1. 引言
在保险实践研究中,针对特定的投保人,观察到
年的索赔数据
,假设在同一费率级别中每个投保人的风险水平可用一个风险参数
来表示,不同的投保人对应不同的
,且
的分布为
,以此将风险差异进行量化。我们假设
的存在性,理想情形下第
年应当收取个体保费(条件期望)
,而不是净保费
。
Bühlmann (1967) [1] 提出无分布信度模型,用经验数据的线性组合
来逼近
,通过求解下面的期望损失函数:
得到最优信度保费。之后,Bühlmann和Straub (1970) [2] 将无分布信度模型延伸到自然权重的情形。但这些模型均要求所研究的保单数据独立同分布,同时个体风险之间相互独立,我们期待能够找到一种针对特定环境下对保单进行分组并计算每个保单第
年的个体保费
的费率厘定方法。因此,Yeo and Valdez (2006) [3] 通过用随机变量刻画风险之间存在的某种共同效应(例如某种特定环境),在这种特殊结构下研究了信度保费估计,而后温利民等分别研究了信度模型及回归信度模型在共同效应情况下的信度保费 [4] [5] 。更一般地,考虑保单风险之间的相依关系,打破经典的风险独立假设,张强等(2018) [6] 研究了平衡损失函数下具有相依结构的信度估计。
鉴于保险数据经常具有较强的鲁棒性,存在一些具有强影响的离群点,经典的Bühlmann信度模型并不能有效利用这些离群值的数据信息,而分位数方法能够很好地解决这一问题,Georgios Pitselis (2013) [7] 在风险独立性的假设下,用分位数技术首次建立了分位数信度模型,阐述了分位数与经典的Bühlmann信度与Hachemeister回归信度模型之间的联系,并将分位数纳入到这两大经典的信度模型中。本文综合考虑数据鲁棒性及风险之间的特定影响效应,创造性地建立了具有共同效应的分位数信度模型,致力于充分利用所有数据的信息,作出最佳的估计,从而实现保险产品结构的优化。
2. 模型假设与准备
2.1. 准备知识
考虑
份保单合同,对于第
份合同有
年的索赔数据,
,则样本数据构成一个矩阵:
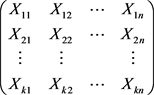
风险由风险参数
进行描述,对任意
,
为概率空间
上的随机变量,令
为
的p−分位数。
在给定风险参数
下,第i份保单的索赔随机向量为
,
,设
为样本
的经验分布函数,则样本P-分位数的估计可定义为:
记
为所有索赔数据组成的列向量,
为样本分位数的估计。我们的目标是通过对样本选取不同分位点,预测每份保单在各分位点第
年的索赔。由于各保单之间存在某一特定效应,我们用随机变量
来刻画此种共同效应,下面给出模型的基本假设。
2.2. 模型假设
假设1:风险之间存在共同效应
,且
假设2:给定共同效应
,风险参数
,索赔样本数据为
,其样本分位数
的条件期望和条件方差如下:
引入下列记号:
2.3. 模型求解
根据信度理论,我们用样本分位数的线性函数逼近最优信度保费,即求解最小化问题:
(1)
式中,
基于样本分位数,
的非齐次信度估计为
,本文利用正交投影法求解最优化问题(1),引入下列引理。
引理1:设
,
为两个随机向量,
在
上的正交投影为
证明见Wen et al. (2009) [4] 。
引理2:设A,B,C,D为适当阶数的矩阵,且A,C可逆,则有求逆公式:
证明:由
即
引理3:在模型假设1和假设2下,有以下结果:
1)
的期望为:
其中
为所有元素均为1的n维列向量。
2) 向量
的协方差矩阵为:
3) 矩阵
的逆矩阵为:
4)
与
的协方差矩阵为
证明:
1)
2) 记
,则
分项计算得:
则有,
3) 根据引理2得
因此,
因为
所以,
4) 因为
,则
引理3证毕。
3. 具有共同效应结构的分位数信度模型
定理3.1:在模型假设1及假设2下,求解最小化问题(1)可得
的最优线性信度估计为
式中,
为信度因子。
其中,
证明:由引理1及引理3得
定理3.1得证。
4. 总结
本文在分位数的视角下,结合信度理论,建立了共同效应结构下的分位数信度模型。通过自由选择样本分位点打破了经典的信度模型中数据鲁棒性的弊端,利用随机变量反映风险之间的共同效应,解决实际应用中保单风险并不独立的情形,得到了最优的信度保费,从而降低经营风险,使得保险产品真正回归到保障本质。
致谢
感谢国家自然科学基金课题“基于分位数回归的信度理论与风险度量的研究”(11861064)的资助,为本研究工作提供了良好的平台;感谢课题组导师在课题研究中无微不至地传道、授业、解惑,使我不断进步;感谢课题组成员对我的帮助、关心,伴我一路成长。
参考文献
NOTES
*第一作者。
#通讯作者。