1. 引言
随着文献数量的急剧增长,信息检索技术已经成为广大科研工作者和技术从业者获取知识的一个重要途径。现代搜索引擎技术有两个核心概念:智能程度和自然程度。智能程度是指理解用户的意图和文档内容,然后快速、准确的找出相关答案。自然程度是指根据用户输入的搜索请求,把搜索结果自然地、清晰的呈现给用户。提升搜索引擎的智能程度和自然程度,具有提升用户检索效率、使用体验,增加系统粘性的作用。
传统的文献搜索引擎通过对文献数据进行全文索引,基于关键字匹配在语料集中进行检索。由于只涉及词语的匹配,所以检索效率高,但是缺点也很明显,完全依赖用户的查询词,缺少语义分析和扩展能力,难以保证较好的检索性能。文献检索还具有多实体和查询面向问题–方法两个特点。如查询“deep learning for information retrieval”,就包含“deep learning”和“information retrieval”两个概念实体。传统的基于关键字匹配的方法难以准确理解科学概念实体含义,这是造成查询误差的一个重要因素。因此,基于知识库的语义检索近年来成了文献检索的一个重要研究方向。然而,这些工作在利用知识库时没有考虑到查询实体间的内在联系,仅将实体作为单字补充信号改善检索效果。这样会导致检索结果更容易倾向于包含单个高频实体的文档,而不是同时包含多个不同实体的文档。另一方面,科学文献检索中用户信息需求可以分为两类:1) 面向问题,即查询某个科学领域问题、该问题的引申;2) 面向方法,即不限定具体的科学问题,而是查询某一类技术方法的应用。现有框架均没有考虑到两种检索需求的区别,需要用户在检索结果中进行二次查询或人工甄别。
为了解决上述问题,本文提出了一个基于实体依赖建模的检索模型。模型在 [1] 基础上改进,对用户查询语句中的实体间的依赖关系进行了建模。同时,为了对用户的查询意图进行解析,对于文档,我们抽取了类型信息。实体类型反映了实体在文档语境下表述的是问题还是方法信息。由于查询中实体类型难以得到,本文提出一种基于伪相关反馈方法对用户查询类型进行估计。通过解析出用户的问题方法和需求表述,能够从上述两个角度解释用户查询意图,从而对于不同的查询意图能够给出更加精确、细粒度的检索结果。
2. 相关工作
2.1. 学术搜索引擎
文献检索的现实需求推动了许多学术搜索引擎的发展。CiteSeerX [2] ,ArnetMiner [3] ,PubMed [4] ,Microsoft Academic Search (MAS) [5] 等文献搜索引擎中大量应用数据挖掘技术、自动信息抽取技术、推荐技术改善用户检索体验。如MAS通过建立文献知识图谱,可以在检索结果页给出查询相关研究主题及领域相关作者,提供更丰富的结果展示。然而上述大部分系统的研究侧重于学术数据的分析任务,例如文献知识图构建 [5] ,文献重要性建模 [6] ,文档摘要 [7] ,研究者社群关系 [3] 等等,科学文献的检索算法仍具有很大的研究价值。
2.2. 基于实体的检索模型
实体(例如人,位置或抽象概念)是用于组织和检索信息的最小自然单元。有研究发现,超过70%的Bing查询和超过50%的Semantic Scholar文献查询与实体相关 [8] [9] 。随着知识图谱相关技术的逐渐成熟,越来越多的工作研究如何利用实体信息改进检索算法。
一种直觉的方法是利用外部知识库中实体相关信息(实体描述,属性等)去增强用户查询,也即查询扩展。He等 [10] 将维基百科中的实体描述用作伪相关反馈语料库以获得更清晰的扩展术语。Dalton等 [11] 使用查询相关实体属性的文本字段扩展查询,并基于扩展文本生成更丰富的排序特征。另一类利用实体的方法是试图将查询和文档都映射到同一个实体空间进行相似度比较。Liu和Fang [12] 使用查询及文档中的实体来构造潜在的实体空间,然后在高维实体空间内计算查询映射和文档映射的相关度。最近的趋势是构建基于实体的文本表示,并将其与传统的基于单词的表示相结合进行检索。Xiong等 [9] 提出使用实体向量来计算查询和文档的相似度,以提高基于单词的检索模型效果。
3. 基于实体依赖建模的检索模型
