1. 引言
随着互联网技术的发展,越来越多的网友更愿意在网上发表自己的观点,比如在微博上发表对某件事的看法或是观看电影后书写自己的观影体验。尤其是近年来国内电影行业的快速发展,更多的人选择在休闲时间和家人或朋友去电影院观看电影,对影评进行情感挖掘显得越来越重要。这些影视评论一方面影响着其他用户体验,同时也会将影迷观感反馈给影视公司,这对于后面的电影制作会有很大的帮助。电影评论主要是针对故事情节和演员的演技,所以评论会有比较大的多变性,更加偏向口语化和无规则性,尤其是一词多意,这就让问题变得复杂。很多的实验表明,针对中文影评的情感分析模型准确率相对较低。本文通过集成思想设计一种融合模型,并且爬取豆瓣平台的电影评论作为研究对象,来论证本文模型的有效性。
2. 相关工作
情感分析,也称为意见挖掘,可以从书面语言中分析出人们的情感、观点和态度。情感分析方法主要包括两种:基于规则和基于机器学习 [1]。
基于规则的方法依赖于情感词典的构建,即将分词后的文档与情感词典的词进行匹配,并统计匹配成功的情感词数量。肖江等为了能够更加准确的识别情感词,在基准情感词的前提下构建了相关领域情感词典 [2]。Paltoglou等于2012年采用基于情感词典的方法进行情感分析,利用否定词、程度词、情感极性等对微博语料进行情感极性判别 [3]。对于不同领域的情感分析,使用领域情感词典具有更好的效果。Jo等将主题和情感同时标签,利用句子的主题代替词的主题标签进行采样,以此缩小词语之间的主题关联 [4]。基于情感词典的方法,可以节省很多时间,但是在不同领域的情感分类,需要该领域下的情感词典,模型迁移上效果很差,准确率较低。
基于机器学习的方法可以达到更高的准确率,但是在机器学习训练模型前,需要对文本语料进行标注。早期,Pang等首次应用机器学习方法解决情感分析问题,他们尝试使用N-gram模型提取特征,并取得很好的效果 [5]。国内的一些学者利用机器学习的方法进行情感分类,比如liu等先利用协同过滤的方法对文本进行半标注,而后利用支持向量机算法进行分类 [6]。对于电影评论,Darger A L等结合bayes和KNN两种算法,并得出了bayes分类准确率高于KNN算法的分类准确率的结论 [7]。随着机器学习的发展,词向量被提了出来,one hot方法得到广泛的应用,但是one hot方法具有无法表示词语之间的相关性和维度矩阵的稀疏性的问题。而后Hiton提出了词向量(Word Embedding)方法,可以很好的将文本语法结构和句法结构映射到向量的不同纬度,从而解决了向量稀疏问题,并且向量空间也可以很好地反映文本语义之间的相关性 [8]。Le等基于词向量的方式进行优化,构建句子或短语的词向量表示,从而克服了one hot本身的缺点 [9]。
传统的机器学习算法具有良好的性能,前提是需要对文本做一定的处理,即传统的机器学习算法对特征有一定的要求。因此,情感分析的表现很大程度上依赖于文本特征的选择,这一过程需要大量的人力物力。深度学习通过构造深层次的网络结构来学习数据特征和数据分布,从而可以在文本中自动去学习特征,这相对于传统机器学习,会节约很多时间。深度学习已经在许多自然语言处理任务中取得了巨大的成功。Collobert等首次将卷积神经网络(convolutional neural network, CNN)引入了自然语言处理的领域,并取得了较好的结果 [10]。王煜涵等利用卷积神经网络(convolutional neural network, CNN)对Twitter文本进行情感分析,CNN算法在提取文本的局部特征上表现了良好的性质,实验表明CNN模型在情感分类上的表现要比传统的机器学习算法更好 [11]。
