1. 研究背景
当今社会物联网科技发展速度迅猛,伴随着全球汽车行业的飞速发展,车联网技术渐渐进入我们的视野,越来越多的专家、企业对车联网更加关注。同时道路交通行业作为我国现代运输方式的重要组成部分,其运输方式的安全性能、运输效率以及运输能源的使用都将直接关系到国家的发展 [1] 。车联网系统往往通过在车辆仪表台安装车载终端设备,实现对车辆所有工作情况和静、动态信息的采集、存储并发送。车联网系统一般具有实时实景功能,利用移动网络实现人车交互。车联网获得的数据可以用于对车辆行驶轨迹的分析,通过其了解道路交通状况,合理规划外出行程,缓解交通压力等。但是由于地理环境影响以及仪器故障等原因使得车联网采集的数据往往会出现异常,所以我们需要对车辆行驶轨迹数据进行分析与挖掘,对异常数据进行智能校正 [2] 。
2. 问题分析
针对各种可能的因素会造成车联网采集的数据缺失或者数据异常,所以首先对轨迹数据做预处理。车联网在工作过程中,由于传感器所采集的数据量是巨大的,常常会造成大量数据冗余,通过预处理去掉轨迹中经纬度坐标值一直无变化的点,然后对轨迹数据中异常偏移的点进行筛选剔除 [3] 。
预处理去除错误以及冗余数据之后,由于车辆在行驶过程中经纬度坐标变化比较连续,基于运输车辆路线是走最短路径,所以根据电子实时地图按照最大概率进行路网匹配,通过编写程序代码,可得到补全之后车辆完整的行驶路线图。
3. 建立模型
3.1. 轨迹数据预处理
运输车辆的运动轨迹在地理空间通常可以由一系列按照时间序列分布的坐标点来表示,它们的轨迹可以由
表示,其中每个点由对应的经纬度坐标和一个时间戳组成,由
表示。由于各种可能的因素会造成被记录的点数据缺失或者数据异常,首先应对轨迹数据做预处理 [4] 。
3.2. 去除数据冗余
传感器采集的数据量是巨大的,但是往往也会造成大量数据冗余,例如在分析车辆轨迹时,可以去除掉经纬度坐标值一直无变化的点,在这一段时间内说明运输车辆是未运动的。以此筛选后的数据在地图上进行标注时会极大的提高效率。
3.3. 样条插值
计算运输车辆需要经纬度坐标变化比较连续,减少毛刺现象的产生,对存在缺失的异常值采用样条插值的方式。数学上将具有一定光滑性的分段多项式称为样条函数,具体的说给定区间
的一个分划:
如果函数
满足在每个小区间
上
是m次多项式且有
在
上具有
阶连续导数,则称
为关于划分
的m次样条函数,其图形为m次样条曲线。
3.4. 噪点过滤
在空间路径不是特别精确的情况下,噪点过滤算法的作用是删除或者修正轨迹中位置存在有错误的点,如图1所示,存在偏差过大的点,需要在开始数据挖掘任务前先将其过滤,主要从三种过滤算法入手:均值过滤,卡尔曼过滤和基于启发式的异常检测模型。
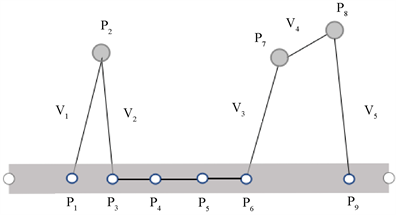
Figure 1. Schematic diagram of path noise
图1. 路径噪声示意图
1) 均值过滤。如果某一个异常点对于它前后两个观测点位置偏移量极大时,可以采用均值过滤的方法,使车辆在单位时间内的位移距离更加合理。第K个点的位置估值可以表示为:
采用均值过滤的方法可以去除明显不合理的噪点。不过当出现连续的噪点时,会导致估值与实际值的差距增大,会使均值滤波效果变差。
2) 卡尔曼滤波过滤。卡尔曼过滤根据测量值和运动趋势得到轨迹估值,卡尔曼过滤基于轨迹符合线性模型的假设,根据运动物体转移概率矩阵的关系,对异常值的采集点预测并行校正 [5] 。
卡尔曼滤波通过系统输入输出的观测数据对系统状态进行最优的估计,能够实现实时预测的卡尔曼滤波动态轨迹预测的状态方程为:
其中
表示为系统的状态向量,
表示为状态转移矩阵,可以用来描述前一时刻到当前时刻下的运动状态转移方式,其中
为干扰转移矩阵,
表示运动模型的系统状态噪声。
观测方程为:
其中
为观测向量,描述了在某个时刻的观测值,
在本文中为一维的观测矩阵,
为运动估计过程中的产生的观测噪声。