本节将详细介绍我们提出的基于实体依赖的检索模型。如前文所说,本模型是 [1] 提出的MRF检索模型的一个扩展,因此我们先简要介绍MRF检索模型,再介绍我们的扩展方法。
3.1. MRF检索模型
马尔可夫随机场是无向图模型,它提供了一种紧凑,稳健的联合分布建模方法。在信息检索领域,常常希望建模查询
与文档D的联合概率。MRF检索模型假设查询和相关文档组成的<查询,文档>对存在一个潜在分布,也即从这个分布中采样出来的查询和文档都是相关的。MRF检索模型则是建模查询Q和文档D的相关性。
一个马尔可夫随机场是由一个无向图G,以及定义在图G的团(clique)上一系列势函数(potential function)组成。其中图上的节点表示随机变量,边表示变量间的依赖性。一个马尔可夫随机场需要满足马尔可夫性质,即网络中每个节点v都条件独立于其邻居节点给定时的v的任意非邻居节点子集。
给定一个图G,以及势函数
和参数向量
,则定义在Q和D上联合概率为:
其中
是归一化因子,为了便于计算势函数
通常取指数函数
,
则是定义在团c上的是实值特征函数。
对于给定查询Q如何与文档D构建无向概率图,原始检索模型给出了三种方式:完全独立(fully term independency),序列依赖(sequential term dependency)和完全依赖(full term dependency)。分别对应于查询项之间完全独立,序列依赖,以及完全依赖的情况,如图1:
MRF模型的联合概率分布通常基于无向图上的最大团参数化,但用于检索模型时,这样的方式太过粗糙。这里为了在更细粒度的水平上将特征函数与团相关联,同时保持特征的数量,从而保持参数的数量。对于上述定义的三种类型的团,每个定义一种特征函数。
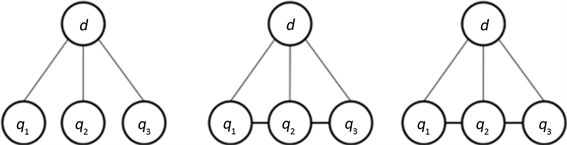
Figure 1. Three dependency modeling approaches
图1. 三种依赖建模方式
3.2. 检索框架
上一节节中我们简要介绍了MRF模型,本模型是在MRF模型的基础上,引入实体信息的一种扩展模型。
原始的MRF模型主要是对查询词的三种不同类型的依赖关系进行建模,即完全独立、序列依赖和完全依赖,分别对应于计算图
上三种不同类型团的特征函数。在本模型中,我们加入一种新的节点类型-查询实体节点
,并对由
构成的概率图G计算联合概率。如图2为加入实体集E后的MRF结构,查询实体E是由多个实体
组成,由查询经过实体链接技术抽取得到,在这里查询实体和查询词两部分的内部元素间采用相互独立关系。

Figure 2. MRF probabilistic undirected graph containing query entities
图2. 包含查询实体的MRF概率无向图
依据MRF原理,对于包含
的概率无向图G,我们类似的定义查询Q、文档D和查询实体E的联合概率为:
最终我们使用条件概率
作为最后的文档检索得分:
(1)
在这里我们可以把团分为两个大的部分。第一部分为文档D与查询词Q之间的团集
,即满足前文所述的查询词完全独立、序列依赖、完全依赖假设的团集。第二部分为文档D与查询实体之间的团集
,这一部分的团集类型以及对应的特征函数将在3.3和3.4节详细说明。相应的,我们将公式简化为如下:
(2)
3.3. 实体依赖模型
参考查询词依赖建模的方式,对于查询实体的依赖建模也可以遵循上述不同的依赖假设,即完全独立、序列依赖、完全依赖假设。对应于上述假设,分别定义三种团集,如表1:

Table 1. Entity dependency type definition
表1. 实体依赖类型定义
对查询实体建模需要考虑到实体的特性,例如每个查询实体本身就是一个完整的语义单元,每个实体可以是单字、双字或者多字短语等。如图3,查询经过实体链接工具标注后得到4个不同实体
,虽然在原始查询中它们并不是连续的,但我们认为在实体层面上它们是连续的序列。同样的可以得到文档实体序列。那么依据表1中定义,有
,
,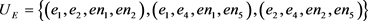 为只考虑两个实体时的完全依赖匹配团集。在本模型中我们只使用完全独立和完全依赖假设,而忽略了对于序列依赖关系的建模。下面将结合实例对上述选择进行详细阐述。
