假设,即认为FE优于混合回归,应该

Table 1. The descriptive statistics of data
表1. 数据的描述性统计
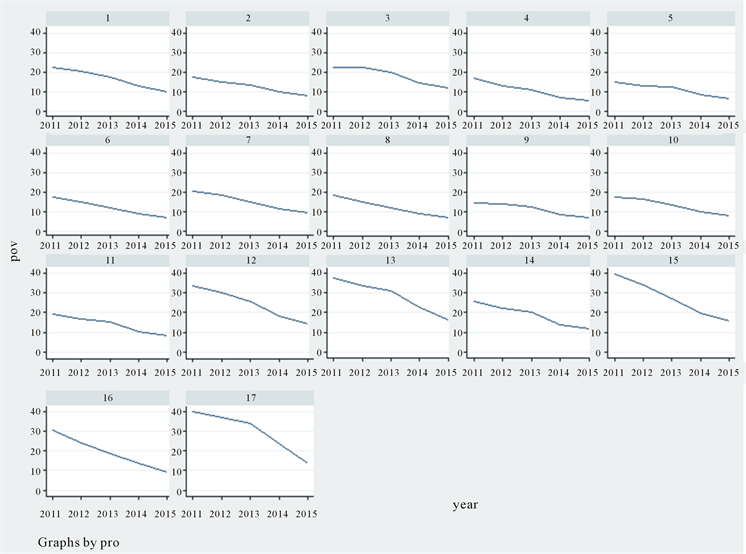
Figure 1. Overview of poverty incidence form 2011 to 2015 in 17 provinces
图1. 2011~2015年17个省份贫困发生率的概况
允许每个县有自己的截距项,因此对模型进行LSDV法来进一步考察,这样可以得到每个县异质性
的估计并得到如下的结果见表3。
由表3可知安徽省每个贫困县的情况不一样,得到的结果也不一样,这也与事实是相符的,每个县的致贫原因不同,针对脱贫所采取的措施也不一样,但是也有很多县的个体效应不显著,因此安徽有很多贫困县对于贫困还是有一些共性,如上表所示,第13、14和17个也就是石台县、潜山县和岳西县的个体特征比较明显,对于这些县的脱贫政策需要更好的了解当地的情况,进行因地制宜的脱贫,而对于其他县,由于个体特征不是特别显著,这也说明对于这些县的脱贫政策,农业收入的增加对它们的减贫具有一定的作用。
Standard errors in parentheses. *p < 0.1, **p < 0.05, ***p < 0.01.
最后把上述OLS、固定效应模型FE_roubust和混合回归FE这3种方法的模型结果对比来看,可以更好地反应模型的结果,也对模型的准确性有一定的保障,如表4。
4. 结论和政策建议
由上表4结果可知,OLS的结果相对于其他两个不是很好,FE模型具有很好的显著性,而且对于各个系数而言都是负值,这也说明第一产业的各个指标对安徽省各县的减贫具有正向的促进作用,对于单个系数而言农业和渔业系数的显著性都很好,均小于0.01,这说明农业和渔业这两个指标的系数在统计上是非常显著的,也就是说第一产业产值的增加会在一定程度上降低安徽各县的贫困发生率。而对于各个地方贫困县的人民的农业或是渔业的收入是他们直接的收入来源,而且由以上结果也可以清楚的知道,它们会对安徽各县的贫困发生率的降低具有一定的显著性影响,而且农业和渔业的模型系数显著性都很高,这也说明安徽省第一产业的发展对各县贫困发生率有明显的减贫效果。因此,安徽应该加快农业现代化步伐,在各个贫困县的基础上因地制宜加快对当地农业的发展。
因此,安徽省可以结合农业的供给侧改革和农产品的经销渠道,或是考虑农产品与互联网的结合,即农产品与电商的结合。这样就可以通过增加农产品的收入来直接增加农民的收入,进而达到农产品的产品脱贫的目的,这对于贫困县的农民来说,是最直接也是最有效的一种脱贫的方式。