1. 引言
两总体均值差的假设检验问题来源于生产生活的实际需求之中,是医学、经济学以及现实的工业生产等各领域的统计工作中的一部分。然而因为检验问题中包含讨厌参数,且样本量有限,因此传统的频率学派很难给出精确的方法。本文利用广义推断思想方法的广义枢轴量法解决此类假设检验问题,另外,根据假设检验问题与区间估计的一一对应关系,对兴趣参数置信区间进行了研究。比较数值模拟的结果可知,通过广义枢轴量法得到的检验统计量犯第一类错误的概率都小于显著性水平α,不管样本量和总体数如何变化,结果都很好,确定了广义推断思想方法的良好性能。
2. 预备知识
2.1. 广义检验变量和广义P值
定义1:广义检验变量与广义p值。
形如
的广义检验变量,不仅是随机向量X的函数,也是观测值x和未知参数
的函数,且满足以下三个条件:
1) 对给定的x和
,
的分布函数与讨厌参数
无关。
2) 观测值
与
无关。
3) 对给定的x和
,
关于
非减(或非增)。
考虑单边假设检验问题;
,
(1)
若
关于
非减,则关于检验问题(1)的广义p值为
若
关于
非增,则关于检验问题(1)的广义p值为
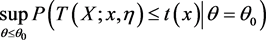
其中
为
当
时的观测值 [1] 。
检验的p值是指在假设检验问题中利用观测值做出拒绝原假设的最小显著性水平,即拒绝域的上确界,因此有了上面的判断形式,这样可以避免事先确定显著性水平,也可以用p值与人们心中的显著性水平
进行比较,通常情况下,p值越小越容易拒绝原假设。
2.2. 广义枢轴量和广义置信区间
定义2:广义枢轴量和广义置信区间。
形如
的广义枢轴量是
和
的参数,其中
,
是兴趣参数,
是讨厌参数,并且满足以下条件:
1) 对给定的x,
的分布与未知参数
无关。
2) 观测值
与讨厌参数
无关。
假设给定广义枢轴量
和置信系数
,寻找R的样本空间的一个子集
,使得
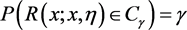 ,
,
取
,
则称
为参数
的一个置信系数为
的广义置信区间 [2] 。
广义枢轴量法解决了传统枢轴量法无法解决的问题,即当分布含有讨厌参数时枢轴量很难或者无法构造的问题。
事实上,广义检验变量T和广义枢轴量R之间有如下关系:
,其中
为兴趣参数的函数,因此可以通过构造广义枢轴量的方法来进行假设检验,且其相应的广义p值可以通过二者的关系计算得到。
2.3. Fiducial广义枢轴量
定义3:Fiducial广义枢轴量。
设
是关于
和
的参数,其中
,
是兴趣参数,
是讨厌参数,并且满足以下条件:
1) 对给定的x,
的分布与未知参数
无关。
2) 观测值
。
则称
为兴趣参数
的Fiducial广义枢轴量。
可以看出Fiducial广义枢轴量是广义枢轴量的特殊情况,这也使得Fiducial广义枢轴量可以通过构造参数的Fiducial分布得到,且已经有了较为成熟的构造方法 [3] ,下面的部分将主要通过实例来做假设检验问题。
3. 广义枢轴量法在假设检验与置信区间中的应用
3.1. 两正态分布均值差的检验
设
和
是分别来自两正态总体
,
的随机样本,
,
,
,
相互独立,其中考虑检验问题:
,
(2)
令
,
,
,
已知
是独立的充分统计量,分别是
的极大似然估计。其中:
,
,
是相互独立的随机变量。
设
是
的观测值。
令
,
,则关于检验问题(2)的广义p值为:
其中
,并且分别服从自由度为
和
的t分布。
是自由度为
的t分布的分布函数,
是对
来求得。
根据假设检验与区间估计的一一对应关系,我们可以得到
的置信系数为
单侧置信下限。
具体可以通过下面的形式得出:
因此,
的置信系数为
的置信区间为
,其中
满足:
3.2. 两指数分布均值差的检验
设
