1. 引言
推荐系统现已成为诸多领域的重要工具,如信息检索、旅游、近似理论、商业和营销中的消费者选择建模以及预测理论 [1]。众多个性化推荐技术中应用最广泛的是协同过滤推荐算法 [2]。近年来,国内外诸多学者皆对推荐系统进行研究。文献 [3] 提出了一种人工免疫系统方法来进行矩阵分解,以优化学习过程中的潜在特征。在大型数据集上有良好表现,但却有分类准确度较低的不足。文献 [4] 提出了一种基于单线程的流形正则化非负矩阵分解模型,可以避免大规模矩阵操作。文献 [5] 提出了一种新的贝叶斯网络模型,通过结合基于内容和协作的功能来处理混合推荐问题。为了解决推荐系统的稀疏性和可扩展性两个主要缺点,文献 [1] 开发一种基于协同过滤方法的新型混合推荐方法。以上方法尽管能缓解推荐系统存在的部分问题,但并未兼顾计算速度与推荐结果个性化。鉴于此,本文基于多个弱学习者可以产生比单个强学习者更好的模型这一机器学习理论,提出一种基于机器学习的融合推荐算法,能够提高计算速度并克服冷启动问题,为用户提供个性化服务。
2. 基本理论
2.1. 交替最小二乘法ALS
在将用户对商品的评分矩阵分解成用户对商品隐含特征的偏好矩阵和商品所包含的隐含特征矩阵这一过程中,由于存在大量的缺失评分项,传统的奇异值分解SVD不易处理稀疏矩阵,而交替最小二乘法可以很好的解决这个问题。对于
的矩阵,ALS旨在找到
和
两个低秩矩阵来近似逼近
,即:
(1)
其中
代表用户对商品的评分矩阵,
表示用户对隐含特征的偏好矩阵,
则表示商品所包含隐含特征的矩阵,T表示矩阵
的转置。Funk 函数定义为:
(2)
引入正则化参数
防止过拟合,ALS的优化目标函数为:
(3)
其中
表示用户i对商品j的评分矩阵,
表示用户i的偏好的隐含特征向量,
表示商品j包含的隐含特征向量,向量
和向量
的内积
是用户i对商品j评分的近似;r则表示矩阵
的秩。
由于变量
和
耦合到一起,于是先我们随机初始化
,再固定
求解
,然后根据公式(3),对损失函数
中的
求偏导并令其等于0:
,可得
,上式中
是单位矩阵,
表示给项目j评过分的用户的历史评分数据组成的评分向量。类似地,固定
去求解 ,同理可求得
,
代表用户i对项目的历史评分向量。如此这般,循环往复迭代下去,直到达到收敛状态或最大迭代次数时结束 [6]。
,同理可求得
,
代表用户i对项目的历史评分向量。如此这般,循环往复迭代下去,直到达到收敛状态或最大迭代次数时结束 [6]。
2.2. 天牛须搜索算法BAS
2017年李帅等人提出一种基于天牛觅食原理的仿生优化算法天牛须搜索(BAS)算法 [7],在优化任务中有出色表现。该算法不同于拟牛顿法L-BFGS、非线性共轭梯度NCG等算法,BAS不需要具体函数形式与梯度。它基于天牛的行为:使用两个触角随机探索附近区域并调整到具有更高浓度气味的位置 [8]。通过天牛的检测行为,可以在以下迭代形式的多维空间中获得全局最优:
(4)
其中x表示甲虫在第t次迭代时的位置,
表示每次迭代的步长,
是归一化的随机单位矢量,代表搜索行为;
表示符号函数;
是适应度函数,而
和
是右侧位置和左侧位置的气味浓度。
2.3. 基于密度的噪声应用空间聚类DBSCAN
DBSCAN是一种基于密度的聚类方法,其原理是找到被低密度区域分离的稠密区域,要求聚类空间中的一定区域内所包含对象的数目不小于某一给定的阈值 [9]。DBSCAN涉及扫描半径Eps和邻域内点最少个数MinPts两个参数,并基于中心的密度将点分为核心点、边界点和噪声点三类。其优点是:聚类速度快,且能够有效处理噪声点,能发现任意形状的空间聚类;此外,不需要输入要划分的聚类个数。算法流程如下:
