1. 引言
多视图学习(MVL)可用于表示多个不同特征的数据集 [1],不同的特征经常互相补充信息,与传统的单视图学习相反,MVL分别为每个特征视图构造一个学习函数,然后通过利用相同输入数据的冗余视图共同优化学习函数。到目前为止,已经提出了许多MVL算法,可以分为两组:协同训练 [2] 和协同正则化算法 [3]。协同训练算法通过迭代,最大化多个不同视图上的学习函数,以确保在相同数据的一致性。在协同正则化算法中,需要最小化不同视图学习目标函数中的正则项,典型的方法包括稀疏多视图SVMs [4],multiview Laplacian SVMs [5],多视图矢量值多重正则化方法 [6]。
半监督学习是一种综合学习方法,它使用少量标记数据来训练初始分类器,并使用大量未标记数据来进一步提高初始分类器的性能,最终实现准确学习。在学习过程中,学习机在训练过程中使用的样本是一个混合样本集,标签样本较少,未标记样本较多。它不仅利用标记样本的优点来精确描述单个样本,而且还可以发现未标记样本在整个样本集中的重要作用 [7]。
支持向量机(SVM)是一种机器学习方法,主要针对小样本分类问题,遵守结构风险极小化原则,获取全局最优解。1982年Vapnik首次提出支持向量机 [8],他将支持向量机归结为一个二次型方程求解问题。其学习的基本想法是求解能够正确划分训练数据集并且使得几何间隔最大的分离超平面。在近几年的研究中,支持向量机在人脸检测、语音识别、文字识别、手写识别、图像处理等研究方面取得了很多研究成果并受到了许多领域学者的关注。因此,研究也从最初的简单模式发展到各种互补应用。研究人员通过添加函数、变量或系数来对公式进行变形,以生成具有独特优势或一系列应用的新算法,例如:B. Schlkopf等人提出的γ-SVM算法 [9],主要通过γ参数控制支持向量的个数和误差;Lee等人通过引入光滑函数来近似正类样本标签从而提出一种光滑支持向量机(Smooth SVM, SSVM) [10],Mangasarian等人提出的一种拉格朗日支持向量机(Lagrangian SVM, LSVM) [11],Fung等人提出的近似支持向量机(Proximal SVM, PSVM) [12],以及Lee等人提出的约简支持向量机(Reduced SVM, RSVM)等 [13]。
半监督支持向量机 [14] 是一种能够同时兼顾标签与无标签样本的学习方法,因而半监督支持向量机的学习方法在处理大规模数据识别与分类的过程中处理良好。半监督支持向量机最初应用于文本分类 [15],研究人员之后提出了用于解决半监督支持向量机目标函数非凸问题的一系列方法,主要的研究方法有:梯度下降法(Gradient descent) [16];凹凸法(Convex-Concave Procedure) [17];确定性煺火方法(Deterministic annealing) [18] 等。
本文提出了一种基于多视图的双支持向量机的半监督学习方法,此方法将双支持向量机 [19] 与半监督多视图 [20] 学习相结合。给定训练集,将训练集分成两个视图,分别给视图一和视图二找两个非平行的超平面,构造两个二次规划模型,求解相应对偶问题,每个视图分别得到一个超平面,并可以求出决策函数。事实上,基于多视图双支持向量机半监督学习方法是对数据集进行降维。数据表明,与双支持向量机相比,多视图双支持向量机半监督学习方法训练的耗时更少,缩短了运行时间,减少了计算复杂度,有较高的准确率。
本文结构如下:第2节介绍了支持向量机及半监督多视图学习的基本思想;第3节介绍了基于多视图双支持向量机半监督学习的优化模型推导及算法;第4节对基于多视图双支持向量机半监督学习方法进行人工数据和UCI数据的数值实验,并与其它的分类算法进行比较;第5节给出一些结论及展望。
2. 相关工作
2.1. 支持向量机
对于训练集
,其中,
是输入的样本点,
是输出的标签。线性的标准支持向量机要寻找一个超平面f(x)将两类点分开。
(1)
其中,
,
分别是超平面的法向量和截距。引入松弛变量
,标准支持向量机的矩阵形式可以表示为:
(2)
其中,
,
是惩罚参数,
和
是相应的维数为的1向量。我们通过求解(2)式的对偶问题可以得到使得