表示形状参数为
,尺度参数为
的伽马分布,
和
是分别来自指数分布总体
,
的随机样本,均值分别为
和
,
,
,
,
相互独立,考虑检验问题:
,
(3)
其中
。
已知
,
是独立的充分统计量,因此检验可以基于两个充
分统计量来进行。
令
,
,
,其中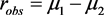 ,则关于检验问题(3)的广义p值为:
,则关于检验问题(3)的广义p值为:
根据假设检验与区间估计的一一对应关系,我们可以得到
的置信系数为
单侧置信下限。具体可以通过下面的形式得出:
的置信系数为
的置信区间为
,其中
满足:
3.3. 截尾指数分布均值差的检验
设
来自一截尾指数分布的一个样本,其密度函数为:
其中,
为门限参数,
为尺度参数。考虑假设检验问题:
,
(4)
其中,
是分布的均值。
已知
和
是两个独立的充分统计量。并且有:
;
;
令
,其中
,
因此关于检验问题(4)的广义p值为:
其中,
是自由度为
的卡方分布的分布函数。
根据假设检验与区间估计的一一对应关系,我们可以得到
的置信系数为
单侧置信下限。具体可以通过下面的形式得出:
因此
的置信系数为
单侧置信区间为
,其中
满足:
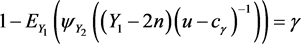
3.4. 指数分布定数截断寿命试验均值差的检验
设
和
是代表寿命的随机样本,分别来自指数分布总体
,
,其均值分别为
和
,
,
,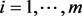 ,
,相互独立,同时假设对两总体寿命的观察分
,
,相互独立,同时假设对两总体寿命的观察分
别在抽取的第m个和第n个样本之后结束,考虑检验问题:
,
(5)
已知
和
是
和
的充分统计量。并且有:
,
,因此:
;
令
,其中
,
因此关于检验问题(5)的广义p值为:
其中
是自由度为2n的卡方分布的分布函数。
根据假设检验与区间估计的一一对应关系,我们可以得到
的置信系数为
单侧置信上限。具体可以通过下面的形式得出:
因此
的置信系数为
单侧置信区间为
,其中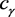 满足:
满足:
.
3.5. 关于随机效应模型的检验
考虑随机效应模型:
,
,
其中
是未知参数,
是随机效应项,且
,
是误差项,且
。令
为第i个随机效应的样本均值并且
为所有观测者的均值。令:
,
其中
为组内平方和,
为组间平方和。考虑假设检验问题:
,
(6)
已知
和
为充分统计量,且有:
,
构造广义枢轴量
,其中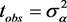 ,且R关于
非减,因此关于检验问题(6)的广义p值为:
,且R关于
非减,因此关于检验问题(6)的广义p值为:
.
其中
是自由度为
的卡方分布的分布函数。
根据假设检验与区间估计的一一对应关系,我们可以得到
的置信系数为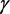 单侧置信下限。具体可以通过下面的形式得出:
单侧置信下限。具体可以通过下面的形式得出:
因此
的置信系数为
置信区间为
,其中
满足
。
4. 结论
根据概率积分变换的性质,我们得到广义p值服从
上的均匀分布。
若显著性水平
为0.05,根据模拟结果得到的广义p值均控制在显著性水平以下,且有非常好的性能,当样本量或总量发生变化时,模拟的结果依然很稳定。
本文只在一元情形下做研究,关于广义p值在多元统计下的统计推断问题的应用我们会继续研究,虽然广义推断有着经典频率学派方法所没有的优点,但未必在所有情况下都适合,并且在很多情况下统计推断也无法给出相应的解决方法,这也是需要我们进一步进行探讨与研究的。