1. 引言
1.1. 课题背景
废水排放一直是造成污染的主要原因。关于废水的处理,在近些年一直被大家所重视,习近平总书记也提出“绿水青山就是金山银山的”的科学论调。废水处理的关键在于找到主要污染物排放的规律,现有的废水处理办法是单调的,一般是只处理一种主要污染物,虽然在某一个阶段处理掉了主要污染物,但是其中的其他污染物经常是相伴而生的,没有处理的污染物经过大江大河的汇聚将这些污染物增加,造成了多种污染物的汇聚。
如果可以将污染物的内在规律研究清楚,在源头就可以将这些污染物处理和中和,这无疑是对废水处理是有很大帮助的,查阅资料发现,对于污水处理的资料较多,但是关于污染物相关关系的资料比较少,于是想到通过统计的办法将主要污染的相关关系进行研究。
1.2. 数据简介
1.2.1. 数据来源
本例选取了2014年度全国31个省、直辖市、自治区分地区废水中主要污染物的排放情况(2014年)。数据来源于《中国统计年鉴(2015)》(数据经整理)。具体数据内容见附录一。
1.2.2. 变量解释
排放总量,是指在在各省市地区内废水排放的总量。
化学需氧量,在一定条件下,用一定的强氧化剂处理水样时所消耗的氧化剂的量,是有机物污染的单位。
氨氮,氨氮是指水中以游离氨(NH3)和铵离子(NH4+)形式存在的氮。
总氮,水中各种形态无机和有机氮的总量。
总磷,水样经消解后将各种形态的磷转变成正磷酸盐后测定的结果。
石油类,石油化工企业没有处理完全排放到废水中的污染。
挥发酚,主要污染源为煤气洗涤、炼焦、合成氨、造纸、木材防腐和化工行业的工业废水。
铅、汞、镉、六价铬、总铬和砷,都是易溶于水的微量重金属,人体吸入微量即可中毒。
1.2.3. 变量分类
观察图1的数据,发现这些数据大概分两类 [1],其中一类是污染物排放大量的混合类的物质,就是化学需氧量、氨氮、总氮、总磷、石油类和挥发酚,另一类是微量的重金属元素,也就是铅、汞、镉、六价铬、总铬和砷。
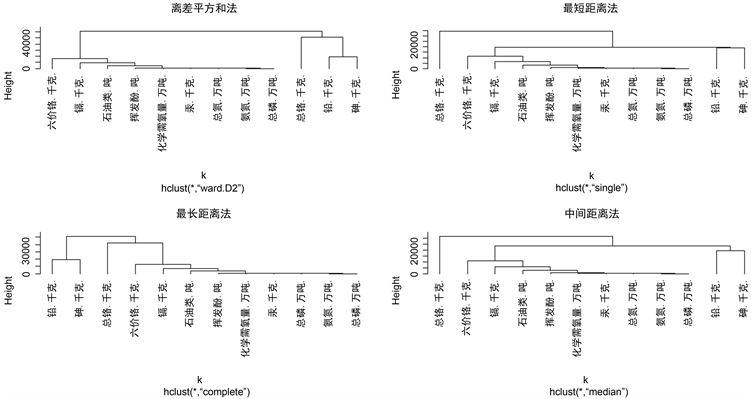
Figure 1. Tree charts of four classification methods
图1. 四种分类方法的树状图
2. 典型相关分析
典型相关分析 [2] 是分析两组随机变量线性密切程度的统计方法,是两变量间线性相关分析的推广,利用的是主成分的思想进行计算,于是利用这两类污染物进行典型相关分析,通过R语言的运算 [3] 得到:
$cor
[1] 0.8422213 0.6919939 0.4832242 0.2977800 0.1298041 0.0638123
$xcoef
[,1] [,2] [,3] [,4] [,5] [,6]
化学需氧量.万吨.0.348786750.30824480.0739831 −0.0250541 −0.04490420.5322099
氨氮.万吨. −0.36058566 −0.08468350.06966200.2243247 −0.0561619 −0.2627890
总氮.万吨. −0.06065231 −0.43909860.18431350.4685476 −1.2018838 −0.2318784
总磷.万吨. −0.090585870.0928561 −0.2908861 −0.61683461.27642550.0836312
石油类.吨. 0.004755460.1409063 −0.1490477 −0.0924792 −0.0597922 −0.0580233
挥发酚.吨. 0.03420705 −0.0633240 −0.05761920.16670180.06088440.0546728
$ycoef
[,1] [,2][,3] [,4] [,5] [,6]
铅.千克. −0.16846140.82579160.4445493 −0.29783550.72227360.2164321
汞.千克. 0.0874625 −0.0836052 −0.24751700.3283287 −0.0641557 −0.0757728
镉.千克. −0.2137683 −0.39301890.37447920.1202555 −0.2767173 −0.0998673
六价铬.千克. −0.06359440.13175350.08041240.0368075 −0.1247078 −0.1173750
总铬.千克. −0.0765014 −0.1345282 −0.2174887 −0.02257750.05105500.0163813
砷.千克. 0.2542479 −0.3480042 −0.5996226 −0.0517086 −0.44837300.1108174
$xcenter
化学需氧量.万吨. 氨氮.万吨. 总氮.万吨.总磷.万吨. 石油类.吨.挥发酚.吨.
