1. 引言
随着互联网技术与多媒体共享社区的不断发展,大量的多媒体内容已进入我们的日常生活,如何高效准确地对海量的未标注图像等媒体内容进行搜索、浏览、管理变得尤为重要,这也使得图像自动标注的重要性日益增强。近年来众多学者对图像自动标注方法做了大量的研究,取得了若干阶段性成果,例如浅度学习方法:支持向量机SVM [1] 、核典型相关分析KCCA-2PKNN [2] 、稀疏核学习SKL-CRM [3] 、快速标注FastTag [4] 、离散多重伯努利模型SVM-DMBRM [5] 、图像距离尺度学习NSIDML [6] 、生成判别联合模型GDM [7] ;以及最近流行的深度学习方法:渐进式深度自动图像标注ADA [8] 、图像标签对齐模型SEM [9] 和图拉普拉斯正则化深度神经网络HQ-III [10] 等。这些传统的图像标注方法考虑了视觉特征与语义概念之间的关联,而在标注概念之间语义关联方面还存在诸多未得到很好解决的问题。很多方法仅在平衡的小概念字典上完成,而在带有大概念字典的数据集上,语义概念分布或者语义概念出现频率呈现较大差异(即概念的不平衡性),这大大影响了标注方法的效果。因此,研究在不平衡图像库上的自动图像标注很有必要也很有意义。
在图像标注领域,深度学习方法(如卷积神经网络CNN)比传统浅度学习方法在性能上大大提升,然而,其并未很好考虑语义概念之间的关联,这影响了其性能的进一步改善。本文针对该问题,提出了一种基于隐马尔科夫模型(HMM)与卷积神经网络(CNN)的自动图像标注方法HMM + CNN,该方法使用HMM模型来校正语义标签:把图像标注过程视为检索有相互关联的隐藏语义概念序列过程,它提高了高度关联的相关概念语义分数而弱化了毫无关联的概念语义分数,提高了标注精度。在HMM模型里,所有的隐状态可以构成一条一阶马尔可夫链,而每个隐状态代表一个隐藏语义概念,两个隐状态之间的边权重表示它们的语义相关性,隐状态到可观测状态之间的边表示由CNN分类器产生的视觉语义分数。在学习过程中,考虑到真实图像集上语义概念分布的不均衡性,引入了语义概念的权重学习,其在计算发射概率和转移概率的过程中减弱了频繁概念的权重,而提升稀疏概念的权重,于是大大提高了稀疏概念标注的性能。最后,把我们的标注方法HMM + CNN应用于标准标注图像集IAPR TC-12 [11] ,结果表明我们提出的标注方法HMM + CNN标注精度比较高,是自动图像标注的一种有效方法。
2. 隐马尔科夫模型
隐马尔可夫模型(Hidden Markov Model,简称HMM) [12] 可表达离散时间序列状态数据,它的隐状态Xi(隐变量)不能直接观察到,但能通过观测向量Oi序列间接观察到。每个观测向量都是通过某些概率密度分布表现为各种状态,每一个观测向量是由一个具有相应概率密度分布的状态序列产生。所以,隐马尔可夫模型是一个双重随机过程——具有一定隐状态数的马尔可夫链和随机函数集,即两个状态集合与三个矩阵。两个状态集合是指隐状态集{X1, X2, …}和观察状态集{O1, O2, …}。HMM的假设是隐状态X1之间是一个马尔可夫链,对应一个初始状态矩阵π、隐藏状态转移矩阵A = (aij)和发射矩阵B = (bij)。如图1所示,虚线箭头与实线箭头分别表示转移概率aij与发射概率bij,当前隐状态X1 (隐变量)不是独立被确定出来,而是依赖于前x个观测向量的隐藏状态Xi-1。通过使用双重随机过程,HMM模型可以寻找到最合适的隐藏变量序列。在本模型HMM + CNN中,为了简化求解,仅考虑x = 1时候的一阶情况。
假若分别使用隐语义标注w和未标注测试图像I替换HMM模型中的隐状态与可观测向量,则转移矩阵A与发射矩阵B分别体现了语义概念信息与视觉内容信息。我们提出的标注方法HMM + CNN把图像标注过程视为一个关联隐语义检索过程,与经典的标准HMM模型相比较,HMM + CNN不需要传统的复杂的维特比算法,也不需要估算观测向量I的概率分布。
3. 基于HMM与CNN的自动图像标注方法
3.1. 问题描述
我们的标注方法HMM + CNN将一个图像标注过程看作是一个图像隐语义的检索过程。设训练集为∆ = {I1, ∙∙∙, I|∆|},其中Ii表示一副含有若干语义标注的图像。语义标注wi来自于包含|D|个不同语义概念的概念字典D,如“dance”、“horizon”和“flower”。测试集Ω中的图像没有包含任何语义概念标注。给定测试图像I Î Ω,图像自动语义标注(隐语义检索)的目标是在概念字典D中,检索出最相关的语义概念集{w1, w2, ∙∙∙, wK},以描述I的视觉内容。
