1. 引言
随着互联网的快速发展,人们了解资讯的方式和阅读的习惯都发生了很大的变化,网络新闻阅读已经成为人民日常生活不可缺少的一部分。它给人民生活带来便利,但同时由于参与用户多、资讯源头多也带来了严重资讯过载问题。如何从海量的新闻资讯或讨论话题中挖掘出用户感兴趣的内容变得越来越困难。个性化的热点新闻/话题推荐系统可以有效解决这一问题,为用户提供个性化热点新闻,提高用户的阅读和参与体验。如今日头条、一点资讯等新闻阅读产品都以自己的个性化推荐算法作为吸引用户的卖点。
个性化的热点新闻/话题推荐的关键是根据用户的阅读历史精准刻画用户的个性化阅读兴趣模型,从而为其推荐个性化阅读列表。因为新闻/话题和阅读的历史都具有一定的主题特性,因此很多学者将主题模型引入了新闻推荐过程。郭晓慧 [1] 在LDA模型的主题采样及其分布计算过程中引入平均加权值,提高了主题间的区分度。汤鲲 [2] 等人将LDA与GRU相结合应用于群聊会话主题挖掘,解决了传统主题模型不能解决的词语顺序问题。曹巧翔 [3] 等人针对web服务描述文本较短、缺乏足够有效信息的问题,提出了基于Word2Vec和LDA主题模型的web聚类方法。居亚亚 [4] 等人在LDA算法中加入了动态权重,使得在主题语义连贯性、文本分类准确率、泛化性能和精度方面比目前流行的LDA推理算法表现得更加优越。王丽苗 [5] 等人针对短视频喜好率预测面临着用户及广告的数量巨大且训练数据集高维、稀疏等问题,提出了基于LDA-GBDT-FM的短视频喜好率预测模型。
这些方法都注重了利用LDA进行新闻内容的分析,提高了推荐的准确性,但却没有考虑用户兴趣的变化。因此本文提出了一种基于主题兴趣变化的热点新闻推荐算法,它利用用户阅读历史主题的变化描述用户兴趣的变化,从而预测用户下一时刻的可能的阅读兴趣。该方法首先以一定大小的时间窗划分用户的阅读,根据每个时间段内用户阅读历史利用LDA模型,得到用户兴趣的主题分布。其次,利用时间惩罚加权函数和LDA模型得到的用户在每个阶段的新闻主题分布,得到用户兴趣。最后利用基于用户的协同过滤和待推荐新闻的主题分布完成热点新闻推荐。通过实际数据集上的实验表明,该方法提高了推荐的性能。
2. 基于主题模型的用户兴趣变化模型的建立
本节阐述基于LDA概率主题分布和时间权值的用户兴趣模型生成。首先以一定大小时间窗划分用户的阅读历史,然后利用时间惩罚权值函数建模用户兴趣的变化,从而预测下个时间窗的概率主题分布以完成推荐。
2.1. 基于用户历史划分的新闻主题分布
LDA (Latent Dirichlet Allocation)是用于挖掘文本隐结构的重要的概率主题模型。本文利用LDA挖掘用户新闻阅读历史的隐结构作为用户兴趣 [6] 。
假设用户集合为
,新闻集合
,每个用户的以一定时间窗大小划分其新闻阅读历史后的集合为
。对于用户
的阅读历史为
,被划分后表示成
,其中
是用户
整阅读历史被划分的阶段数,
为最近交互阶段。对目标用户
的每个阶段
可到其阅读历史
,因此在阶段
用户
可看成是阅读的新闻集合
,每条新闻看成可观测变量
,
是
中新闻个数。每个新闻
从全概率角度用LDA可表示成式(1)。
(1)
其中K为主题数。
进一步定义
,
分别表示某一新闻对某一主题的重要性和某一主题对特定用户的重要性。
和
通过Gibbs采样得到已阅读新闻产生的隐变量。因此概率
和
,分别如式(2)、(3)。
(2)
(3)
其中,
和
分别是
和
大小的矩阵,
和 是
和
的超参数。
和
的默认值经常取为
和0.01。
表示在阶段
是
和
的超参数。
和
的默认值经常取为
和0.01。
表示在阶段 主题
分配给新闻
的次数,
表示在阶段
主题
分配给用户
的次数。
主题
分配给新闻
的次数,
表示在阶段
主题
分配给用户
的次数。
因此,利用LDA得到表示用户
在
阶段的兴趣主题分布
,进而得到用户
阅读兴趣分布
。
2.2. 基于时间惩罚权值的用户阅读兴趣变化模型
因为离当前时刻越近的阅读兴趣可能对兴趣预测的重要性越强,而离当前时刻时间越长,影响越小。因此定义了一个取值范围在[0, 1]范围内的指数函数来描述这种重要性变化的递减,如式(4)。
(4)
其中,
,
表示递减率。当
值越高,比较久的阅读历史影响越小。
表示当前时刻与历史时刻相差的阶段数,值越大,表示时间越久远,影响越小。因此得到根用户兴趣的表示
。用户下一阶段的阅读兴趣表示,如式(5)。
(5)
它是用户阅读历史主题分布的加权表示。
2.3. 热点新闻/话题推荐
得到所有用户在下一阶段的兴趣分布后并计算用户间余弦相似性,得到目标用户的近邻用户。根据近邻用户的阅读历史得到待推荐新闻集合。利用LDA得到待推荐新闻的概率主题分布,利用式(6)计算用户兴趣与待选新闻间的相关性,推荐与用户相关性最大的新闻 [7] 。
(6)
3. 实验与结果分析
3.1. 数据集
实验数据采用的从人民网爬取的11万7千条用户阅读记录,涉及到1万3千名用户。其中,每条数据包括了用户编号,新闻编号,浏览时间,新闻标题,新闻详细内容等部分。删除用户阅读记录少于10条及数据属性较少或无用信息较多的用户数据。最终,得到清洗之后的数据约有6万5千条。在试验过程中将每个用户最后五条阅读记录作为测试集,其余作为训练集。
3.2. 评估标准
准确率是推荐算法中最重要的评测数据,它用来衡量算法推荐结果的准确性,表示推荐给用户的资源中有多少比例是用户所接受的物品。计算公式如式(7):
(7)
其中R(u)是推荐给用户u的资源集合,T(u)是用户实际操作的资源集合。
召回率是推荐算法中另一个重要测评数据,它与准确率一起被合称为精确率。表示用户所接受的资源中有多少比例是算法推荐给用户的资源。召回率计算公式如(8):
(8)
3.3. 参数敏感性分析
在实验中,超级参数α,β的取值会对LDA模型产生巨大影响,α在文档中的主题稀疏性中起作用。高α值意味着主题稀疏性的影响较小,即预期文档包含大多数主题的混合 [8] ,而低的α值意味着我们希望文档仅涵盖少数主题;β在主题中的单词稀疏性中起作用。高β值意味着词稀疏性的影响较小,即我们期望每个主题将包含语料库的大部分词。首先通过对α,β值的研究,找到并选出两者比较合适的数值,让实验能够获取到最大的准确率。具体情况如图1和图2。
从图1可知,随着α值得增大,准确率先增大后减小,当α值为0.12时准确率达到最高,因此在试验过程中将α值取为了0.12。而图2则说明,随着β,值得增大,准确率是缓慢降低的,因此,β值不宜取较大的值,在试验过程中取为0.01。

