1. 引言
1930年,Lundberg-Gramer提出了经典的累积风险模型,该模型常用来研究保险公司的分红及破产概率。而为了使得描述的风险模型更加地贴近实际,1984年,Davis提出了更加一般的保险风险模型,他们称为逐段决定复合泊松风险模型。该模型是一般的模型,囊括了多种目前常见的风险模型。在本文中,我们假设保险公司的风险模型是保费依赖余额(逐段决定复合泊松风险)模型,即余额过程为逐段决定马氏过程(PDMP)。PDMP自提出以来就受到金融,保险,随机控制等多个领域的广泛关注,也涌现出了大量关于PDMP的文章。如 [1] - [6] 研究了PDMP的连续和脉冲控制,最优停时,在风险中的应用等。关于保险中PDMP的相关内容可以参考Schimidlli [7] 。随后,PDMP也被应用到最优分红问题的研究中。
最优分红问题最早可追溯到 [8] ,De Finetti在第15届国际精算学大会(纽约)上首次提出了破产前累积期望折现分红的概念,并对离散时间风险模型的最优分红问题进行了研究,并得到最优分红是barrier策略。通常,研究最优分红问题的方法为Schimidlli的经典方法和Muller [9] 的粘性解的方法(关于最优分红的问题可参考Muller [9] )。在2017年,Liu在 [10] 中提出了一种新的理论:测度值生成元理论。本文即运用该理论得出测度值动态规划方程,该方法不要求值函数是光滑的,则我们不需要讨论方程的粘性解。
本文结构如下:第1节建立保费依赖余额的保险风险模型,并给出相应的最优分红问题。第2节给出了值函数的基本性质。第3节通过测度值生成元理论给出了测度值动态规划方程(测度值DPE)。
2. 模型描述
首先给出完备的概率空间(
, F, P),
是所有右连续且有左极限的函数集合。在此空间内,将保险公司的余额X表示为
(1.1)
其中,
为初始余额,
表示到t时刻的索赔个数。索赔额序列
为一独立同分布的随机变量序列,其分布函数为
,并且
和
是相互独立的。索赔到达率
为常数,则下次索赔达到时刻的条件概率分布为
。
表示第n次索赔时刻,在两个连续的索赔时刻间的余额过程可表示为
定义推移算子
,满足
。
为从0时刻到t时刻的累计分红。给定分红策略L,受控的余额过程
可表示为
(1.2)
相应的破产时刻定义为
在任意时刻t,索赔到达率都为
,受控后的条件概率分布不变。
如果L满足下列条件,则称L为可行策略。
1)
是非降且关于自然流
是适应的;
2) 过程
满足
3) 方程(1.2)有唯一强解
。
定义
是所有以
为初始余额的可行策略集。
对每个分红策略
,累积期望折现分红
可表示为
其中
是折现因子。定义值函数
。
通常,当
时,
。
3. 值函数性质
引理2.1:值函数
是非降的,局部Lipschitz连续且满足
。
证明:取分红策略
使
。对任意的
,重新定义一个新策略
,该策略先将
作为分红一次性分给股东,之后有
,则有下列不等式成立
则
,同时可得V是非降的。
下证
。
令
,则有
由于g是单调递增的,有
,则不等式成立且V是局部Lipschitz连续的。
4. 动态规划原理(DPP)及动态规划方程(DPE)
定义
是可测函数
的集合,
满足下列条件:
,方程
有唯一解
;
,
。
下面我们给出马氏策略及马氏策略集合的定义。
定义4.1:如果受控后的余额过程
是强马氏过程,称
是马氏控制;如果
是时齐的强马氏过程,则称L为平稳的马氏控制。
定义
为可测函数
的集合,且
满足
1)
,
。
2) 对任意
,
,有
3) 当
时,
4) 方程
(4.1)
有唯一解
;
通过上述定义及 [10] 定理2.3可得集合
中的函数是马氏策略函数。
引理4.2:假设存在最优平稳马氏策略
及相应的函数
。值函数V满足
(4.2)
其中
。
证明:当最优策略
是平稳马氏策略时,可得
(4.3)
由于
是马氏策略,则等式右边第二部分可以写成
则(4.3)可写为
(4.4)
函数
。下面我们构造一个新的策略L:将
分红策略在第一次索赔到达前为一般策略L,在之后的索赔到达间隔之间为最优策略
。
在新的策略之下,值函数满足
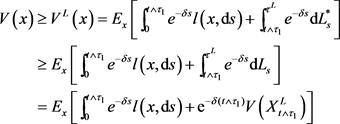 (4.6)
(4.6)
由(4.4)和(4.6),可得(4.2)。
定理4.3:假设存在最优平稳马氏策略
及函数
,则值函数V(x)满足
(4.7)
其中
根据引理3.1, 有
运用分部积分,得
和
则
(4.8)
令
方程(4.8)可写为
。
,根据 [10] 定理2.3知:
,则有
,
。
因此
。
由上可得
关于t是非增的。对于任意
,可得
, (4.9)
其中
另一方面,假设存在最优平稳马氏策略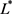 及相应的函数
。运用与(4.9)相同的推导方法,(4.3)可写为
及相应的函数
。运用与(4.9)相同的推导方法,(4.3)可写为
(4.10)
由(4.9)和(4.10),可得
。
对固定的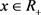 ,上述等式在
时取得最大值等价于
时取最大值。我们可改写(4.7),如下式:
,上述等式在
时取得最大值等价于
时取最大值。我们可改写(4.7),如下式:
(4.11)
其中
方程(4.11)是测度值方程,因此我们可以称之为测度值动态规划方程(测度值DPE)。