1. 问题重述
1.1. 问题背景
低保是对低收入家庭的一种保障制度,低保问题事关困难群众衣食冷暖,事关社会的和谐稳定和公平正义,是维持困难群众基本生活权益的基础性制度安排。研究制定合理的低保标准制度能更有效地帮助老百姓摆脱贫困,提高生活质量。
1.2. 问题提出
基于找寻的数据,研究下面四个问题:
(1) 挑选主要计算“低保标准”的指标;
(2) 就某一地区,给出该地区“低保标准”,并给出模型分析与解释;
(3) 分析现行各地“低保标准”的相关性;
(4) 利用(3)分析的结果,给出多元数学模型,并给出模型适应性验证。
2. 模型假设
1) 假设不考虑自然灾害、金融危机等不可抗因素;
2) 假设所查阅的数据不存在误差。
3. 符号说明
符号意义:
:低保标准的六个指标;
:第t年的年低保标准的实际值;
:第t年的年低保标准的预测值;
:第t年居民人均消费支出;
:第t年该地区财政收入;
:参数;
:参数;
:年低保标准的实际值;
:年低保标准的预测值;
:影响低保标准的六个变量。
4. 模型的建立与求解
4.1. 问题一的分析与建模
由于建立低保制度是以地方人民政府为主,实行属地管理,低保标准要由县以上各级地方政府自行制定和公布执行。因此,就必须考虑各地的物价情况及政府的财政状况 [1] 。基于以上考虑,选择如下的“低保标准”指标:1) 地区生产总值;2) 人均消费支出;3) 一般公共预算社会保障和就业支出;4) 居民消费价格指数;5) 商品零售价格指数;6) 政府财政收入。
我们希望在这六项指标中,寻找出影响“低保标准”的主要指标和次要指标。
4.1.1. 模型一的建立及求解
由于影响因素较多,想要通过某种方式计算不同指标的权重,根据权重选择出主要因素和次要因素。
在确定各因素之间的权重时,如果只是定性的结果,常常不为人所接受,运用Saaty等人提出的:一致矩阵法 [2] ,其特点是:不把所有因素放在一起比较,而是两两相互比较,并采用相对尺度,以尽可能减少性质不同的诸因素相互比较的困难,提高准确度。成对比较矩阵中的
用Saaty的1~9标度方法给出。
依次表示:地区生产总值、人均消费支出、一般公共预算社会保障和就业支出、居民消费价格指数、商品零售价格指数、政府财政收入。所构造的成对比较矩阵如下:
利用MATLAB对模型进行编程和求解,得到地区生产总值、人均消费支出、一般公共预算社会保障和就业支出、居民消费价格指数、商品零售价格指数、政府财政收入的权重为0.0906,0.4060,0.1519,0.0552,0.0552,0.2412。
成对比较矩阵的一致性指标CI = 0.0115,一致性比率CR = 0.0092 < 0.1。因此,此矩阵的一致性可以接受。
由此可见,人均消费支出、政府财政收入的权重较大,我们将其选为主要指标。
4.1.2. 模型一的评价与改进
在构造成对比较矩阵是,标度虽有统一标准,但标度的选择仍然具有较大的主观性,而且城市和农村的消费水平、生活方式、生活来源存在较大差异,该模型并未体现出农村与城市的区别之处,因此所求出的权重仅能大概反映出指标的重要程度。我们希望能够运用大量的客观数据,通过一定方式求解出各个指标的权重。
4.1.3. 模型二的建立及求解
我们通过查阅中华人民共和国民政部官网和《中国统计年鉴2017》 [3] ,获取了全国31个省份(包括直辖市)的农村和城市低保标准及其各项指标,由于指标个数较多,且他们之间可能存在着一定的相关关系,我们通过主成分分析进行降维处理,选出主要指标的次要指标。我们所整理数据如表1至表6所示:
我们利用SPSS实现了主成分分析,并获得了如下结果:

Table 1. Urban subsistence allowance standards and indicators
表1. 城市低保标准及各项指标
Table 2. Rural subsistence allowance standards and indicators
表2. 农村低保标准及各项指标