注意力机制目前已经得到广泛运用,在文本处理领域,注意力机制的可以使得模型有选择的对最优特征进行提取,提高分类效率。Quanzeng You等在2016提出了一种基于注意力机制的LSTM的情感分析机制,通过提取长短文本特征,并结合注意力机制进行特征筛选来达到分类的目的 [12]。关鹏飞等运用LSTM模型结合注意力机制应用于情感分析,提高了模型训练的准确率 [13]。王盛玉等结合CNN和注意力机制,以词特征提取为目标,提出词注意力卷积神经网络模型 [14]。
虽然有很多深度学习模型应用在情感分析领域,但是在情感分析领域的大部分的模型都是单一的。卷积神经网络最早被应用于图片处理领域,提取局部特征具有好的表现,并取得了巨大的成功。实验表明CNN在文本处理领域也具有很好的效果,但CNN模型在捕捉文本的语义关系时表现较差,对于电影短文本,对语义的理解很重要,所以为了提高CNN算法的准确度,本文在CNN模型的基础上加入了对文本语义特征提取具有较好效果的加有词注意力机制的BiLSTM模型,提出基于词注意力机制的BiLSTM和CNN模型的集成模型(Word Attention-based BiLSTM & CNN Stacking Model,WABCSM)。
本文模型主要完成以下任务:(1) 词嵌入层。利用word2vec将文本结构化,作为模型的输入。(2) BiLSTM层。考虑到文本中情感词不仅与前面出现的内容相关,还与后面的内容相关,所以采用BiLSTM。BiLSTM模型对文本的语义理解有很好的效果,将词向量的输入进行文本语义的理解和记忆。(3) 注意力机制。注意力机制的引入,用来加强文本中情感词的权重。(4) CNN层。卷积操作用来获得n-gram特征,用于最终的情感分类。本文通过WABCSM模型在中文影评数据集上做了验证,并且与传统的深度学习模型进行比较,取得了很好的结果。
3. 基于词注意力机制的BiLSTM和CNN集成模型的中文情感分析
本文的模型采用集成的思想将BiLSTM模型与CNN模型进行模型融合,一方面通过BiLSTM进行文本的语义提取,结合CNN模型,提取文本关键词。为了提高模型的准确度,在BiLSTM层后加入了Attention层,目的是增加文本关键词的权重,使得模型可以更好的提取关键词,来达到情感分类的目的。本文模型结构如图1所示。
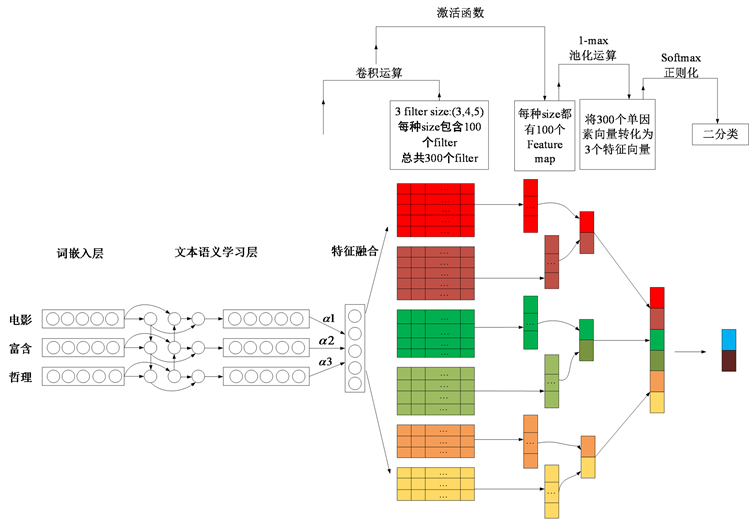
Figure 1. Integration model architecture
图1. 集成模型架构
3.1. 词嵌入层
本文词嵌入层的输入是经过jieba分词后的结果,包括词和字。如何正确的分词对模型的训练有很大的影响。比如“电影富含哲理”可以分成“电影”,“富含”,“哲理”,也可以分成“电”,“影”,“富”,“含”,“哲”,“理”。这就加大了难度,本文考虑到中文的特殊性,采用第一种分词方式。对于分词之后的文本要进行结构化。传统的稀疏向量表示存在矩阵维度过大的缺点,无法表示出文本语义之间的联系。Hinton于1986年提出分布式表示(distributed representation)的方法很好地解决了One hot的不足 [8]。目前比较常用的word2vec方法就是属于分布式表示。Word2vec可以将文本通过低纬度稠密的向量来表示,不仅解决了稀疏性的问题,而且分布式方法可以很好的表示语义之间的关系。word2vec将语料训练成
规模的词向量矩阵,D表示字典的大小,s表示词向量的维度。假如
表示文本的第i个词,并且文本长度为L,则输入的向量可以表示为
