1. 引言
任何科学定价决策的基本输入信息都是需求模型,在实际的销售环境中,决策者需要根据企业已有的足够多的历史数据统计得到所需的先验需求模型,由于市场状态是平稳的,可以假设这个需求模型可以在一定程度上反映未来的需求走势,但是由于市场需求波动是存在且无规律的,根据历史数据得到的需求模型将不能很好地反映未来的真实需求。因此,基于完全依靠先验信息的动态定价模型会导致定价策略不能很好地发挥作用。那么决策者应该如何捕捉市场需求的变动,并且反映到动态定价模型中,这是个值得探讨的问题。
国内外针对动态定价研究起步于上世纪70年代,发展于90年代,已取得了很多研究成果。如Golabi [1] 和Bitran [2] 等人,建立了需求不确定下的多阶段动态定价模型:将商品的销售期分为T个阶段,求解各个阶段的最优价格,以实现总销售期内的利润最大化。近年来,学术界引入需求学习进行针对需求波动的动态定价研究。如Besbes [3] 研究了需求函数参数不确定情形下的动态定价方法,给出了需求参数学习的方法,并以此来进行动态定价研究。Araman [4] 将易逝品引入需求学习的定价问题。Lin [5] 针对服务行业将需求学习思想运用到动态定价过程中,通过实时的数据进行连续需求学习。大量研究表明,针对需求预测不准确的问题,需求学习能显著提高商家利润,是解决易逝品需求不确定性的一种有效解决方法。
因此,本文考虑了基于需求学习的方法对不确定需求模型中的参数值进行学习,运用数据同化技术(data assimilation),将先验需求模型和当前观测数据结合,建立动态折扣和库存优化模型,实现动态系统的最优控制。
2. 模型建立
2.1. 算法介绍
本文所用的研究对象为服装,在实际平稳的市场环境中,需求参数波动多呈平稳分布,因此,本文采用经典的卡尔曼滤波算法对线性需求系统的过程参数进行更新学习,提高预测的准确性和定价的合理性。针对服装销售在短周期内需求参数的线性变化,本文利用卡尔曼滤波算法对需求参数进行更新预测。其中,卡尔曼滤波算法(KF)是一种常用的数据同化算法,是由Kalman [6] 在1960年提出,主要包括预测和更新2个过程。1) 预测。已知先验模型进行模型初始化,根据第n阶段的观测数据预测第n + 1阶段的模型状态值。2) 更新。对1)中的预测值进行加权,其中权重由卡尔曼增益确定,然后得到n = 1阶段的更新值,即最优估计值,以此重新初始化模型,重复进行上述步骤,直到系统观测结束。,具体计算过程如下:
1) 预测。令系统状态向量
,那么状态预测为
;
2) 计算卡尔曼增益
。根据第n阶段的观测数据得到测量矩阵
和测量噪声V,其中R是V的协方差,那么
;
3) 计算最优估计值。根据卡尔曼增益
得到现在阶段n的最优化参数估算值:
,其中
,为第n阶段的系统测量值;
4) 更新。为了要卡尔曼滤波器不断的运行下去直到系统过程结束,还要更新第n阶段下
的协方差矩阵
,计算公式为
。
2.2. 基于参数更新的动态折扣和库存优化模型
2.2.1. 动态折扣和库存优化模型建立
本文假设需求函数满足指数形式:
[7] ,假设期初库存为
,由决策者确定,销售期间不考虑补货,n表示不同阶段,m表示总的观察阶段数,
表示各阶段的初始库存量,各阶段的期望日销量为
(销售速率),
为第n阶段折扣系数,各阶段的期望总销量为
,
和c分别为商家提前计划的初始价格和每件成本,
为各阶段的持续天数,h为每件每天的库存成本,
为第n阶段的总库存成本。模型目标为:1) 销售期末库存为0;2) 销售期内的总期望收益最大化。
各阶段的收益和各阶段初始库存为:
(1)
假设需求函数满足以下形式
,其中,
为需求参数,
是系统测量噪声,满足均值0,方差
的正态分布,令
,那么各阶段期望总销量为:
(2)
各阶段总库存成本为:
(3)
各阶段销售额函数:
(4)
那么阶段目标收益函数为:
(5)
则模型总的目标收益函数为:
(6)
2.2.2. 最优折扣求解
这里采用多阶段的动态规划的方法对参数更新的动态定价模型进行最优折扣优化求解。将模型看成多阶段决策问题:取第n阶段初的库存量为状态变量,状态转移方程为
,决策变量为折扣系数
,阶段收益为
,若用
表示从状态
出发,采用最优策略为到第m阶段结束时收益最大化,那么就有如下动态规划模型:
(7)
(8)
1) 2阶段模型求解
当
时,模型目标为:
,先验信息
,可以通过之前的历史数据得到,根据卡尔曼滤波重新更新得到
,以此类推,首先考虑第2阶段,进行
的极值求解:
(9)
根据状态转移方程
和
,因此可以得到
,那么第2阶段的最优折扣为:
(10)
于是可得第2阶段的收益:
(11)
由于需求估计存在误差,第2阶段因参数
的不确定性而引起的期望损失为
,当
时,
不仅会影响
,同时也会影响
的方差。再考虑第1阶段,进行