由相关矩阵可以看出,无论是城市还是农村,都提取出了两个主成份,分别是居民人均消费支出和
Table 3. (City) correlation matrix
表3. (城市)相关矩阵
Table 4. (City) component matrix
表4. (城市)成份矩阵a
Table 5. (Rural) correlation matrix
表5. (农村)相关矩阵
Table 6. (Rural) component matrix
表6. (农村)成份矩阵a
财政收入,和一致矩阵法一致。因此,选定居民人均消费支出和财政收入作为主要的计算“低保标准”的指标。
4.2. 问题二的分析与建模
据题目要求,选定吉林省为研究地区,收集了该地区连续9年的年平均低保标准 [4] ,通过研究2008年到2016年的数据建立数学模型,给出该地区“低保标准”的模型。因问题一的研究确定和“低保标准”影响较大的指标为城市居民人均消费支出和财政收入,所以设定本题研究的两个变量为
居民人均消费支出和
该地区财政收入,由于城市和农村的“低保标准”差异性较大,所以该题依然分开研究。
4.2.1. 城市“低保标准”数学模型建立与求解
表7的数据是以时间为序的,由于城市居民人均消费支出和该地区的财政收入等变量与时间有一定的联系,同一变量的不同时间的值之间会出现相关性。该题不再采用用普通的回归模型,考虑自相关性,建立新的回归模型。
Table 7. Urban subsistence allowance standard of Jilin province, per capita consumption expenditure of urban residents and fiscal revenue data of this region
表7. 吉林省城市年低保标准与城市居民人均消费支出及该地区财政收入数据
将2008年到2016年分别编号为1~9,计该地区第t年的年低保标准为
,城市居民人均消费支出为
,财政收入为
,
。
随着城市居民人均消费支出的增加,年低保标准增大,两者存在线性关系,财政收入与年低保标准的关系类似,因此建立多元线性回归模型:
(1)
根据表7的数据,对模型(1)利用MATLAB求解,得到的回归系数估计值及其置信区间(置信水平
)、检验统计量
,F,p,
的结果见表8。
代入(1)得到:
Table 8. Calculation results of model (1)
表8. 模型(1)的计算结果
(2)
残差
见表9。
下面考虑
的自相关性,考虑如下模型:
(3)
是自相关系数,
,
相互独立且服从均值为零的正态分布,
下面进行Durbin-Watson检验,根据模型(2)得到的残差计算DW统计量:
(4)
化简得:
(5)
而
是自相关系数
的估计值
,所以:
(6)
经计算得到
,查DW分布表知检验结果存在自相关,采用模型(3),计算得:
(7)
做变换:
(8)
模型(3)化为:
(9)
比较
和
之后可以认为随机误差存在自相关,将(7)的值代入(8)做变换,得到变换后的
,
,
数据如表10。
利用表10估计模型(9)的参数,得到的结果见表11。
将模型(9)中的
,
,
还原为原始变量
,
,
得到的结果为:
(10)
结果预测与分析,将模型(10),模型(2)的计算值
与实际数据
比较,见表12,可以发现模型(10)在偏差内更适合求解城市低保标准。
Table 11. Parameter estimation of model (9)
表11. 模型(9)的参数估计
Table 12. Calculation values of model (10) and model (2)
表12. 模型(10)、模型(2)的计算值
4.2.2. 农村问题的建模与求解
对于农村问题的研究,初步和城市问题建立相似的模型来研究,农村的变量是否有自相关性由数据来判断。如表13是吉林省农村年低保标准与城市居民人均消费支出及该地区财政收入数据 [4] :