(1)
例如本文语料库为“超级,好看,准备,二刷”,其数字表示就是{1:超级 2:好看 3:准备 4:二刷},文本即转为数字表示,结构化(1, 2, 3, 4)就表示文本“超级好看准备二刷”。将结构化语言(1, 2, 3, 4)进行word2vec训练,词向量维度是预定好的。word2vec分为CBOW模型(continuous bag-of-words model)和skip-gram模型(continuous skip-gram model),本文的词向量表示是基于skip-gram模型,Skip-Gram模型的网络结构分为:输入层、投影层和输出层,原理是以当前词
对其上下文
中的词进行预测。
本文Skip-Gram模型更新参数的伪代码:
3.2. 文本语义学习层
BiLSTM层。循环神经网络(Recurrent neural network, RNN)是传统神经网络的变体,神经元的设计使得网络具有“记忆性”,所以RNN是深度学习的一种常用框架。对于短文本的处理上RNN具有良好的性质,但对于长文本,RNN网络的“记忆”功能越来越差。为了解决这个问题,Hochreiter & Schmidhuber于1997年提出了长短时记忆网络(Long Short-Term Memory, LSTM) [15]。本文利用的BiLSTM模型是其变种,为双向长短时记忆网络,因为情感词不仅和之前出现的文本相关,还会和后面的文本相关。
LSTM单元结构的设计体现在3个“门”结构上,这三个“门”结构使得LSTM可以实现对历史信息的重要部分的记忆,这体现在网络中的单元(cell)状态的不断更新。首先记t (当前)时刻的候选单元值为
,输入值的权重为
以及
时刻cell输出的权重为
,则t时刻的候选单元值为
(2)
激活函数tanh创建的候选单元值
将会加到cell状态中。
输入门的作用是t时刻的输入对cell状态的影响,这体现在“遗忘门”机制。并且3种“门”机制的运算都受到来自当前输入、前一时刻的cell输出以及前一时刻cell记忆值的共同影响,即输入门
表示为
(3)
遗忘门由Sigmoid层实现,控制当前输入值对cell状态的影响,可以表示为
(4)
所以当前时刻t的cell状态为
(5)
公式(5)中运算符
表示点积运算,从最终的cell状态可以得出,LSTM单元状态的更新由遗忘门、输入门、前一时刻的单元状态和当前候选单元共同决定。
对于输出门,
的表示形式为
(6)
最后的输出可以表示为
(7)
本文采用的BiLSTM模型的输出表示为
取其平均值作为输出,即输出为
。对于长短文本传入BiLSTM层,“门”结构将实现信息的更新与遗弃,这体现在sigmoid函数,其输出为0~1之间,1指完全保留,0指完全遗弃。
词注意力机制层。电影评论为长短文本,评论中的情感词对于评论情感倾向至关重要,加强这些情感词的权重将可以更好的对文本进行情感挖掘。采用词注意力机制,用来学习评论语句中情感词的权重分布,如表1所示。
词注意力机制最早是由google mind团队在RNN模型上运用,来进行图像分类。Bahdanau等第一次将词注意力机制运用到NLP领域,被应用到机器翻译领域的sequence to sequence模型 [16]。而后被广泛应用于CNN模型,用于图像处理。Wang等在LSTM模型中应用注意力机制来获取重要的评论信息,原因在于注意力机制可以自动学习关键词的权重分布 [17]。
本模型中,注意力机制的加入用来自动学习权重分布,自动学习的结果为
(8)
其中W,b分别为权重和偏置项。将输出处理后,即得注意力向量矩阵。且权重分布为
(9)