的极值求解:
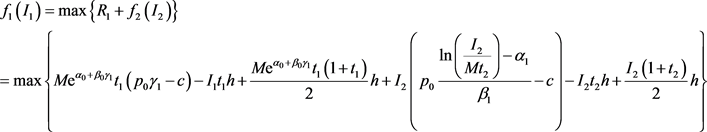 (12)
(12)
为求极值,对
求导,令
,将
,代入
,求解可得:
(13)
2) 多阶段模型求解
当
时,参数更新下的动态规划求解相当困难。但是基于上述动态规划求解过程可以采取一个近似定价策略:要找到每个阶段的最优折扣
,就是要下式最大化:
其中
和
是第n阶段开始时的回归系数,为了防止参数的精确度不高,加入了因预测不准确性引起的期望损失,尽管预测的参数可能是真实参数的无偏差估计,但是由于目标函数是关于参数的非线性函数,因此
中可能存在隐含的偏差,观察公式10和13的结果,可以得出各阶段最优折扣可计算为:
(14)
3. 实证分析
3.1. 数据源
本文的研究数据来源为某服装企业的销售数据,从中选取6类主要季节性商品:羽绒服、短袖T恤、短裤、牛仔裤、长袖衬衫、毛衣进行实证分析。
3.2. 预测误差分析
考虑到数据同化技术需要将观测数据输入模型,本文将选择系统误差最小的同化频率作为销售期内的有效观测时间间隔,以此作为动态定价的时间间隔依据。其中,期望预测值与真实值的误差称为系统误差,这里定义:
(15)
通过计算各参数的平均误差作为系统平均误差。对6类季节性服装进行误差检验,考虑到商家以周为单位进行预算决策,且季节性服装的销售期有限,因此,同化的频率不宜太小或太大,这里选择1~5周作为同化频率进行估计误差对比,结果如图1所示,可以发现,短袖T恤和毛衣应选择1周为观测频率,羽绒服和长袖衬衫应选择为2周,短裤和牛仔裤应选择3周为宜。
3.3. 最优折扣策略计算
以某季节性服装为例,进行考虑库存优化的多阶段动态折扣定价策略计算。其中,初始价格
元,单件成本
元,初始库存
件,单件每日库存成本
元,销售期
周,先验需求函数为
,系统测量噪声
满足均值为0,标准差为0.3的正态分布,即
,参数更新频率为3周,即
天,根据表1的各阶段参数的滤波估计值,计算最优折扣策略,期望销量和期望收益额(元),结果如表2所示。
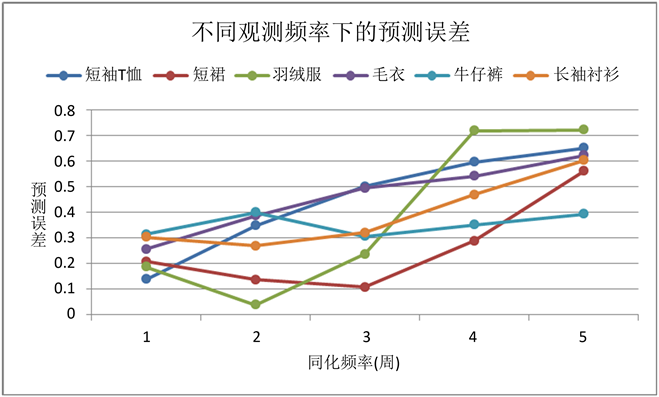
Figure 1. Comparison of prediction errors under different assimilation frequencies
图1. 不同同化频率下的预测误差对比

Table 2. Optimal discount strategy and inventory change in each stage
表2. 各阶段最优折扣策略及库存量变化
4. 参数灵敏度分析
由式子19可以发现,各阶段的最优折扣决策除了与需求参数相关,还与各期初始库存量(
),初始价格(
),库存成本(h),阶段持续时间(
)等有关。这里主要对商家主要关注的销售期期初库存(
),初始价格(
)进行灵敏度分析,以探讨各因素对决策模型的影响。其中,当研究期初库存量对定价决策的影响时,保持初始价格
元,当研究初始价格对定价决策的影响时保持期初库存为2230件,结果如表3、表4所示。
Table 3. Sensitivity analysis of initial inventory
表3. 对期初库存量(I1)的灵敏度分析
Table 4. Sensitivity analysis of initial price
表4. 对初始价格(p0)的灵敏度分析
从表3可以发现,当期初库存量逐渐增大时,开始打折的时机也越来越早,这与实际的商家打折情况相吻合。从总收益来看,商家的期初库存越大,计划销售的量越多,在理想的环境下(最优时机和折扣力度)进行打折,销售收益也越来越大,但是考虑到库存压力和对其他款的竞争压力,商家需要选择一个最优的计划销售量,这里考虑了单件的盈利,如期初库存量在2000件时的单位利润最大,可以作为商家制定销售计划的参考依据。
从表4可以发现,当初始价格逐渐增大时,开始打折的时机也越来越早。一般来说,商家制定的初始价格不会低于成本价格的3倍,当初始价格越高时,打折的空间也会越大,难度也就越大。从收益来看,初始价格对总收益的影响没有明显规律,这与销售进行期间的需求变动和打折策略相关,但从整体来看,当期初库存量一定时,初始价格
时的收益最大,可作为商家制定初始零售价的参考依据。
5. 结论
本文将需求学习应用到服装动态定价领域,针对需求参数的动态变化,运用数据同化算法进行参数学习,建立了动态折扣和库存优化模型,确定了合适的打折频率和打折幅度,最后进行实证研究。研究发现本文提出的模型可以在需求不确定性下通过制定合理的折扣,有效降低商家的库存水平,为打折促销提供科学的依据,并通过期初库存量和初始价格的灵敏度分析,可以找到最优期初库存量和初始价格,为商家的订货量和初始定价的确定提供有力支持,提高了对动态系统的控制水平。