为只考虑两个实体时的完全依赖匹配团集。在本模型中我们只使用完全独立和完全依赖假设,而忽略了对于序列依赖关系的建模。下面将结合实例对上述选择进行详细阐述。
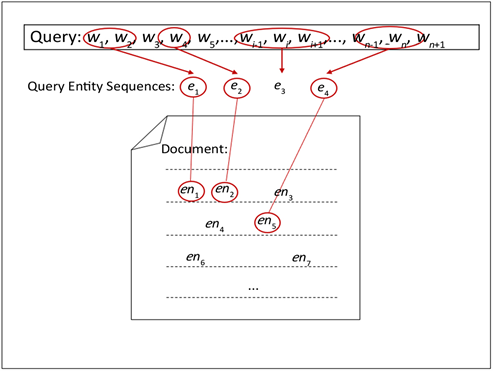
Figure 3. Examples of query and document entity clique set matching
图3. 查询和文档实体clique集匹配示例
在科学文献检索领域,除却题名、作者和研究机构等相关字段的简单查找,用户需要根据自己的检索需求提取关键字,然后组合形成最终查询。如查询“基于深度学习的信息检索”。其中“深度学习”和“信息检索”两个概念实体,表述了用户不同的信息需求。直观上,这两个实体在文档中出现次数越高则文档越相关。
集合上计算的正是文档对不同信息需求匹配的程度。然而单纯依赖于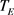 集合上的结果进行排序,会导致检索结果更容易倾向于包含单个高频实体的文档,而不是同时包含多个不同实体的文档。
集合上的结果进行排序,会导致检索结果更容易倾向于包含单个高频实体的文档,而不是同时包含多个不同实体的文档。
和
都体现了实体的共现关系,但这里不使用
团集,这是基于以下两个因素的考虑:1) 由于实体本身为一个独立语义单元,实体与实体之间序列依赖关系并不明显,一个常见的例子是对于多关键词罗列的查询,如“CRISPR/Cas9,ZFN,TALEN”,替换关键词之间的顺序,并不影响查询结果。2) 受限于实体识别精度,查询中识别出的实体并不完备,实体间可能有未识别出的实体。
3.4. 特征函数定义
目前为止,我们在由
组成的无向图上定义了5种不同的团集,其中T、O和U与原始MRF模型一样,特征函数也相同,这里不再赘述,
和
为新增团集。
文献检索场景下,返回的文档(即文献)包含了标题、摘要、关键词、正文等多个字段。我们假设一个文档
有k个不同字段,
,那么文档集合就可以被分成k部分:
。我们使用混合语言模型(mixture of language model, MLM) [13] 定义特征函数。
对于
团集上的特征函数
,我们定义:
其中
,k是文档包含的字段的总数目,
是每一个字段对应的权重,概率
表示每个文档字段下实体生成概率,通过极大似然估计得到:
表示实体
出现在
的次数,
表示文档j字段m的总长度。与
和
定义类似,
和
为在文档集合上的定义,
是字段j的狄利克雷平滑因子 [14] 。
至于
集合上,出于对计算效率的考虑,本文只考虑两个实体的情况,定义特征函数如下:
对于
我们统计两个实体在同一个窗口单元(如同一字段)共现的频次,即:
在MRF基础模型中对于每个匹配项,假设具有相同的权重。这样的假设可能对检索性能有潜在的不利影响,特别是对于复杂的冗长查询 [15] 。对此,我们引入了一个权重项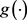 ,用于度量不同项的重要程度。这里我们参考IDF定义方式,定义权重函数
,用于度量不同项的重要程度。这里我们参考IDF定义方式,定义权重函数 :
:
其中t可以是unigram或者bigram,
表示文档集合数目,
表示t出现的文档个数。最终特征函数为:
(3)
(4)
3.5. 实体类型信息
本文关注文献检索领域,依据文献检索的特点将用户的检索查询划分为面向问题和面向方法两种信息需求。为了实现上述检索方式,我们在检索模型中引入实体的类型信息。通过命名实体识别(Named Entity Recognition,简称NER)技术,首先识别出文本中具有特定意义的实体。
本文中涉及的实体类别主要为以下几种类别:
· Task (T):表示与具体应用,最终目标或问题定义相关的科学概念实体。
· Process (P):表示与某些科学模型,算法或过程相关的科学概念实体。
· Other (O):表示除上述定义的两种类型实体外,文献中涉及的其它科学概念实体。