(1) 将所有点标记为核心点、边界点或噪声点;
(2) 删除噪声点;
(3) 为距离在Eps之内的所有核心点之间赋予一条边;
(4) 每组连通的核心点形成一个簇;
(5) 将每个边界点指派到一个与之关联的核心点的簇中。
3. 融合推荐算法
3.1. ALS + BAS模型的建立
正如2.1节所介绍的,ALS自身存在迭代次数与运行时间成正比、最大迭代次数可以自己设置、收敛速度慢等一些问题,本文使用天牛须搜索算法BAS对非线性的约束问题进行独立优化,减小运算量并且提高寻优速度。模型建立步骤如下:
(1) 随机初始化式(3)中的
,此时认为
是已知常量,欲求未知量
,损失函数为:
(5)
(2) 初始化天牛个体。创建天牛须朝向的随机向量
,定义空间维度k,设置步长因子
。
(6)
在式(6)中,
为随机函数。
(3) 确定适应度函数。本文使用测试数据的平均绝对误差MAE作为适应度评价函数。
(7)
在式(7)中:N为观测次数;
为第t个样本的模型输出值;
为第t个样本的真实值。故,模型迭代停止时,适应度函数值最小的对应位置即为问题所求的最优解。
(4) 设置天牛左右须空间坐标。
(8)
在式(8)中,
和
分别表示在第t次迭代时,天牛左须和右须的坐标;
为天牛质心坐标,而两须之间的距离用
表示。
(5) 更新天牛位置。将天牛左右须的坐标带入式(4)中来确定当前天牛的空间位置和气味强度测定适应度函数,以求出天牛个体位置的气味强度:
(9)
(6) 找出最新气味强度。找出天牛须中最新的气味强度f及位置
,即
(10)
(7) 找寻最强的气味强度,并飞向该位置。
(11)
(8) 最优解生成。重复执行步骤(4)~(7),迭代优化来寻找最优解,在适应度函数值达到设定的精度0.0001时迭代结束,
中的解为训练的最优解。
3.2. XGBoost
XGBoost (extreme gradient boosting)是一种基于梯度提升的集成学习算法,其原理是通过弱分类器的迭代计算来实现准确分类 [10]。XGBoost使用树集合模型,是一组分类和回归树木。梯度增强则是通过构造新的回归树以最大程度地与损失函数的梯度的负相关,进一步增强了增强算法的灵活性 [11]。在处理预测问题上具有以下优势:(1) XGBoost使用所有的并行方式构建树本身计算机在训练期间的CPU核心,拥有更大计算速度 [12]。(2) XGBoost是一种通用的监督机器学习方法,在诸多实际应用中实现高精度预测 [13],其高精度可归因于机器学习理论,即多个弱学习者可以产生比单个强学习者更好的模型 [12]。
3.3. 整体框架图
整个融合模型主要由:天牛须搜索优化的交替最小二乘法模块、DBSCAN推荐模块和XGBoost三个模块组成如图1。具体步骤如下:
Step1:将数据集按照8:2的比例划分成训练集和测试集。
Step2:建立改进的ALS模型,计算目标用户的候选集A。
Step3:运用DBSCAN算法将用户聚类,找到相类似的用户簇,再计算出目标用户的候选集B。
Step4:将Step2和Step3各自求得的推荐结果输入XGBoost模型中融合排序,从而获得针对用户的个性化TopK推荐。
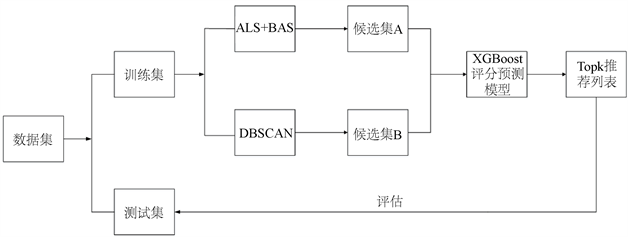
Figure 1. The overall recommendation framework proposed in this paper