其中S为文本的长度。假设BiLSTM层的输出为
,则经过Attention层后的输出为
(10)
注意力机制下,权重
越大,其对应的词越重要,这对文本的关键词提取具有很好的效果。
3.3. CNN层
卷积神经网络(convolutional neural network, CNN)的出现最早应用于图像处理领域,Kim等人在2014年对传统CNN网络进行了一些调整,使得CNN第一次用于文本处理 [18]。Santos等人提出的CharSCNN模型,结合两个卷积核实现语义特征的识别,在情感分析问题上表现很好 [19]。李昊璇等利用词向量结合CNN的方法,对书籍评论进行情感分析,取得了很好的效果 [20]。李慧等将CNN用于细粒度情感分析,相比较传统分类模型具有更好的结果 [21]。下面介绍CNN模型的主要结构。
卷积层。记输入的字数长度为l,窗口大小为n,输入值到卷积单元的参数记为w,那么卷积操作后的输出值
,即卷积后得到的特征为
(15)
其中,
表示步长,f为非线性激活函数,b为偏置项。
池化层。通过一定的策略进行最优特征选择,常用的方法是平均值法和最大值法,本文选用最大值方法将卷积后的输出特征
进行池化操作来选取最优特征。
(16)
其中,
。
全连接层。池化后的结果P通过全连接层后传入输出层,利用softmax函数进行分类,返回的是情感分类的预测概率,输出的值在0~1之间,0表示完全消极,1表示完全积极,公式为
(17)
其中
,
分别为输出层的权重和偏置项。
4. 实验
4.1. 实验环境
本实验环境下的模型是基于深度学习库keras,操作系统为windows7旗舰版64位,CPU为i3,显卡是Inter(R) HD Graphics,开发工具是pycharm。由于本文数据量不大,所以不需要太高的配置。
4.2. 实验数据
本文通过爬虫技术爬取了豆瓣网60775条评论,包括30445条消极评论,30330条积极评论。本文将数据按照8:2的比例构造训练集和测试集,即训练集个数为48620,测试集个数为12155。积极评论和消极评论例子对比见表2。

Table 2. Comparison of negative text and positive text
表2. 消极文本和积极文本对比
从表2中可以看出,消极文本中充斥着消极情感词,例如消极文本中的“不合适”,“怀疑”,“尴尬”,积极文本中的“好,擅长”,“惊艳,真美”,“很暖”,情感词直接表示评论文本的情感极性。对文本进行数据预处理,过程如下:
(1) 评论文本和标签的获取;
(2) 去除评论文本标点符号及分词处理;
(3) 将处理后的文本构建字典,并将字典中的词进行token转化,提取出现频数大于5的词来创建词典;
(4) 词向量训练,将句子中存在而字典中不存在的词用随机值代替词向量;
(5) 将数据打乱,用于模型训练。
本文模型的超参数如表3所示。
4.3. 性能评价指标
本文模型的评价指标采用精准率、召回率以及F1值。先说明一些指标。
TP表示正类预测为正类,TN表示负类预测为负类,FP表示负类预测为正类,FN为正类预测为负类。对于模型好坏的评价方式一般采用精准率(Precition)、召回率(Recall)和F1值。
精准率:
召回率:
F1值:
4.4. 实验对比及分析
本文单模型CNN的窗口大小设置为(3, 4, 5),窗口维度大小为100,激活函数为ReLu,池化层采用Max。单模型LSTM的优化函数为Adam,激活函数为ReLu。
对比实验。将以下四种模型分别在word2vec和随机向量填充两种词向量方法下进行实验。本文实验不仅讨论了词向量对模型的影响,而且也比较了模型之间的好坏。本文的重要贡献在于将单模型进行集成,得到新的模型,并加入了注意力机制来优化模型。实验如下,实验结果如表4所示。
