1. 引言
随着深度学习的快速发展和许多大规模数据集 [1] [2] 的建立,人脸识别技术在近年来突飞猛进。然而,在现实场景中,由于人脸识别过程中角度和光照等因素的改变,搭建一个有效的人脸识别系统十分困难。通常,有两种方法来解决这个问题,第一种是对比某些不会随人脸角度而改变的特征 [3],另一种是通过人脸转正 [4] 的方式来生成正脸图像。
对于第一种方法,在过去二十年中,一些方法例如LBP [5],3D-LBP [6] 以及WLD [7] 被用来解决局部扭曲的问题,然后采用度量学习 [8] 的方法来实现角度不变性。第二种人脸旋转方法 [9] 是采用深度学习的方法来把一张侧脸图像转换为一张正脸图像。通过把一张侧脸图像转正人脸正面化的方法有效地提高了人脸识别的准确率。之前的一些工作采用监督学习的方式来训练一个深度回归模型 [10] 来进行人脸转正。最近几年,由于生成对抗网络 [11] 的出现,一些更加先进的生成对抗网络模型被提出。DR-GAN [12] 实现了人脸特征和角度信息的解耦合。作为一种代表性方法,TP-GAN [13] 采用了一种双通路的网络结构来同时获取人脸的全局和局部特征,然后把上述两种特征融合在一起构造出真实的人脸图像。然而,我们认为TP-GAN有两方面的局限性。首先,它的网络结构和损失函数适合进行人脸转正但是却不能进行多角度的人脸生成。另外,TP-GAN需要生成人脸的真实图像来和生成图像进行比对,所以如果某个角度的人脸图像缺失,那么训练将无法进行。
为了解决这些问题,我们提出了一种多角度人脸生成对抗网络来实现任意角度的人脸互转。具体来说,我们在特征向量上拼接一个角度来自由调节生成人脸图像的角度。由于引入了循环一致性损失,我们提出的多角度人脸旋转算法的训练过程是无监督的,也就是说在本算法的训练过程中不依赖成对的训练数据。
2. 相关工作
2.1. 生成对抗网络
近年来,生成对抗网络(GAN)在图像生成 [14],风格迁移 [15],超分辨率 [16] 等领域都取得了不错的研究成果。生成对抗网络通常有两部分组成,生成器和鉴别器。鉴别器用来区分这个样本是真实样本还是生成器生成的样本,生成器用来生成尽可能真实的样本来让鉴别器无法做出有效的判断。通过这种博弈,生成对抗网络推动着生成图像向真实图像的分布移动。最近几年来,DCGAN (Deep Convolutional Generative Adversarial Networks) [17] 在图像生成领域被广泛应用。在DCGAN中,生成器采用转置卷积来做上采样,鉴别器采用卷积神经网络来做下采样。DCGAN把生成对抗网络的博弈思想和卷积神经网络对图像的处理结合在一起,在图像生成领域取得成功。从整体上来说,我们的算法所用框架是DCGAN结构的一种拓展。
2.2. 星形生成对抗网络
星形对抗生成网络(StarGAN) [18] 是生成对抗网络的一种改进,用于实现多域之间的图像风格转换。在StarGAN的训练过程中,生成器首先把一张图像由源域转换到目标域,然后再把这张目标域图像转换为源域。通过最小化重构损失函数,在训练过程中不需要目标域的真实样本,即训练过程是无监督的。由于在训练过程中,源域和目标域是随机指定的,生成器能够学习任意两个角度之间的映射。普通GAN只能实现单域转换,但是StarGAN却可用一个生成器进行多域之间的风格转换,这极大的节约了训练所耗费的时间。在我们多角度人脸重构算法的训练过程中,采用了类似于StarGAN的训练方法。我们提出的多角度人脸重构算法仅训练一次即可完成多角度人脸的转换。