图1. 本文提出的整体推荐框架
4. 实验结果与分析
4.1. 实验环境和数据
本文实验使用的是亚马逊销售苹果手机评分数据。数据集包括3582条评分数据,包含产品名称、品牌、价格、评分(1~5)、评价、实际情绪(正面和负面)、更新投票和投票评级,后两项不在考虑范围之内。实验计算机配置:Intel的Core I7处理器,内存8G,Windows10操作系统,程序在R语言平台实现。
4.2. 评价指标
本文实验分别从运行时间、预测精确度和分类准确率三个方面来衡量所提出的推荐模型。预测精确度使用平均绝对误差MAE,MAE数值越小,证明预测的精度越高,其数学定义如式(12):
(12)
分类准确度则用来衡量算法预测的TopK结果的好与坏,本文使用的评价指标是召回率Recall、准确率Precision和F1-Score,三个指标的数学定义公式如下:
(13)
(14)
(15)
4.3. 结果分析
4.3.1. 时间性能对比
将原始的交替最小二乘法和基于天牛须搜索算法改进的交替最小二乘法分别作用于不同大小的数据集上,其运行时间(以期望的收敛值10−3为停止标准)如图2所示。
从图中可以观察到:两种算法的运行时间随评分矩阵大小的变化趋势,即矩阵越大,运行时间长;原始的ALS在每个试验数据集上的运行时间都要比改进后ALS算法的运行时间长;改进后ALS算法越是处理更大的矩阵,其加速效果越是显著。

Figure 2. Curve: system result of standard experiment
图2. 运行时间性能比较
4.3.2. 预测精确度
ALS的平均绝对误差最大,为0.7496,DBSCAN的平均绝对误差次之,为0.7443。而融合了改进的ALS算法与DBSCAN算法的XGBoost模型的MAE值仅为0.7268。由图3可见,融合推荐算法提高了预测评分的精度。
4.3.3. 分类准确度
最后,本文将对提出的融合推荐模型的有效性进行评估验证,图4~6分别展示不同算法在3种衡量标准上的实验结果:
从图4种能够看出,融合推荐模型的召回率最大,为15.20。证明推荐的TopK结果和数据集中所有相关项目的比率最大;我们希望推荐结果precision越高越好,同时recall也越高越好,但事实上这两者在某些情况下存在矛盾,同图5不难观察到,融合推荐算法的准确率稍有逊色;F1综合对分类准确度综合度量,F1值可视作召回率和准确率的调和平均值。ALS、DBSCAN和融合推荐算法的F1值分别为:0.1886、0.2007和0.2135,融合模型优于其他单一算法。
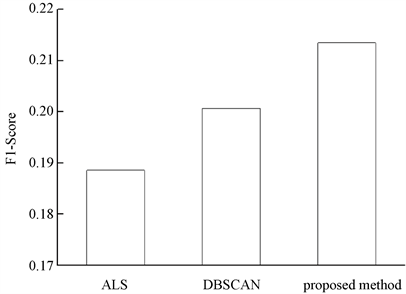
Figure 6. F1-Score comparison chart
图6. F1-Score对比图
5. 结语
本文在协同过滤的基础上,使交替最小二乘法与天牛须搜索算法结合,得到收敛速度更快的ALS + BAS算法。将DBSCAN与ALS + BAS算法所生成的候选集组合输入XGBoost模型进行融合排序,以获取个性化TopK推荐。实验结果表明,1) 数据集越大,ALS + BAS算法加速效果越显著;2) XGBoost融合模型在保证预测精确性的前提下,F1评估指标提高0.0249,可以为用户提供更加个性化服务。
此外,在我们未来的研究中,计划进一步改进提出的方法并对其使用多样性和新颖性等附加指标数据集进行评估。
基金项目
黑龙江省教育厅基本业务专项理工面上项目(135209234);齐齐哈尔市基金项目(GYGG-201913)。