Figure 1. The effect of α on accuracy
图1. α值对准确率的影响
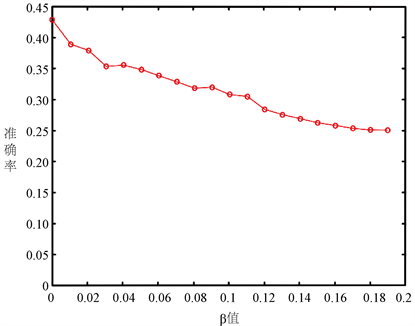
Figure 2. The effect of β on accuracy
图2. β值对准确率的影响
对于基于主题模型推荐算法中,主题个数也会对算法性能产生很大的影响。在试验过程中,固定α、β的值,讨论了主题个数对算法准确率和召回率的影响,如图3和图4所示。
图3表明,随着主题个数的增加,准确率先增加后减小,而从图4可知,在随着主题数的增加,召回率缓慢增加,因此,综合主题数对准确率和召回率存在综合影响。在试验过程中,还讨论了本文LDA与协同过滤想结合的算法与LDA算法的性能,从图3和图4可知,本文方法的准确率与召回率都优于普通的LDA算法。

Figure 3. The influence of number of topics on accuracy
图3. 主题个数对准确率的影响

Figure 4. The influence of number of topics on recall rate
图4. 主题个数对召回率的影响
3.4. 性能评估
为了更好的评估算法性能,实验中分别给出了本方法推荐列表长度分别位10,20,30的推荐结果,并与基于LDA的方法进行了对比,具体实验结果如表1所示。随着推荐列表个数的增多,无论是LDA还是协同过滤的LDA,在准确率和召回率上都有提升,并且协同过滤的效果要好于LDA的方法。

Table 1. Comparing the accuracy rate of number of different topics between LDA and LDA-CF
表1. LDA与LDA-CF不同主题个数准确率从和召回率的对比
3.5. 推荐案例
首先,给出一个用户ID,通过ID与其浏览记录进行匹配,图5中以“5034018”为例,其实际浏览过的信息有5条,其新闻标题分别为:“失联航班乘客家属在吉隆坡机场等待消息”、“波音飞机事故史”、“马航失联航班搜救画面”、“菲律宾派飞机寻找马航失联客机”、“马航在吉隆坡国际机场召开新闻发布会”。

Figure 5. Recommend 10 news results to users
图5. 向用户推荐10个新闻结果
对其浏览记录进行分词,计算分布等操作。最终推荐出10个该用户可能感兴趣的新闻信息。其中浏览过的新闻有两条,其标题分别为:“失联航班乘客家属在吉隆坡机场等待消息”、“马航在吉隆坡国际机场召开新闻发布会”
当修改代码,将推荐的新闻改为20个,其推荐给该用户的结果如图6所示:
在这20个新闻推荐中,用户浏览过的记录有4条,分别为:“失联航班乘客家属在吉隆坡机场等待消息”、“波音飞机事故史”、“马航失联航班搜救画面”、“菲律宾派飞机寻找马航失联客机”。

Figure 6. Recommend 20 news results to users
图6. 向用户推荐20个新闻结果
4. 总结
本文提出了一种基于主题兴趣变化的热点新闻推荐算法。该方法,首先用固定时间窗口大小,来划分用户的阅读记录。再利用LDA获取到每个阶段的用户兴趣的分布。通过使用时间惩罚加权函数,来预测用户下阶段可能感兴趣的新闻主题。最后,基于用户的协同过滤和待推荐新闻的主题分布完成热点新闻的推荐。实验结果表明,本文方法在推荐准确率和召回率上都有所提升。