本文使用模型CNN-biLSTM-CRF [16] 进行特定域命名实体识别。如图4为典型的一篇研究文献摘要的实体指称抽取过程。

Figure 4. Examples of specific type entity extraction
图4. 特定类型实体抽取示例
biLSTM-CRF模型在进行NER任务时,利用上下文信息,编码了文本的词法和语法信息,因此处理短句子或者不完整文本描述效果并不好,适合于文献标题、摘要、正文等长文本数据的实体识别。对于查询上实体类别信息的识别,本文基于伪相关反馈策略对查询中实体类型进行估计。具体的,首先利用公式(2)计算与用户查询的相关文档,然后基于相关文档,我们定义查询实体类型的概率分布为:
表示与查询相关的TOP-K的相关文档集合,t表示实体类型,
。
然后,我们使用上式对于用户查询实体类型进行估计,得到用户查询类型推断,基于用户查询类型进行再次检索。具体的做法是,我们对公式(3) (4)稍加改变,引入实体的类别信息。本文中采用以下策略,在估计语言模型概率
和
时,我们考虑词项的类型匹配信息。对于词项e (即实体、实体对)在
出现的词频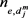 估计有:
估计有:
其中 为超参数,值越大表示实体的类型信息越重要。最后使用公式(2)进行检索,得到满足用户查询需求的文献结果。
如图5,为基于实体依赖建模的MRF检索流程。其主要分为离线和在线部分,离线部分(左)负责文献集合的实体抽取和索引构建。在线部分(右)可以总结为以下流程:1) 用户根据自身潜在信息需求,形成原始查询;2) 原始查询经过实体链接,变成查询以及查询实体,然后将查询以及查询实体送入检索模型,使用公式(2)进行初次检索,得到TOP-K的相关文档;3) 基于相关文档中实体类型,估计查询实体的类型分布,获得用户的查询类型信息。4) 基于查询词、查询实体和实体类型信息再次进行面向问题-方法的细粒度检索。
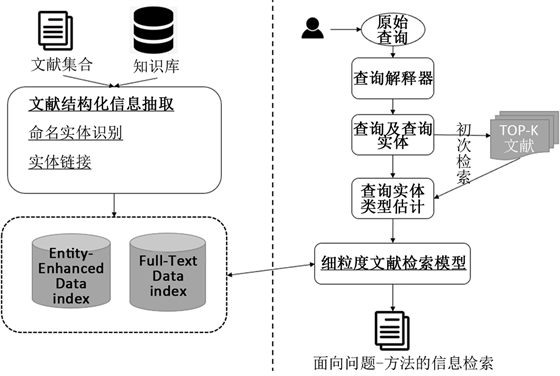
Figure 5. MRF retrieval process based on entity dependency modeling
图5. 基于实体依赖建模的MRF检索流程
4. 实验
4.1. 实验数据集
本文使用Explicit Semantic Ranking (ESR) [9] 作为我们的基准数据集,验证我们提出的基于实体依赖建模的检索模型的有效性。
ESR数据集的查询是从学术搜索引擎Semantic Scholar在2016的查询日志中采样构成。总共包含100个查询,其中20个采样自高频查询,30来自中频查询,剩余50个采样自Semantic Scholar表现较差的困难查询,主要涉及计算机科学领域。查询候选文档是从Semantic Scholar在线搜索系统汇集生成,共有8541篇候选文档,每个相关文档都由人工标记,共分5-level的相关度。
4.2. 实体识别
实体抽取部分,分为查询和文献语料两个部分。对于文献语料,我们首先需要在ESR数据集上抽取特定类型(Task, Process)的实体指称。这里使用在ScienceIE SemEval 2017 Task 10 [17] 数据集上训练得到的CNN-BiLSTM-CRF命名实体识别模型。然后使用开源实体链接工具dexter2 [18] 将Bi-LSTM-CRF识别的结果链接到Wikipedia上。对于用户查询,我们直接使用dexter2进行实体识别和链接。
经过实体链接后,100个查询其中由92个查询包含实体,其中32个为多实体查询,最大实体个数为3。ESR文献语料集总共包含179,702个实体。
4.3. 检索性能
评价指标:我们使用信息检索中常用的NDCG和Percision作为我们主要的评价指标。
基准模型:这里我们选取两个常用的信息检索模型作为基准模型对比。其中包括BM25模型,查询语言模型(Query Likehood, QL)。所有的模型都被应用到文献的多个字段(标题,关键字,摘要)。