(1) 基于随机向量的LSTM模型。本模型仅利用随机化的向量来作为样本输入,用于LSTM模型训练。
(2) 基于词向量的LSTM模型。本模型利用word2vec对文本训练词向量作为输入,用于LSTM模型训练。
(3) 基于随机向量的CNN模型。本模型仅利用随机化向量来作为样本输入,用于CNN模型训练。
(4) 基于词向量训练的CNN模型。本模型利用word2vec对文本训练词向量并作为输入,用于CNN模型训练。
(5) 基于随机向量的BiLSTM_CNN模型。该模型是对两种单模型的Stacking融合,将样本的随机向量作为模型的输入。
(6) 基于词向量的BiLSTM_CNN模型。该模型是将样本进行word2vec训练并作为输入。结合BiLSTM_CNN模型进行训练。
(7) 本文模型。基于随机向量作为输入,并加入词注意力机制的BiLSTM_CNN (rand & Word Attention-based BiLSTM & CNN Stacking Model, WABCSM + rand)。
(8) 本文模型。基于词向量训练作为输入,并加入词注意力机制的BiLSTM_CNN (word2vec & Word Attention-based BiLSTM & CNN Stacking Model, WABCSM + w2v)。
实验结果分析:
基于词向量。四种模型下的结果显示,一方面word2vec训练下的词向量表示结果要优于随机变量填充的训练结果。这说明word2vec训练下的词向量很好的表示文本之间的语义关系,对情感分类具有积极的效果。而随机填充下的词向量达不到这个效果。另一方面,即使在随机填充下,模型训练的效果依然不差,这说明深度学习在特征学习上具有很好的效果。
基于模型。本文模型的实验结果要优于传统的单模型。尤其是在注意力机制下的模型,取得了很好的效果。对于单模型,CNN模型要比LSTM模型取得更好的效果,这说明在提取文本的特征上,尤其是提取局部最优特征上(关键词),CNN模型要优于LSTM模型。比较本文的模型结果,融合模型BiLSTM_CNN的效果比传统LSTM以及CNN效果都要好,随机向量填充下,精准率分别提升了1.0%和0.9%;word2vec训练的词向量下,精准率分别提升了1.3%和1.0%。在此基础上加入了词注意力机制,结果表明,词注意力机制下的模型WABCSM表现出更好的效果,随机向量填充下,精准率比BiLSTM_CNN提升了0.2%,word2vec训练的词向量下,精准率比BiLSTM_CNN提高了1.0%。WABCSM模型对测试集样本预测的结果混淆矩阵如表5。两种词向量下的模型训练结果对比发现,word2vec词向量下的训练对正负样本的预测比例与训练样本的比例相近,有984个积极样本被预测为消极样本,有1034个消极样本被预测为积极样本。而随机向量填充方法下的训练结果预测正确的正负样本都相对较少,并且有1074个正样本被预测为负样本,有1174个负样本被预测为正样本。
本文模型的实验结果的混淆举证如表5所示。
本文模型的预测结果与真实结果对比见表6。
Table 6. Forecast results (partial)
表6. 预测结果(部分)