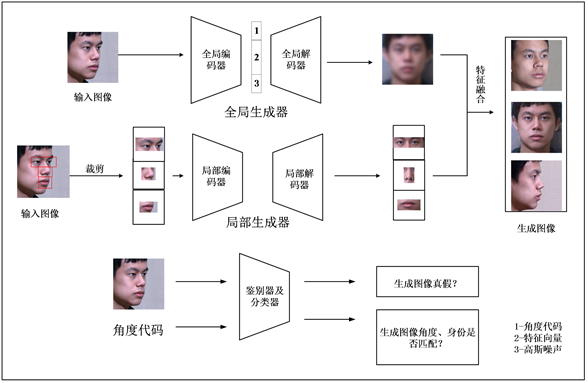
Figure 1. The flowchart of multi-poses face reconstruction algorithm
图1. 多角度人脸重构算法流程图
3. 提出的方法
多角度人脸生成的目标是通过一张真实图像
和角度代码c来生成一张身份特征保留的人脸图像
,也就是说我们的生成对抗网络要学会从
到
的映射。如图1所示,在把
输入到生成器中之后,全局编码器通过下采样获得保存人脸的身份信息的特征向量,在得到的特征向量上拼接上一定维度的角度代码c来调节生成图像的角度。然后全局解码器通过分数卷积进行上采样,输出代表人脸整体轮廓的特征图。局部生成器用来负责人脸五官的角度转换,在本算法中,总共使用了4个局部生成器来对五官进行转换,它们在训练过程中学习各自的参数。鉴别器以及分类器的作用是用来判断输入图像以及生成图像的质量好坏、角度与图像真实角度是否一致、身份信息与真实人脸身份信息是否相符。生成器、鉴别器以及分类器的具体结构会在后面的部分详细阐述。经过特征融合之后,我们得到了生成的人脸图像
,此时,我们把生成的
再输入到生成器中去,此时的角度代码为输入图像
的角度
,得到另一张生成图像
。我们通过计算
与 的循环一致损失来使得整个训练过程是无监督的。
的循环一致损失来使得整个训练过程是无监督的。
3.1. 网络结构
我们使用了两种类型的生成器来对人脸的不同维度进行建模,全局生成器用来学习人脸的整体轮廓特征;局部生成器用来对人脸五官的具体特征进行建模。相较于使用单一生成器来完成多角度人脸重构,使用多个生成器的优势在于,多个生成器各自的训练目标更加细化,各生成器之间相互配合,通过最后的特征融合把各自的训练结果组合到一起,可得到优于仅用单个生成器的生成效果。
3.1.1. 双通路生成器
生成器用G来表示,这是一种双通路的卷积神经网络结构。第一种用来获取全局特征的生成器称为全局生成器,用
来表示。如图2所示,
是一种编码器-解码器结构,编码器用
来表示,解码器用
来表示。把尺寸为
的人脸图像输入到
中,经过卷积核为
,步长为1的卷积操作,得到尺寸为
的特征图。这一步选取相对较大的卷积核的原因是全局生成器学习人脸的轮廓特征,需要较大的感受野。然后经过三次卷积核尺寸为
,步长为2的下采样过程,得到
的特征图。最后,经过全连接层,得到一个256维的特征向量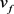 。
包含人脸的身份信息,在
。
包含人脸的身份信息,在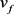 上拼接角度代码c来灵活的调节生成人脸的角度。另外,我们在
上拼接上100维的高斯噪声向量来建模其它除身份和角度等方面的特征。全局解码器
通过3个连续的卷积核为
,步长为2的上采样过程,最终得到尺寸为
的特征图,用于与局部生成器的输出结构进行特征融合。
上拼接角度代码c来灵活的调节生成人脸的角度。另外,我们在
上拼接上100维的高斯噪声向量来建模其它除身份和角度等方面的特征。全局解码器