将2008年到2016年分别编号为1~9,记该地区第t年的年低保标准为
,城市居民人均消费支出为
,财政收入为
,
。
建立多元线性回归模型:
(11)
根据表13的数据,对模型(1)利用MATLAB求解,得到的回归系数估计值及其置信区间(置信水平
)、检验统计量
,F,p,
的结果见表14。
将参数估值代入(11)得到:
(12)
残差
作为随机误差
的估计值,判断
的自相关性,模型(12)的残差如表15。
为研究对
的自相关性,考虑如下模型:
Table 13. The annual subsistence allowance standard of rural areas in Jilin province, the per capita consumption expenditure of rural residents and the fiscal revenue data of this region
表13. 吉林省农村年低保标准与农村居民人均消费支出及该地区财政收入数据
Table 14. Calculation results of model (11)
表14. 模型(11)的计算结果
(13)
是自相关系数,
,
相互独立且服从均值为零的正态分布,
。
下面进行Durbin-Watson检验,根据模型(12)得到的残差计算DW统计量:
(14)
化简得:
(15)
而
是自相关系数
的估计值
,因此:
(16)
计算得到
,经查DW分布表知检验结果不存在自相关,即适合农村的低保标准的模型就是简单的线性回归模型(12)。
结果预测与分析,将模型(12)的计算值
与实际数据
比较,见表16,可以发现模型(12)在偏差内比较适合吉林省农村的低保标准。
Table 16. Calculated values of model (12)
表16. 模型(12)的计算值
4.3. 问题三的分析与建模
通过第一题的计算,我们筛选出了计算各地“低保标准”的主要指标,第三题我们选择利用聚类分析方法 [1] ,把低保标准情况相似的情况的省份找出来,使得类别内部省份间差异尽可能的小,类别间的差异尽可能的大,即把31个省域归为若干类,从而更好的掌握全国城市低保的差异情况,来更准确地分析各省“低保标准”的相关性。
4.3.1. 问题的建模与求解
比较题目中要求分析现行各地之间的“低保标准”的相关性,我们选择我们首先选择根据只根据低保标准的数目对全国36个省份和直辖市进行比较,并用EXCEL编程做出相应热图1,图2。
由于某些省份的低保标准数目集中,我们指定的区间并不能完全展现出各省的特征,所以选择以“低保标准”、问题一求出的主要指标(“居民人均消费支出”和“公共预算支出”)以及低保标准和两者的比值,把农村和城市作为一项影响因素,重点分析各省域之间的区别,把全国省份之间的差异问题更加突出,运用聚类分析模型,对全国各省份和直辖市进行分类。
我们可以把全国31个省域划分为四个大类,见表17。
按照不同类别,把全国低保标准的热图绘制出来,见图3。
4.3.2. 结果分析
1) 类别一
类别一所属省市都是经济发达地区。城市低保平均标准和居民消费水平在全国处于领先位置,但低保标准占人均消费水平的百分比农村和城市的差距过大,可见,低保标准制定并未能与所在城市人均可支配收入同步增长,未能充分发挥低保救助工作的作用。
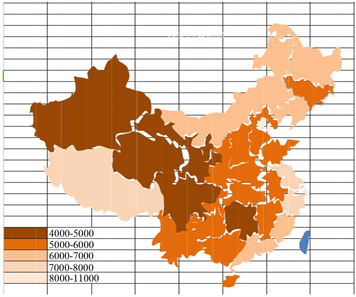
Figure 1. Distribution of national urban subsistence allowance standard
图1. 全国城市低保标准分布
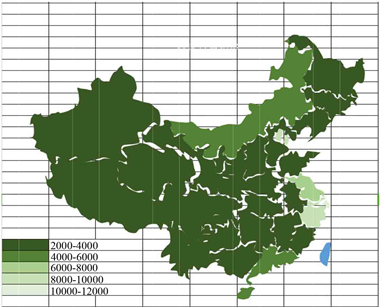
Figure 2. Distribution of national rural subsistence allowance standard
图2. 全国农村低保标准热图
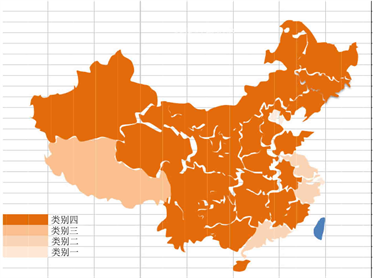
