1. 引言
语音通信和人机交互是现代通信中重要的通信方式。但是,在语音通信和语音识别的过程中,语音信号无法免除地会受到外界噪声的干扰,所以阻碍了人与人之间,人与机器之间的交流。因此从带噪语音中提取出纯净语音信号是语音增强技术的目的所在。单信道语音增强是语音信号处理的关键分支,其应用技术的研究具有重要的适用价值,尤其在语音识别,医疗领域,军事通信,数字家电等领域已被广泛应用 [1] 。为了提高移动环境下的通信品质,实现实时通信,需要在传输到远端之前有效抑制背景噪声 [2] 。虽然语音增强技术看似只是一个恢复纯净语音的简易过程,但在学术领域涉及到的众多技术和方法是不容小觑的。随着人们对接收语音信号的质量要求不断提高,越来越多的语音增强算法被提出。其中比较经典和具有代表性的算法有谱减算法,维纳滤波算法,最小均方误差算法,小波变换算法等等 [3] 。由于基于谱估计统计模型的语音增强算法中的模型能够很好的适应信号的变化,因此这种算法受到了广大学者的青睐。基于谱估计统计模型算法的优点是适用范围广,易于理解,实施起来比较简单,且对于各种背景噪声抑制效果较好。
其中比较经典的谱估计统计模型算法是幅度平方谱最小均方估计算法,该算法在低先验信噪比和高后验信噪比的情况下能够有效地抑制背景噪声,减少语音失真。但是,基于谱估计统计模型的幅度平方谱最小均方算法并没有将语音信号的语音存在不确定性考虑在内 [4] ,因此会不可避免的造成语音成分的丢失,影响了语音增强的效果。因此本文针对幅度平方谱最小均方估计器算法中没有考虑到语音信号存在不确定度的缺点提出了一种新的算法融合无语音概率的算法。本算法是在幅度平方谱最小均方估计器的基础上,推导出每一个频点的无语音概率,进而将幅度平方谱最小估计器的增益函数与无语音概率相结合成一个新的增益函数。
本文的结构如下:第二部分简单描述了基于统计模型的语音增强算法基本理论,第三部分主要是对提出的新的算法——融合无语音概率的语音增强算法进行理论分析和公式推导,第四部分通过实验仿真的语谱图,以及四种客观评价标准:分段信噪比(Segmental SNR, SegSNR),短时客观可懂度(Short Time Objective Intelligibility, STOI),感知语音质量(Perceptual Evaluation of Speech, PESQ)和对数谱距离(Log-Spectral Distortion, LSD)结果进行定量分析,进一步比较了两种算法的优缺点,最后做出总结。
2. 语音增强算法基本理论
基于统计模型的语音增强算法,经过傅里叶变换后其纯净语音信号以及噪声语音信号通常都假设服从高斯分布,基于此模型Loizou等人提出了一种语音增强算法幅度平方谱最小均方误差估计器算法(MMSE-MSS),该算法假设带噪语音信号的频谱幅度的平方等于纯净语音频谱幅度的平方加上噪声频谱幅度的平方,实际上传统的谱减算法以及谱估计统计模型都是采用这种假设。但是上述假设是在统计意义上成立的,即假设X(k)和D(k)是两个不相关的随机变量,根据上述假设可得 [2] [3]
(1)
计算条件最小均方误差由
(2)
其中
(3)
其中,当
时,
(4)
(5)
很明显从可以看出(5)式之中为一正数。将式(3)带入式(2)经过计算可得
(6)
其中,
定义为
。
因此式(6)可得幅度平方谱最小均方误差估计器的增益函数为
(7)
上述算法在很大程度上消除了背景噪音并提高了语音质量,不幸的是,该算法由于没有将语音存在概率考虑在内,因此导致了增强所需的语音成分损失严重影响了人类所感知的语音可懂度的下降。
3. 本文提出的融合无语音概率的语音增强算法
上述Liozou等人提出的算法并没有考虑到带噪语音中存在语音不确定度的问题,因此本节主要是研究语音存在的不确定问题,将无语音概率估计出来融合到增益函数中 [4] ,能够在一定环境中明显的改善语音质量,提高语音可懂度。本文假设纯净语音信号和噪声语音信号统计独立,且它们经过傅里叶变换后的系数服从高斯分布,因此,它们的系数的平方服从指数分布 [5] ,即:
(8)
(9)
因此带噪语音信号
的傅里叶变换系数则服从如下分布 [6] :
(10)
其中,k代表频点,
,
,
分别是带噪语音频谱,纯净语音频谱以及噪声频谱,由于语音存在的不确定,将语音分为有语音和无语音两个状态,表示如下:
(11)
其中,
分别表示无语音段和有语音段,则
和
分别代表概率密度函数和条件概率密度函数。
即
(12)
(13)
