1. 引言
表面增强拉曼光谱(Surface-Enhanced Raman Spectroscopy, SERS)是一种新型的物质检测技术。由于具有对物质进行定性定量的检测能力,在环境监测、生物化学等领域得到了广泛应用 [1] [2] [3]。在SERS检测中,研究对象的特征峰是“指纹区”,所以在各个拉曼光谱中进行峰强、峰位的比较,可以很好地区分出各种物质。但SERS光谱的形成是由于物质分子的振动,而同类物质的分子结构有一定的相似性,所以产生的特征峰的位置会非常接近,峰强近似相同,难以用常规手段进行区分 [4] [5]。如果这些噪声不减少,就会极大程度影响分析判别模型的质量和检测的有效率及准确率。
目前,常见的光谱分析判别方法,如小波变换 [6] [7]、偏最小二乘法 [8] [9]、人工神经网络 [10] [11] 等都是基于数据挖掘的经典模型。其中小波变换是基于小波基函数的平移和展宽来获得时域和频域特征的方法。而小波基函数的选取、分解尺度和阈值对去噪效果有很大的影响。偏最小二乘法是一种在理论值和观察值之差即残差的平方和达到最小的前提下求解未知参数的方法,对于线性相关的数据有着较强的回归分析能力。人工神经网络是一种模拟动物神经网络进行机器学习的一种方法,数据量充足的情况下在进行自学习和联想存储记忆方面有明显的适应力,寻找优化解的速度快。
由于SERS信号维数过高,直接对信号进行分析判别容易造成维数灾难,对分析产生不良影响 [12]。同时噪声也是光谱采集部分不可避免的,噪声的加入会使光谱的特征峰变得模糊,如果这些噪声不减少,就会极大程度影响分析判别模型的质量和检测的准确率。因此必须对原始数据进行降维、降噪的预处理,应用一定的数据处理方法,将数据维数降低的同时最大化体现其特征,提取出各物质主要信息,从而实现物质的区分。主成分分析法(Principal Components Analysis, PCA)是一种特征预处理的分析技术,可以提取一些对于结果有帮助的特征,实现需要分析判别的数据降维和特征位提取。在判别预测模型的选取上,支持向量机(Support Vector Machine, SVM)是一种可以有效区分物质光谱数据信息的模型 [13] [14],这种模型可以实现小样本学习,其计算复杂性取决于支持向量的数目,可以在一定程度上避免“维数灾难”,具有较好的鲁棒性。基于主成分分析与支持向量机的判别模型在光谱分析和图像识别中有一定的应用 [15] [16] [17],可以将光谱的特征提取出来,提高光谱的判别效率。本论文首先使用主成分分析提取SERS信号中的重要特征,使用遗传算法对支持向量机的参数进行优化,再使用SVM支持向量机进行分类预测。将输出的值和预定值进行对比,得到模型的预测准确率,如图1所示。
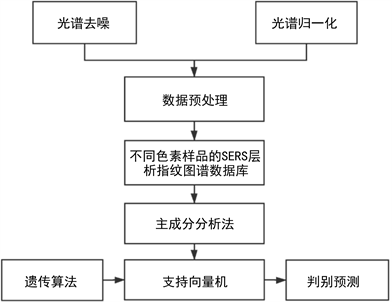
Figure 1. Flow chart of SERS signal feature extraction
图1. SERS信号特征提取流程图
2. 实验方法与结果
在前期的研究中,我们获得了纯苋菜红和诱惑红色素的SERS数据,并采用萃取法得到了香肠中的苋菜红和诱惑红的SERS信号 [18]。本研究采取相似的办法获得了纯苋菜红色素和蜜饯中苋菜红溶液的SERS光谱信号,以及纯亮蓝色素和蜜饯中亮蓝溶液的SERS光谱信号,如图2和图3所示。可以看出,数据特征峰明显,但是仍然有很多杂峰会影像数据分析,且数据的维度很高,需要进行降维处理。

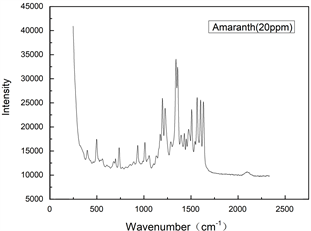


Figure 2. SERS signal of amaranth in different concentrations
图2. 不同浓度苋菜红SERS信号
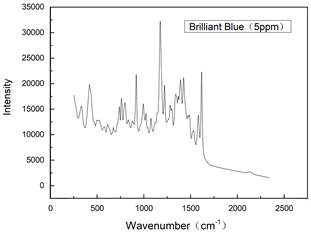