Figure 3. Distribution of national subsistence allowance standard
图3. 全国低保标准热图
Table 17. Classification of the country's 31 provinces
表17. 全国31个省域的分类
2) 类别二
此类经济发达地区所属省域城市低保标准基本都与经济富裕程度相符。
3) 类别三
西藏地区人均可支配收入属于全国最后梯队,但受中央财政支撑,低保标准实施表现较突出,城市低保平均标准、支出水平相对较高。
4) 类别四
第四类地区属于经济不是特别发达的地区,财政收收入较少,而贫困人口多,因此低保平均标准较低,对于这样的经济不发达地区,中央财政就是低保制度的主要财政支柱,理应加大对低保工作的支持力度。
4.4. 问题四的分析与建模
据题目要求,利用问题的结果建立多元数学模型,使验证其适应性。由问题三可知,不论哪种模型分析的结果都与地理位置有很大的因素,所以本题把增加地理位置作为一个新的变量,增加城市或农村作为一个新的变量,建立一个统一的制定低保标准的回归模型。利用问题三聚类分析的结果作为该题区分地理位置变量的依据。该题选取2016年数据进行研究建模,用2015年数据对适应性进行验证。
4.4.1. 模型的建立与求解
定义变量,y表示低保标准,
表示区域发展情况,因为聚类分布是依据各省的城市和农村的低保标准把全国化为四个类别,所以该题表示属于不同类别的具体指标是由该类别的城市和农村的低保标准求平均来近似。
表示城市居民人均消费,
表示农村居民人均消费,
表示该地区财政收入。
建立回归模型:
(17)
根据表18的数据,对模型(1)直接利用MATLAB统计工具箱求解,得到的回归系数估计值及其置信区间(置信水平
)、检验统计量
,F,p,
的结果见表19。
模型(17)的参数估计见表20。
将数值代入(17)得到:
(18)
结果预测与分析,将模型(17)的2016年计算值
与实际数据
比较,比较数据见表21,可以发现模型(17)在偏差内比较适合各省的低保标准。
Table 18. Data of Beijing, Tianjin and Shanghai
表18. 北京、天津、上海各项数据
Table 20. Calculation results of model (17)
表20. 模型(17)的计算结果
Table 21. The true, predicted and residual values of the subsistence allowance standard in 2016
表21. 2016年低保标准的实际值、预测值和残差
4.4.2. 模型的适应性验证
利用模型(17)分析2015年数据,得到结果如表22,发现全国各省的低保标准在一定误差范围内可以使用模型(17)。
Table 22. The true, predicted and residual values of the subsistence allowance standard in 2015
表22. 2015年低保标准的实际值、预测值和残差
5. 模型评价
优点:
1) 本文建立的模型与实际生活紧密相连,对各省低保标准和主要指标进行建模,其结果与实际相符。对民政部门,统计部门都具有很高的参考价值。
2) 模型建立的模型依据的数据来自《中国统计年鉴》以及中国民政部所给出的数据,使得模型的可信度较高。
3) 模型具有一定创新性和灵活性,对各省的情况都符合。
缺点:
1) 对省份的分类不够细致,在实际中应用会有一定误差。
2) 成对比较矩阵,可以实现权重计算,但由于其标度的选择具有较大的主观性,且无法体现出城市与农村“低保”指标的差异性,因此所得出的结果不够具有说服力。
3) 问题二中在针对吉林省研究该地区的低保标准时,由于官网上找不到大量年份的低保标准,所以在研究此问题时的数据量不够大,无法深层次地再研究2016年以前低保标准的适应性。