3.14489e − 17 2.05928e − 17 −1.07441e − 17 1.65638e − 17 1.16394e − 17 4.09898e − 18
$ycenter
铅.千克. 汞.千克. 镉.千克. 六价铬.千克. 总铬.千克. 砷.千克.
1.99213e − 17 1.34301e − 17 −4.70054e − 181.81866e − 172.95463e − 177.16273e − 18
$cor给出了典型相关系数,体现了各对典型变量的相关性从大到小的性质,r1 = 0.842,r2 = 0.692,因此这两组数据存在高度相关的关系,即混合类物质越多,微量的重金属元素前两对标准化的典型变量的线性组合是:
第一对典型相关变量(
)中,
是混合类物质的线性组合,其中
、
和
比其他的变量的贡献率要更高一些,说明化学需氧量、氨氮和挥发酚是混合物质的主要指标,占据主导地位。
是微量的重金属元素的线性组合,其中
、
和
的贡献率较大,说明微量的重金属元素中汞、总铬和镉是主要指标。
第二对典型相关变量(
)中,
是混合类物质的线性组合,其中
、比其他的变量的贡献率要更高一些,说明总氮是混合物质的主要指标,占据主导地位。
是微量的重金属元素的线性组合,其中
和
的贡献率较大,说明微量的重金属元素镉和六价铬是主要指标。
3. 多元线性回归
3.1. 理论基础
3.1.1. 最小二乘估计
含有p−1个自变量的理论线性回归模型的一般形式 [4]
其中
是模型的参数,e为误差项,反映了随机因素对Y的影我们将其展开成矩阵形式,
从而多元线性模型写成
。使用最小二乘法计算回归系数的估计值
,通过矩阵运算完成。
β的最小二乘估计
,残差向量为
,
的最小二乘估计为
。
3.1.2. 显著性检验
在多元线性回归方程中,t检验和F检验并不一致,在p个自变量中,只要有一个自变量与因变量的线性关系显著,F检验就会通过,但是这并不说明每个自变量在线性模型中都影响显著,所以t检验是必要的。
1) 回归方程线性关系的检验
回归方程的F检验是总体的显著性检验,提出假设为
,
至少有一个不为0
计算F检验的统计量
2) 回归系数显著性检验
回归方程通过整体显著性检验后,我们对各回归系数单独进行检验,首先提出假设。
,
计算检验的统计量
服从t(n−p)的t分布
3.2. 模型的建立
通过典型相关关系,发现了贡献率较高的数据是第一对数据,于是选取第一对(
)中的主要指标作为我们分析的主体,发现其中几个变量与其他的变量相关性较强,于是建立多元线性模型 [5] [6],考虑变量之间的关系。
设立多元线性模型为:
首先,在95%的置信区间下,选用混合类物质变量中的化学需氧量、氨氮和挥发酚三个变量进行分析。
发现化学需氧量这个回归线性模型检验p = 0.337 × 1010通过了模型检验而且有三个变量通过了检验,拟合优度R2 = 0.941说明模型的拟合效果较好,可以达到线性模型的要求, 氨氮这个变量线性模型也通过了检验,拟合优度R2 = 0.911但是只有一个变量通过了检验,所以不选用这个变量,挥发酚这个变量发现回归模型的拟合优度只有R2 = 0.012,不适用线性模型。
在95%的置信区间下,选用重金属元素的相关变量,重金属元素镉和六价铬两个变量进行分析。
元素镉变量线性模型检验p = 0.197 × 109通过了检验,拟合优度R2 = 0.929达到线性模型要求,而且有三个变量通过了检验,满足线性模型要求,六价铬这个变量线性模型检验通过了检验,但是只有一个变量通过了检验,拟合优度R2 = 0.393也不是很高,不适用线性模型,内容见附录四。
综上所述,选出了化学需氧量和镉这两个变量进行线性模型的构建,剔除了没有通过检验的变量,化学需氧量和镉这两个变量可以写出的回归方程是:
3.3. 回归诊断
3.3.1. 残差和残差图
在进行模型假设的时候,常常假定模型误差
满足了下列条件
1)
2)
,其中i ≠ j
线性模型可以写成
,由回归系数估计值
得到Y的拟合值为:
其中
称为帽子矩阵,从而残差向量为
。
因为这些假设都是关于误差项的,要分析他们的估计量(残差) [7] 的角度解决,所以要进行残差分析。于是得到了两个线性模型绘制残差图。

Figure 2. Residual graph of the first linear model
图2. 第一个线性模型的残差图

Figure 3. Residual graph of the second linear model
图3. 第二个线性模型的残差图
通过上图明显发现,图2无明显违反马尔克斯假定的征兆,而图3则相反。所以决定弃用第二个线性回归模型。