对于模型参数,所有模型均采用5-折交叉验证进行参数调优。其中一折数据作为测试集,其余作为验证集。我们使用网格搜索(grid-search)方式在验证集上筛选最优的参数,使得NDCG@20最大化。使用网格搜索时,狄利克雷平滑因子u (所有字段共用)筛选范围是{100, 500, 1000, 1500, 2000, 2500, 3000};
取值范围[0,1]间隔0.1;摘要、关键字和标题的权重取值范围是{1, 5, 10, 15, 20, 15, 30};参数
取值范围是{1, 2, 3, 5, 7}。
Table 2. Comparison of BM25, QL and EBMRF retrieval results
表2. BM25、QL以及EBMRF的检索结果对比
为了探讨实体信息有效性,我们在BM25模型、查询语言模型(QL)以及本文提出模型(EBMRF)上进行实验。实验只使用到了实体本身,没有使用实体类型信息。实验分为三个组别:1) 仅使用词信息;2) 仅使用实体信息;3) 同时使用词和实体信息。实验结果见表2。从表中可以看出,三种模型仅使用单一信息的检索结果要低于使用两种信息的情况,说明引入实体信息时能够有效的提升检索性能。此外,还可以看出本文方法的最优检索性显著优于两种基准模型,本文分析是因为EBMRF方法充分利用了词项、查询实体间的依赖关系,而另外两种模型并没有考虑。
为了研究实体间关系对于提高检索性能的帮助,本文设置如下对照实验组,第一组为使用了全部5种类型的团的EBMRF模型;第二组为去掉实体依赖特征的EBMRF模型,记为EBMRF+。在由32个多实体查询构成的子集ESR-ME以及ESR数据集上,结果如表3。可以发现EBMRF模型较EBMRF+取得更高的检索性能,表明建模实体间关系有利于提升检索表现,并且在多实体查询集时,更加显著,从侧面说明捕捉实体依赖性对于提高多实体类型查询检索性能有效。
Table 3. Comparison of retrieval results between EBMRF and EBMRF+ on multi-entity queries
表3. EBMRF和EBMRF+在多实体查询上检索结果对比
另一方面为了研究本文提出的面向问题方法的检索。我们设置对比实验,其中一组为使用了实体类型信息,记为EBMRF*,一组为没有使用类型信息,记为EBMRF。虽然ESR数据集在构建时并没有考虑到用户查询意图是基于问题还是方法,对相关文档的标注可能与本文研究的不完全相符,但我们仍好奇引入了类型信息之后是否会得到性能提升。实验结果如表所示。由表4可知,EBMRF*在NDCG和P@{5, 10}上的结果要优于没有引入类型信息的EBMRF,而在NDCG@20和P@20上提升不大。我们分析,产生这个结果的原因是类型信息的引入能够捕捉到更丰富的语义信息,使得高相关文档排名更靠前;而对于弱相关文档,其类型信息作用并不显著,而且因为多引入了实体识别的误差,导致性能持平或者下降。
Table 4. Comparison of retrieval results between EBMRF and EBMRF*
表4. EBMRF和EBMRF*的检索结果对比
5. 总结
在本文中,我们研究了科学文献领域的信息检索方法。根据文献查询特点,我们提出了一种新的面向问题–方法的检索方式。与传统检索不同的是,我们将用户的信息检索需求分为问题查询需求和方法查询需求,不同的文章侧重表达了用户的不同需求类型。为了捕捉用户的查询需求类型,我们提出了一种基于伪相关反馈的方法,利用相关文档中的实体类型,从而推测用户查询中的需求类型。另一方面,为了探索实体信息特别是实体间的内在关系的有效性,本文在MRF检索模型的基础上进行扩展,融合了实体和实体类型特征。实验表明引入实体补充信息以及建模实体间内在依赖关系对检索性能有提升。同时我们也发现引入用户信息需求类型对于检索也具有积极作用。
文献检索是近年来的热门研究方向,本文对这一领域的研究有一定的实用价值,但还有很多可以继续深入的地方。本文仅使用了二元实体对关系,实体间的关系可能更多元化;其次本文根据实体类型信息实现了面向问题方法的检索,类似地利用实体类型信息的检索方法值得进一步探索。
参考文献