卡尔曼滤波算法的核心是运用递归算法来达到最优状态估计的估计模型。主要是利用前一时刻的估计值和现时刻的观测值来更新当前状态的变量的估计,基于前k个观测值得到在k时刻下的最优状态估计,计算最小方差计算的公式表示为:
对时间和状态分别进行更新。时间的更新过程是根据前一时刻最优状态估计预测出当前时刻的状态,同时也要更新预测状态的协方差,时间更新方程为:
当预测出轨迹点后,根据观测值和预测值通过观测更新方程来推测出最优估计点。
3) 基于启发式的异常检测模型。
第一条:该类模型基于GPS坐标点与其后续点之间的时间间隔和距离间隔来计算出运输车在每个点的行驶速度。
如果一个路段相邻两个采集的经纬度坐标值的距离与时间间隔的比值,表示为:
当
明显大于某个阈值即高于200 km/h时,认为为异常点。
第二条:如果相邻两个GPS数据小于10米的点被认为是异常点。
第三条:GPS数据的速度低于5千米每小时和相邻两条GPS数据的时间大于1分钟为异常点。
第四条:如果一条轨迹最多有4个GPS数据则被认为是异常数据并删除。
3.5. 基于隐马尔科夫的地图匹配算法
地图匹配就是通过车辆的行驶轨迹和电子地图数据库中的道路网进行比较,并结合车辆原来的运行趋势,在地图上找出相近的路线,然后将实际定位数据映射到直观的显示地图上,如图2所示。
Step 1:确定参数:
HMM的5个基本因素,由状态变量数,观测变量数,状态转移矩阵,观测概率矩阵,初始状态概率向量组成 [6] 。
1) 确定观察变量。从车联网采集的数据中得到的位置信息(包括经度,纬度);
2) 隐常状态。此时在路网上的运输车的实际所在位置;
3) 观测概率。观测经纬度离旁边道路近,那么真实点在这个路段的概率越大 [7] ,假设服从高斯分布设有:
4) 状态转移概率。在两个时间点候选路段的转换概率:
,
5) 状态转移矩阵A:
是时刻t + 1时所在路段,
是时刻t所在路段,
有三种状态,当
为1时,相邻,
为为无穷大时,不相邻,
等于0时,在同一路段。
Step 2:Viterbi算法求解
原理基于动态规划利用概率最大找最优路径,其递推公式为:
其中
。那么定义在时刻t状态为i的所有单个路径中概率最大的路径的第t − 1个结点为:
4. 实验求解
图3为车联网系统采集到某辆运输车行驶轨迹的经纬度坐标所做出的行驶路线图,从图3中可以明显的看出行驶路线中存在大量的异常值,由于一辆车的速度等方面是有限的,所以短时间内不会在经纬度路线图上面有很大的变化(尖端毛刺),所做出的路线图应该是平滑的才符合实际情况。
由于各种可能的因素会造成被记录的点数据缺失或者数据异常,所以首先对轨迹数据做预处理后。根据上述的异常点检测模型的检测方法,对轨迹数据进行噪点过滤,剔除异常点后路线图如图4所示。
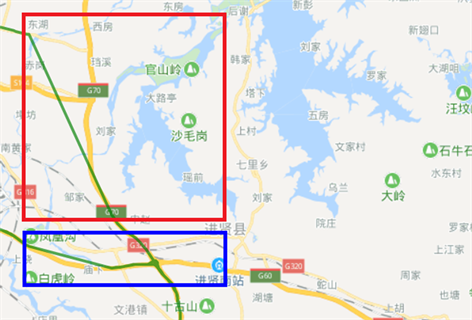
Figure 4. Removing the anomaly data graph
图4. 去除异常数据图
预处理去除异常以及冗余数据之后,由于车辆在行驶过程中经纬度坐标变化比较连续,并且考虑到运输车行驶方向的趋势,再结合实时电子地图,采用基于隐马尔科夫模型的地图匹配算法可得到补全之后的路线图如图5所示。
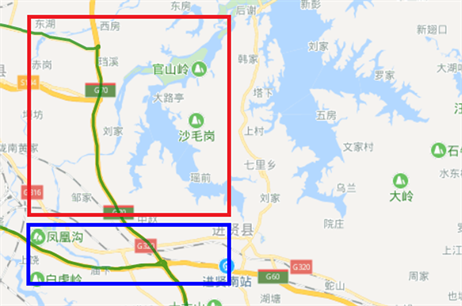
Figure 5. Map matching algorithm after processing
图5. 地图匹配算法处理后
从图形中可以看出,地图匹配算法的补全效果的非常好,减少了许多毛刺,能较好的将缺失路段补全,非常贴合实际情况路线。
5. 总结
本文通过实验验证了异常点检测模型的检测效果比较好,能迅速找到轨迹数据存在漂移的地方,对异常点合理的进行剔除,并且基于隐马科夫模型的地图匹配算法根据车辆行驶方向的趋势并且同时结合电子地图信息,能大概率的将偏离数据匹配到路网上,得到的轨迹路线图效果较好。但是本处理方法也存在一些问题,利用地图匹配算法需要联网更新实时电子地图,效率偏低,对轨迹的匹配仍然存在一定的误差。