3.3.2. 异常点检验
对参数估计或预测值有异常的数据,称为强影响数据,如果个别数据对估计有异常大的影响,当我们剔除掉这些数据,将得到和原来差异很大的经验回归方程 [8],可以怀疑原方程的正确性,从而建立更加可信的方程。
判断强影响点的方法是DFFITS统计量,根据矩阵对焦元素计算,公式:
对于i个样本,若
则认为第i个样本是强影响点,可能是异常值。
通过计算第一个模型的异常值检验得到:
123 4 5 6 7 8 9 1011 12
FALSE FALSE FALSE FALSE FALSE FALSE FALSETRUE FALSE FALSE FALSE FALSE
13 14 15 1617 18 19 20 212223 24
FALSE FALSE FALSETRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
25 2627 28 29 30 31
FALSE FALSE FALSE FALSE FALSE FALSE FALSE
可以从上图中发现,第8个样本存在异常点,回看数据发现是黑龙江省的废水排放数据,并没有发现数据有缺失或异常。
于是运用R语言去掉这个异常值,重新拟合了一个回归方程:
两个回归方程对比发现变化并不大,为了保证数据完整性,仍然选用没有剔除异常值的回归方程。
3.3.3. 多重共线性诊断
多重共线性 [9] 是指线性回归模型中的解释变量之间由于存在线性关系或者近似线性的关系,而使得模型难以估计准确。
检验多重共线性我运用的是方差扩大因子的方法,判断多重共线性。
自变量Xj的回归系数估计值
的方差可以表示为:
VIFj即为变量Xj的方差扩大因子,
为自变量Xj对其余自变量作回归分析的复相关系数。方差扩
大因子越大,表明自变量之间的多重共线性越严重,造成的回归估计值不稳定。
通过计算回归模型的多重共线性情况如下:
vif(aa)
x4 x11 x13
1.835484 1.172172 1.619351
> sqrt(vif(aa))>2
x4 x11 x13
FALSE FALSE FALSE
可以看到
的方差扩大因子都小于10而且接近于1,说明模型没有多重共线性的倾向。
4. 线性模型解释
对于回归模型进行诊断过后,发现线性模型成立 [10],模型的因变量是化学需氧量,而自变量是氨氮、镉和总铬这三个变量,通过查阅资料发现,化学需氧量COD反映了水中还原物质污染的程度,这种还原物质包括了有机物、亚硝酸盐、硫化物等物质。因为水很容易被有机物污染且十分普遍,所以化学需氧量是用来衡量水被有机物污染程度的一个变量。氨氮是水中的营养素,可以导致水富有营养化,是水中耗氧的主要污染物,对鱼和水生物有很大的危害。镉元素的毒性很大,常用在电池中,电池的随意丢弃,是造成水质中镉元素多的主要原因。总铬产生于合金材料、染料、陶瓷等产业排放的污水中,有极强的氧化性,氧化后的铬元素有剧毒。
通过以上的资料查询,发现回归模型的现实意义与数学意义十分相近,化学需氧量和氨氮都是评价水中有机物污染的废水排放指标,所以他们的的相关性极强,而化学需氧量是评价水中强酸类排放的指标,而后两种元素和酸性物质很容易发生反应,而且产生这两种污染的企业往往不会同时产生,属于轻工业和农业的区别,我们知道各省市地区的发展经常是偏向一方的。
综上所述,对于废水排放的处理 [11] 提出两点建议:1) 在有机物、亚硝酸盐、硫化物等物质存在较多的废水处理过程中,不但要注意对这些物质的处理,同时我们要关注氨氮污染物的处理,因为这两类污染物常常是相伴而生的。2) 在混合废水中,有机物、亚硝酸盐、硫化物等物质存在,镉和总铬污染物往往存在比较少,这可能是两类物质相互发生了反应,也可能是各省市经济侧重点不同,当然造成这两种废水不会同时产生的原因,还有待研究。
5. 总结
本文首先对数据进行四种办法的分类,发现数据答题可以分为两类,将两类污染物进行典型相关分析,观察发现第一对相关关系的贡献率十分高,于是我们选取了第一对中的主要指标作为我们分析的主体,之后为了分析他们的线性相关性,建立了多元线性模型,通过R语言的计算,得出适当的回归方程,再通过模型的诊断和检验,判断出最正确的线性回归模型。
通过查阅资料,对线性模型的现实意义进行解释,发现与线性模型的数学意义相符,从而再次确定了模型的正确性,之后根据回归方程变量系数的大小,判断变量的正负相关性和他们的相关性大小,得出了相应的结论。回归方程的建立解释了废水主要污染物排放规律,根据变量的相关性大小,我们给出具体的建议,希望可以对今后的废水处理提供一些帮助。
附录
原始数据