利用贝叶斯公式可得:
(14)
其中,
,代表无语音概率,
是先验信噪比用经典直接判决算法(DD)计算得出,
代表后验信噪比可由带噪语音功率比上噪声功率得到。
因此将无语音概率引入到幅度平方谱最小均方误差估计器中得到新的增益函数即:
(15)
即融合了无语音概率后的幅度平方谱最小均方误差估计器为:
(16)
4. 仿真实验结果分析
为了对比幅度平方谱最小均方误差算法与本文算法的性能,利用MATLAB为仿真实验平台,以此评比算法的优劣。实验数据主要来自于语音库10段纯净语音信号(5段男声,5段女声)作为测试。噪声来自于噪声库比较有代表性的White噪声,输入信噪比分别取5 dB,10 dB,15 dB。噪声功率谱估计采用最小值控制递归平均算法(MCRA) [7] 。所有信号的取样频率均为8 kHz/s,仿真实验中语音信号帧长K = 256,窗函数采用正交汉明窗,参数q取0.8 [8] 。
通过图1语音增强后语谱图的对比可以看出,两种算法都能够有效的去除背景噪声,但是本文提出的算法对去除背景噪声能力要优于幅度平方谱最小均方估计算法,且语音失真程度方面本文算法失真较小,具体的去噪能力,失真程度,以及语音可懂度性能方面还要从上述表格数据中对比分析。通过对数谱距离(LSD),分段信噪比(segSNR),语音的可懂度(STOI)以及感知语音质量(PESQ)等四种评价标准进行对两种算法增强后的语音性能进行评估 [9] [10] ,其中LSD表示增强后的语音信号与纯净语音之间的接近程度,其值越小,说明增强后的语音信号越贴近原始纯净语音信号,其失真程度越小,增强效果越显著。其中segSNR是表征带噪语音信号抑制噪声性能优劣的重要标准,数值越大,表明去除背景噪声的能力越强,增强效果越好。STOI和PESQ都是符合人类听觉系统的语音质量评价标准,其数值越大,代表增强后的语音可懂度越高。
从表1中,我们可以看出,本文提出的算法在white输入信噪比分别为5 dB,10 dB,15 dB时,其本文提出的算法其LSD数值更小,说明其对原始纯净语音信号的语音失真比较小,因此本文算法在语音失真方面有了明显改善。从表格的数据中可以看出,本文提出的算法其SegSNR的数值要明显大于幅度平方谱最小均方估计算法,说明本文提出的算法其抑制噪声的能力有了明显提升。进一步从语音质量和语音可懂度方面分析,其本文提出的算法STOI值和PESQ值更大,说明本文提出的算法对语音质量和语音可懂度方面有了明显提高。总体来说,语音增强性能要明显优于MMSE-MSS算法。
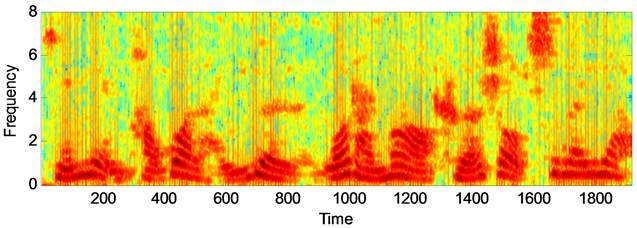 (a) 纯净语音信号语谱图
(a) 纯净语音信号语谱图 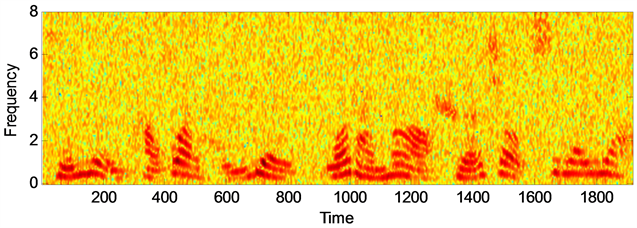 (b) 带噪语音信号语谱图
(b) 带噪语音信号语谱图 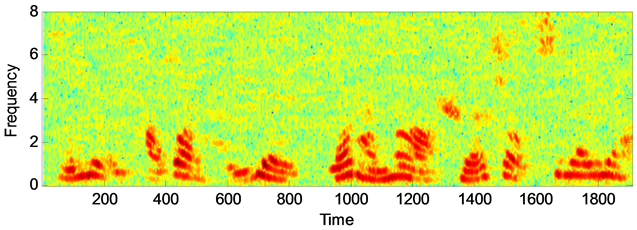 (c) 基于MMSE-MSS算法的增强语音语谱图
(c) 基于MMSE-MSS算法的增强语音语谱图 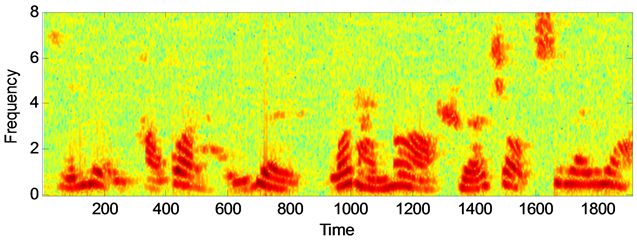 (d) 基于本文算法的增强语音信号语谱图
(d) 基于本文算法的增强语音信号语谱图
Figure 1. The spectrum of speech signal of different algorithms under white noise. (SNR = 10 dB)
图1. 白色噪声下不同算法的语音信号语谱图(SNR = 10 dB)

Table 1. The data comparison table of the two algorithms
表1. 两种算法的LSD数据对比表
5. 小结
本文主要研究了语音增强算法中基于谱估计模型中的语音存在不确定度问题,介绍了经典的幅度平方谱最小均方误差算法,以及概述了该算法在实现过程中没有对语音信号是否存在进行检测的缺点并对其缺点进行改进,提出了一种新的语音增强算法——通过融入语言存在概率的估计来去除背景噪声,改善语音质量,提高语音可懂度。最后通过使用Matlab软件进行实验仿真,仿真结果表明本文提出的算法在输入信噪比比较高的情况下,其增强后的语音性能明显优于幅度平方谱最小均方估计算法。在输入信噪比比较低的情况下,此算法也有相对来说较高的优越性。所以未来的研究工作是让本文提出的融合无语音概率的算法在任何噪声环境下增强后的语音性能都比较优越。