和
,从而可以得到两个平行的支持超平面
和
。
2.2. 线性可分的双支持向量机
对于训练集
,其中
是输入的样本点,
是输出的标签。
双支持向量机 [19] 寻找两个非平行的超平面
和
使得其中的一个超平面离一类样本点尽可能近,而离另一类样本点尽可能远,反之亦然。
(3)
其中,
和
分别是两个非平行超平面的法向量和截距。引入松弛变量
,线性双支持向量机的模型为:
(4)
和
(5)
其中,
,
,
是惩罚参数,
和
是相应维数的单位向量。
简单的说,双支持向量机是一对二次规划问题,对每个小的二次规划问题构造拉格朗日函数,求解对偶问题,可以得到
,进而可得到双支持向量机的决策函数:
(6)
其中,
分别对应正负类标签
。
2.3. 线性不可分的双支持向量机
显然,并不是所有问题都是线性可分的,对于非线性分划问题,我们可以选择一个适当的内核
,用曲面
和
代替平面
和
。
(7)
其中
,定义
和
,根据2.2节可构造优化问题如下:
(8)
和
(9)
其中
是惩罚参数,
和
是相应维数的单位向量。构造拉格朗日函数求解对偶问题,便可得到其决策函数。
2.4. 半监督多视图学习
多视图用于表示数据的不同特征集,本文研究的均为双视图。在多视图学习算法中,给定有标签数据集
和无标签数据
,任意一个数据点
我们都可以分成两个视图
和
,即
,其中
,
,则目标函数可以表示为
,
和
分别为两个视图下的目标函数。半监督多视图学习方法中,在协同正则化最小二乘方法下的目标函数为:
(10)
其中,
是平衡两个视图的参数,
,
是正则化参数,
是耦合参数,用于调节无标签数据的兼容性。
根据表示定理(10)式可表示为:
(11)
其中,
和
是核函数。
和
可以通过下列线性方程组求出:
(12)
其中,
和
构成的对角矩阵,
和
是核函数
和
的格拉姆矩阵。
3. 基于多视图双支持向量机的半监督学习方法
针对分类问题,本文提出了基于多视图双支持向量机的半监督学习方法,此方法将双支持向量机应用到多视图半监督学习中。给定训练集
,其中
,需要找到与
对应的输出值
和在多视图双支持向量机中的决策函数:
本文提出的多视图双支持向量机半监督学习方法是将(2.2)节中的矩阵
分别从两个视图进行描述,得到线性可分的多视图双支持向量机的半监督学习(MV-TWSVM)的优化模型为:
(13)
和
(14)
其中,
和
,
和
表示数据点的数量,v表示视图的个数,
,
,
,
是参数,
,
,
表示相应维数的单位向量
,
是损失项。
对(3.2)式引入拉格朗日乘子并构造拉格朗日函数为:
(15)
对
的分量求导并令其为0得:
(16)
(17)
(18)
(19)
(20)
(21)
(22)
(23)
(24)
(25)
(26)
(27)
由(16)和(18)得:
(28)
由(17)和(19)得:
(29)
定义
令
(30)
由(28)和(29)可到:
(31)
(32)
由(31)和(32)可解得:
(33)
(34)
由(33)式(34)式及KKT条件可以得到MV-TWSVM1的对偶问题(DMV-TWSVM1)
(35)
其中
同理,对MV-TWSVM2引入拉格朗日乘子并构建拉格朗日函数:
(36)
(37)
定义
(38)
由(36) (37)和(38)可解得:
(39)
(40)
由(39)式(40)式及KKT条件可以得到MV-TWSVM2的对偶问题(DMV-TWSVM2):
(41)
其中
由上述过程可导出如下算法:
算法3.1:多视图双支持向量机半监督学习方法:
输入:训练集
;
输出:决策函数
;
1) 输入训练集
,
,选择参数
;
2) 计算(35),(41)得到
和
;
3) 计算(33),(34),(39),(40)得到
;
4) 由(30),(38)得到
;
5) 得到决策函数。
4. 数值实验
在本节中,将本文的方法MV-TWSVM与TWSVM进行比较。本文的数值结果是在内存4.00 GB,64位操作的Windows7系统中用软件MATLAB,R2014a运行得到的。
4.1. 人工数据
本节图1中,月牙型数据为视图1,由直线
和