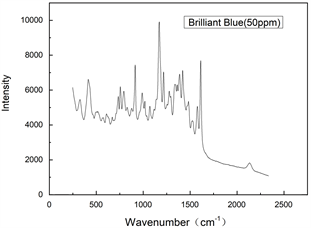

Figure 3. SERS signal with different concentration of brilliant blue
图3. 不同浓度亮蓝SERS信号
3. 数据处理方法
3.1. 主成分分析法 [19]
PCA是一种经典的数学降维模型,它通过一个正交变换,将和其原数据分量相关的原随机样本投影到一个新的空间中去,转化成其分量不相关的新随机向量,然后对多维变量进行降维处理,把携带原有数据信息较多的变量保存下来,实现对原数据的降维的目的。
假设训练集为
计算出矩阵协方差为
进行标准化处理
(1)
初始化后的矩阵仍用X来表示,经处理后数据的相关系数矩阵R为
(2)
其中,
贡献率为
(3)
具体实施方法是把检测到的光谱数据作为训练集X,取累计共享率达到95%的特征数据来代表原光谱数据。
3.2. 支持向量机 [20]
SVM是一种按监督学习方式对数据进行二元分类的广义线性分类器,其决策边界是对学习样本求解的最大边距超平面。
把纯色素光谱数据设为训练样本集X为
,光谱样本分属两类,w1和w2,线性判别函数l的一般形式为:
。色素判别的问题就转化成寻找最大间隔的分类超平面问题。在这个过程中,对距离超平面l_0最近的样本进行归一化处理,则有线性可分类SVM的优化函数为
(4)
解决上诉函数的优化问题也就能够得出不同物质的区分结果,由于SVM需要数据线性可分,在遇到线性不可分的情况下一般采用添加核函数的方法,将原始数据通过核函数映射到更高维平面v1,在对映射后的数据进行降维至低维平面进行求解。对于多种类数据,采取“一分为二”的思想,对每种数据进行逐步区分。
4. 模型应用
4.1. PCA处理
因为得到的苋菜红和亮蓝SERS光谱的维数较高,因此采取PCA进行降维和去噪处理。将用检测存储的拉曼光谱数据文件导入MATLAB中,运行PCA程序。经过PCA处理后,前两个特征可以代表96.7%的主要成分,满足95%主要成分的需求,所以取前二特征,即将原始1450维的数据降低至2维,以便投入SVM支持向量机中进行处理。将得出的数据用Excel表格保存部分数据如表1。

Table 1. Main feature results after dimension reduction based on PCA
表1. 基于PCA降维后主要特征结果
4.2. SVM判别
将经过PCA降维处理后的数据进行SVM判别。
1) 选取经过PCA处理过后的光谱数据样本作为训练样本,经过基线校正、去噪后得到训练样本数据;
2) 将训练样本分为正样本和负样本,其中正样本即为亮蓝的光谱信息,负样本为苋菜红的光谱信息作图表示验证结果信息;
3) 通过前文主成分分析法对光谱进行降维处理并得到代表光谱的特征值,采用SVM进行模型建立,得到分类器。
由于温度、机械噪声、采集位点等非人为因素,使得同一物质谱图信息存在一定的噪声。因此,降低物质与样本相似度,在增大阈值时,检验的准确率下降。首先,通过对光谱信息的降维处理,实现光谱信息概括较完整的主要特征;其次,运用SVM寻找物质间的最大几何间隔,在检验过程中,保证经验风险最小,降低置信风险,实现了在检验中的真实风险最小化。

Figure 4. Flow chart of SERS spectral processing
图4. SERS光谱处理流程图
SVM的准确性验证,识别结果与真实值相同的样本输出正确,与真实值不同的样本输出错误。应用测试样本对模型的准确性进行验证并输出模型的准确率。具体流程如图4所示。
4.3. 结果与分析
将获得的纯品色素数据作为输出变量,将所有450个样本采用选一留一法,分为训练集(400个样本)和预测集(50个样本)。SVM的参数采用遗传算法进行优化。SVM最佳参数c、g分别为21.69和0.08,交叉验证正确率约为90.38%。实测集与预测集分类图(图5)显示50个预测样本中预测准确率达98%,有一个亮蓝错判为苋菜红。上述结果表明,基于不同色素的SERS光谱,结合SVM分析技术能够较好地识别、区分食品中含有的色素。
由图6可知,样品浓度变化时的光谱图会出现明显移动,本文所选用的PCA-SVM模型的平均预测准确率为98%。其中50个预测样本仅一个出错,和预测准确率以及预期结果一致。SERS的信号相对于传统的检测手段更为具体,因为SERS是物质“指纹”区域,本身具有相对较少的杂峰,特征峰也相对明显,所以特征的提取和识别度较高。在多组检测中,模型无法达到100 %的准确率,其主要原因为:(1) 显微镜的焦距误差对数据的影响;(2) 器材的噪声对数据检出的影响;(3) PCA降维产生噪声;(4)溶液色素分子沉降但是分布的不均匀导致9点检测的光谱信号有所不同;(5) 基底采用银质纳米棒阵列,纯银在空气中存放时间过长发生氧化在基底的附着面形成了氧化银,产生了背景信号,影响SERS信号检测。

Figure 6. Two classification diagrams of SVM
图6. SVM二分类图
5. 总结
本文采用了PCA-SVM模型结合SERS光谱区分技术对两种常见的人工合成色素苋菜红和亮蓝进行区分,建立了一个有关苋菜红和亮蓝的区分判别模型。利用该模型进行区分的同时,对从蜜饯中提取的色素溶液成分经进行了预测,实验结果与预测结果基本一致。PCA-SVM支持向量机模型应用于SERS 信号的数据挖掘还可以通过改善实验条件、优化模型数据等方法,减少人为和非人为因素给判别分析带来的不必要误差。在遇到多种物质的情况下,采用分步处理的方法,先一分为二再进行区分,使训练和测试速度更快,所需的存储空间更少,极大程度减少训练学习的时间。在遇到线性不可分的数据的时候可以通过使用一个核函数将原有数据投影到一个线性可分的更高维平面,再进行分类。这种数据挖掘模型还可应用于其他相似结构物质的SERS光谱数据分析,后续可写入芯片,应用于小型手持式拉曼光谱仪和微型拉曼检测系统,从而实现食品添加剂和农药残留等问题的现场快速检测。
基金项目
浙江省新苗人才计划项目(基于多种数据挖掘方法的SERS鉴别研究2019R426046);浙江省自然科学基金项目(LY19F020022);2017年杭州市社会发展科研项目(20170533B05);杭州市哲学社会科学规划课题基地项目(2018JD60)。
参考文献
NOTES
*通讯作者。