在检索的过程中,HMM + CNN标注方法能够同时结合视觉内容的相关性与语义概念的相关性,在一个用户查询概念字典D的时候,其目标是希望检索到与未标注图像内容相一致的语义概念。一般情况
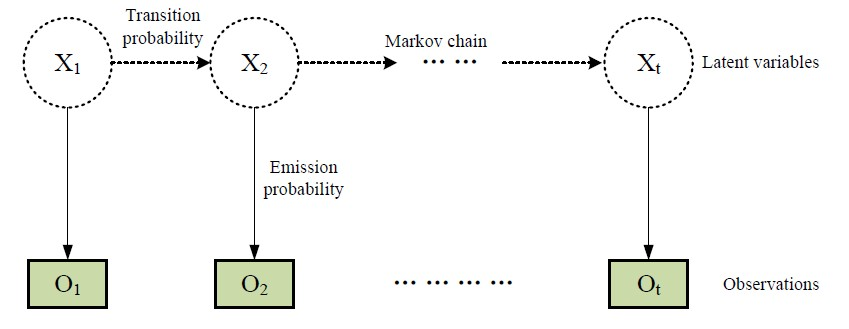
Figure 1. The graphical illustration of hidden Markov model
图1. 隐马尔可夫模型示例图
下,用户提交的检索图像I在一次检索过程中是不变的,于是,未标注图像I Î Ω可以看做是一个可观测向量,随着检索返回语义概念数的增加,该图像I可重复地构成一个可观测序列{I(1), I(2), ∙∙∙, I(K)}。
对于转移概率矩阵A = (aij)中的每一个元素aij表示两个隐状态间的转移数据,在我们的标注方法HMM + CNN中将aij视为两个语义概念wi和wj的关联性。而CNN分类器产生的视觉相关分数可看做是相应隐状态的发射概率bij Î B,该发射概率bij表示了CNN分类器把图像I映射到语义概念wj的过程。根据上述的转移概率矩阵A和发射矩阵B,第t − 1步被检索的隐藏语义概念wi可以关联概率值aij转移到第t步被检索隐藏语义概念wj,被检索隐藏语义概念wj与图像I以发射概率值bij关联。由于I是固定不变的,所以bij简记为bj。第t步隐藏语义概念检索wj依赖两个因素,即t − 1步检索到的隐语义概念wi到该隐语义概念wj的内关联转移概率aij以及视觉关联产生的发射概率bj。从上述分析可知,检索序列中相邻隐藏语义概念wi与wj具有相关的视觉内容与语义概念,整个相互关联的语义概念序列可以描述I的“故事”线索。
图2中给出了HMM + CNN标注方法的结构,矩形框表示一个未标注的检索图像I,圆形框表示被检索的隐语义概念wj (隐状态)。虚线箭头表示隐状态之间的转移概率aij即语义关联性,而实线箭头表示每个隐藏状态的发射概率即视觉相关性bj。每一个隐状态wj可以提供语义概念关联性数据aij与视觉内容相关性数据bj,然后基于HMM + CNN算法实现了对隐语义概念的排序输出。为了叙述方便,表1定义了HMM + CNN标注方法所使用的主要符号标记。
3.2. 发射概率估算
CNN分类器产生的视觉相关性分数可视为相应隐状态的发射概率bj,该发射概率表示了CNN分类器把图像I映射到语义概念wj的过程。任何CNN网络都可融入我们的标注模型,不失一般性,我们选择了近年来一个有影响力的高效CNN模型ResNet [13] 来作为我们的CNN分类器。
传统CNN网络聚焦于单概念分类,而我们的标注任务是一个多概念分类任务,因此为ResNet模型
定义了一个新的多概念softmax损失函数使之适应多概念标注任务。首先,第i张图片I与第j个概念wj的归一化关联概率可定义为:
, (1)
其中,
是图像I在第j个概念wj的离散概率分布,它由ResNet分类器产生。为最小化ResNet预测概率与真实概率的KL距离,我们使用如下多概念softmax损失函数:
, (2)
其中,
是一个图片I的指示器函数:当概念wj在图片I中存在则
否则
。
3.3. 转移概率估算
两个语义概念之间的转移概率aij可视为二者的语义关联概率。共现概念是指以一定频率共同出现于文档中的语义概念。对于共现于图像I中的两个关联语义概念,由于它们共同描述了一副图像的主题或者“故事”线索,所以,可以依据共现率来估算二者的语义关联。
给定隐语义概念wi和wj,在训练图像集∆上考虑使用如下共现度量来计算二者的语义关联概率,HMM + CNN标注模型以此作为两概念的转移概率aij:
(3)
该公式描述了概念wi和wj共现的频率,然后被语义概念wi的频率归一化。它可以被理解为给定含有标注wi的图像I,其包含语义概念wi的概率有多大,其值范围是[0.0, 1.0]。
如果隐语义概念wi是wj的语义近邻,即wi Î R(wj),那么转移概率aij的值为二者的语义关联性,否则,该值被设置为0。由于自转移的概率值很大(ajj = 1),这导致被检索的隐语义概念可能会一直自循环在某个隐状态,导致输出无效的隐藏语义检索结果,所以自转移的概率值ajj被设置为0。综上所述,我们的HMM + CNN标注方法可以抽象为∧ = (N, K, I, S(w), A, B, R(wi), KR)。
3.4. HMM + CNN图像标注算法