生成的样本点加入白噪声得到的数据集为视图2。图中直线是用MV-TWSVM得到的两个视图下的分划线。可以看出分划线很好的表示出了数据的分布,并且有较高的准确率,视图1的准确率达到83.6759%,视图2的准确率达到99.3781%。
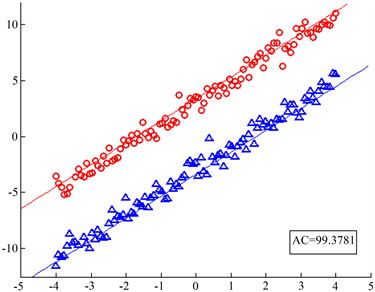
Figure 1. The left figure is view 1, and the right figure is view 2. The line in the figure is the partition hyperplane obtained by MV-TWSVM calculation of artificial data set
图1. 左图是视图1,右图是视图2。图中直线是MV-TWSVM计算人工数据集得到的分划超平面
4.2. UCI数据
在UCI数据上找了Australian,pima,German,spectf,parkinsons,breast六个数据集,表1是数据集的详细信息,其中数据Australian,pima,German选用了该数据的百分之三十进行数值实验。用本文提出的方法对六个数据集计算正确率,并与TWSVM进行比较,如表2。表中加粗的部分正确率较高。
表2是线性的TWSVM,MV-TWSVM对所有数据集计算的正确率,表格分为两部分,第一部分是TWSVM方法,第二部分是本文的方法,其中第一表示TWSVM方法下的正确率,第二列表示在视图1下的正确率,第三列表示在视图2下的正确率,第四列表示原始数据的正确率。奇数行表示将数据集前一半作为视图1,剩余部分作为视图二;偶数行表示将数据集随机分成两部分,一部分作为视图1,另一部分作为视图2。表中可以看出数据spectf,Australian,pima在本文提出的方法下正确率较高。
当我们选择不同比例无标签的数据点时,正确率也会不同,如表3。表3分别取了50%,80%,90%,无标签的数据点,计算正确率和耗时。从表中可以看出,数据集spectf,parkinsons,breast,Pim-a,German,的无标签点增多时,在本文的方法下正确率增大。
此外,本节还对MV-TWSVM与TWSVM进行了时间耗时比较,如图2,数据集仍然是Australian,pima,German,spectf,parkinsons,breast 6个数据集,从图中可以看出,MV-TWSVM比TWSVM耗时少很多,从而说明MV-TWSVM对数据降维事实相符。

Table 1. The details of the data set
表1. 数据集的详细信息
Table 2. The accuracy of linear TWSVM, MV-TWSVM for all data sets (mean (std)%)
表2. 线性的TWSVM,MV-TWSVM对所有数据集计算的正确率
*是指用该数据集的33%进行数值实验。黑体表示几个方法中最高的正确率。
Table 3. The accuracy of MV-TWSVM in computing unlabeled data sets with different ratios (mean (std)%)
表3. MV-TWSVM 对不同比率的无标签的数据集计算的正确率
*是指用该数据集的33%进行数值实验。黑体表示几个方法中最高的正确率。
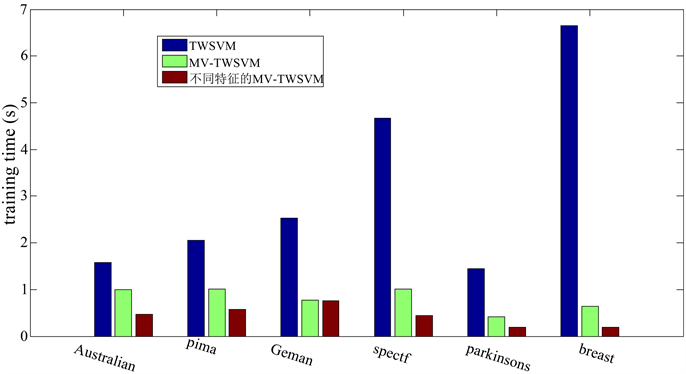
Figure 2. Comparison of training time between TWSVM and MV-TWSVM under different characteristics
图2. 不同的特征下,TWSVM与MV-TWSVM的训练时间之间的比较
5. 结论与展望
本文将双支持向量机应用到多视图半监督学习中,将数据分成两个视图进行描述,降低了数据的维数,减少了计算的复杂度,有效地缩短了运行时间。对于不同的数据,多视图双支持向量机半监督学习方法取得了较好的正确率。
进一步,我们将研究如何选择不同的核函数将线性划分推广到非线性划分。另外,现有的多视图学习方法实际上是双视图,如何推广到更多视图上的研究也是一个需要考虑的问题。