表6中给出了本文模型对测试集的部分预测结果,其中0表示消极评论,1表示积极评论,由于本文探索的是二分类问题,而评论会有部分属于中性评论,这使得模型对其情感极性的影响有所影响。比如“只能说我完全不纯情了”和“我看哭了说实话”这样的文本,文本太短,中文的一词多意也加重了机器学习的难度,缺乏直观的情感极性,使得机器只能根据文本中的单一情感词进行判断,“纯情”是积极情感词,机器就预测为积极文本,而“看哭”是消极情感词,机器就预测为消极文本。这也说明了一直以来对中文短文本进行情感挖掘是一个很难的课题。
图2给出了BiLSTM_CNN模型和WABCSM模型在两种词向量方法下的损失函数变化图。从四种模型在测试集上的损失变化图中可以看出,四种模型均收敛的比较快并在第8次迭代后达到收敛。对于模型BiLSTM_CNN,两种词向量方法下的结果显示,在第二次迭代和第三次迭代时,随机向量填充下的损失下降要比word2vec方法下的更快,而在第四次迭代开始,word2vec方法下的模型快速收敛并在第7次迭代开始达到收敛,而随机向量填充下的模型在第八次迭代开始收敛,并且结果要差一些。对于WABCSM模型,两种词向量下的结果都要比BiLSTM_CNN要好,无论在收敛速速上,还是在损失函数上。尤其是WABCSM_w2v模型,在第5次迭代就开始趋向于收敛,WABCSM_rand模型也在第六次开始收敛。除此之外,稳定后WABCSM_w2v模型的验证损失达到最低,优于其他模型。这显示出本文模型WABCSM具有很好的泛化能力,而且word2vec词向量训练方法有助于模型训练。
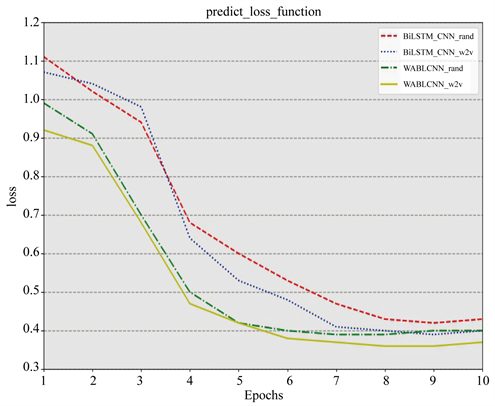
Figure 2. Comparison of changes in loss function
图2. 损失函数变化对比图
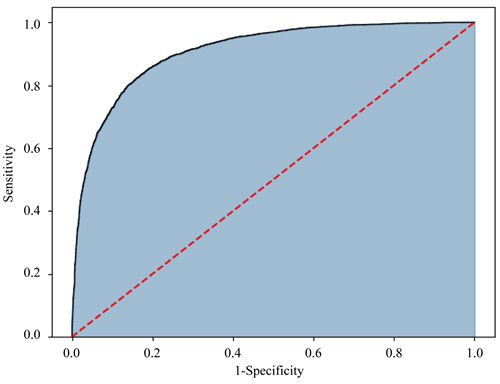
Figure 3. ROC curve of WABCSM model
图3. WABCSM模型ROC曲线图
本文模型的ROC曲线见图3,ROC曲线的横轴表示负正类率(False Positive Rate, FPR),纵轴表示真正类率(True Positive Rate, TPR)。TPR值越大越好,即ROC曲线越靠近左上角说明模型越好。本文模型的AUC值达到了0.91,这说明本文模型可以很好的处理此类问题,即本文模型在进行中文情感挖掘是非常有效的。
5. 结论
本文提出了一种基于词注意力机制的BiLSTM和CNN的集成模型来进行中文情感分析,本文模型首先利用BiLSTM模型对数据集进行长文本词语的更新和遗弃,然后加入词注意力机制,增大文本中情感词的权重,使的模型更容易提取代表文本情感极性的情感词,最后利用CNN模型进行局部最优特征提取来完成情感分类的任务。本文词向量的训练采用了两种方法,分别为随机向量填充方法和word2vec训练方法。利用LSTM和CNN这两种传统单一模型以及本文设计的两种模型做对比。结果发现本文模型BiLSTM_CNN模型在两种词向量下的实验结果无论在收敛速度还是在准确度上都要优于LSTM模型和CNN模型。为了提升本文模型的效果,在BiLSTM_CNN模型基础上加入了词注意力机制,形成了本文第二种模型WABCSM。WABCSM模型对评论文本关键词的提取上表现的更加优异。与BiLSTM_CNN模型的实验结果比较发现,WABCSM模型的收敛速度更快,精准率更高,性能更加鲁棒。
本文模型的设计源于集成思想,综合利用模型的优点,设计了表现力更好的集成模型,无论对于研究还是应用都可以得到好的效果,本文数据来源于实际生活,使得本文的研究更有意义。本文的不足在于数据量不大,利用深度学习模型训练出现了“过拟合”现象。本文尝试了比较数据量对模型训练结果的影响,发现随着数据量的增大,模型的性能越来越好,但由于电脑配置的原因,未找到最佳点。