给定一个测试集Ω,若任意的一副图像I Î Ω被看做是检索对象,那么概念词典D中的全部语义概念wj Î D可构成被检索数据集。给定一个由检索对象I所构成的一个固定观测序列,HMM + CNN标注方法的目标是返回能恰当描述图像I的最佳隐语义概念序列O = {O1, ∙∙∙, Oj, ∙∙∙, OK},Oj Î D的选择取决于aij和bj两个元素,算法1总结了HMM + CNN隐语义标注的检索方法。其中,p1和p2是待优化参数,且满足约束条件:p1 + p2 = 1,它们表示发射概率(视觉相关性)与转移概率(语义关联性)二者的权重。考虑到真实图像集的概念词典D是不平衡的,即不同语义概念w上的图像集合S(w)的大小是有差异的,不同语义概念的权重p1和p2需要通过在训练图像集上以交叉验证方法获取,而不是直接经验设定为某个固定值。
算法1 HMM + CNN自动图像标注
输入:训练集∆,概念字典D,未标注图片I Î Ω;
输出:标注结果集O = {O1, O2, ∙∙∙, OK}。
1 构建状态转移矩阵A = {aij|i,j = 1, ∙∙∙, N};
2 构建发射概率矩阵B = {bj|j = 1, ∙∙∙, N};
3 初始化标注结果集
;
4 for k = 2 to K do
5 设上一步检索概念Ok−1 = wi,则
;
6
;
7 end for
8 返回结果集O。
4. 实验和评价
4.1. 数据集
评价实验采用了公开标注数据集IAPR TC-12 [11] 。它包含有19,627张图像,每张图像含有1~23个标注,单词表D含有291个语义概念。采用随机抽样,17,665张图像作为训练集,余下1962张图像作为测试集,约75%概念频率低于平均概念频率。我们采用与文献 [8] 相同的评价指标:平均准确率P、平均召回率R、调和均值F1与正召回概念数N+。所有指标值越高表示标注性能越好。
4.2. 实验结果与分析
为观测发射概率和转移概率的语义权重{p1, p2}的影响,考虑使用交叉验证方法:训练图像被随机分成等份5组,当每组图像集交替构成验证集时,其余4组图像集则组成一个训练集。
首先,考虑第一种情况:忽略图像集上语义概念的不平衡性,直接给权重参数{p1, p2}赋经验值,观测其对于标注性能的影响。该方法记为HMM + CNN (without weight learning)。在第二种情况,考虑语义概念分布并非是平衡的,对不同出现频次的语义概念给予相同的经验权重会导致标注性能的下降,因此,对于不同的语义概念wi Î D给予不同权重{p1, p2},全部概念权重组成不同的发射概率向量P1与转移概率向量P2,{P1, P2}可在验证集上用如下方法求出来。
1) 初始化权重向量,即P1 = 0, P2 = 1 − P1;
2) 对于任意的i(1 ≤ I ≤ N):
2a) 对于不同的权重p1 Î {0, 0.1, ∙∙∙, 1}执行算法1获得标注结果集O并记录最大F1性能分数,写入相对应的权重值pmi:P1i = pmi, P2i = 1 − P1i;

Table 2. Performance comparisons of multi-label image annotation
表2. 多标签图像标注性能比较
2b) i值加一,即i = i + 1;
3) 输出权重向量P1, P2。
显然,上述权重提升方法的时间复杂度是O(11 × N)。从实验结果见,第二种情况下的基于权重学习方法的HMM + CNN图像标注方法效果优于第一种情况下的HMM + CNN (without weight learning)标注方法。
表2列出了与最新图像标注方法的对比实验结果。
从表2中可见,我们的HMM + CNN方法超越了其他对比方法,获得了更好的标注性能。与表中最好的对比标注方法NSIDML比较,HMM + CNN方法的平均准确率、平均召回率、调和均值F1分别提高了12%、22%、18%。一方面,视觉内容的相关性(发射概率)可以挖掘视觉内容与语义概念的相关性,另一方面,语义关联性(转移概率)反映出隐标注概念之间的语义关联,其更准确地描述了图像的“故事”线索。在图像标注任务中,这两种类型的相关性都提供了有用的信息,具有一定的互补性,从这个角度上说我们的HMM + CNN方法可提高图像标注的性能。此外,在隐语义标注检索中使用了语义权重学习方法来获得合理的语义权重,所以,在不平衡数据集上,我们的HMM + CNN方法具有更好的标注效果。