通过3个连续的卷积核为
,步长为2的上采样过程,最终得到尺寸为
的特征图,用于与局部生成器的输出结构进行特征融合。
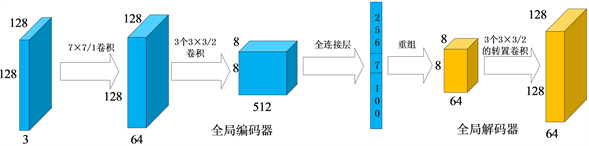
Figure 2. The network structure of global generator
图2. 全局生成器网络结构
人脸局部特征的转换通过4个局部生成器来实现。我们使用
,
来分别转动左眼,右眼,鼻子和嘴巴的角度。在人脸重构的过程中,以上4个生成器各自学习自己的参数。由于人脸的五官大小并不相等,因此对五官的截取尺寸并不相同。在本算法中,对眼睛采取了
像素,鼻子采取
像素,嘴巴采取
像素的裁剪方式。局部解码器和编码器分别用
和
表示。如图3所示,局部生成器的网络结构和全局生成器的网络结构相似,不同点在于局部生成器不生成包含人脸信息的特征向量,直接进行之后的上采样操作。上采样结束之后,生成尺寸为
的特征图,其中,w和h分别代表特征图的宽和高。
在局部解码器输出五官特征图之后,为了避免五官连接处出现模糊等情况,我们采用一种最大特征保留的方法把特征图拼接在一起。具体来说,五官特征图有各自固定的位置,但是五官特征图之间有相互重叠的部分,对于重叠部分,取最大值进行保留。完成五官特征图的拼接之后,如图4所示,把全局解码器的输出和五官特征图拼接在一起,经过后续的卷积操作,最终输出一张人脸角度转动后的图像。
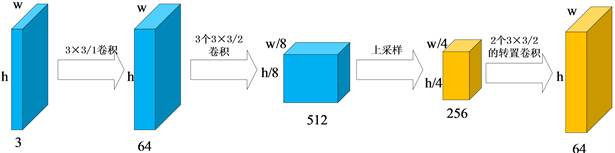
Figure 3. The network structure of local generator
图3. 局部生成器网络结构
3.1.2. 鉴别器以及身份、角度分类器
最简单的用来区分真实图像和生成图像的方式是使用一个二分类器。但是在人脸生成领域,仅使用一个二分类器很难得到理想的分类效果,因为对生成图像的质量好坏有多个角度的评判指标。与传统GAN的鉴别器结构不同,本算法中所用鉴别器D的结构不再输出一个标量,而是输出一个向量,向量中每一维分别对应图像中一部分区域,这样做可使鉴别器对图像中的每一部分分别评价,可有效提高生成图像的质量。在生成图像时鉴别器不仅需要对生成图像的整体质量做出评价,还需对生成图像中人脸的角度和身份做出分类。因此,在鉴别器的基础上,加入两个分类器
和
用以区分生成图像的身份和角度信息。身份分类器和角度分类器分别输出人脸的身份信息和角度信息。分类损失函数和对抗损失函数结合起来,共同推动生成图像的概率分布向着真实的人脸图像的分布移动。
3.2. 损失函数
在本部分中,我们将详细介绍在多角度人脸重构算法中所用到的损失函数,包括对抗损失,角度保持损失,身份保持损失,循环一致性损失。最后,我们也将给出整体损失函数,各个损失函数协同作用,使得生成器最终能够生成角度一致、身份保留的人脸图像。
3.2.1. 对抗损失函数
为了使生成的人脸图像尽可能与真实的人脸图像相似,我们引入了对抗损失函数:
(1)
N代表训练集中的样本数目。在这里,往生成器中输入原始图像
和角度代码c来生成
。鉴别器D用来分辨生成图像是一张真实图像还是一张生成的图像。生成器则尽可能生成真实的人脸图像来使得鉴别器无法分辨生成图像的真伪。因此,生成器的目标是最小化这个损失函数,鉴别器的目标是最大化这个损失函数。在这个对抗的过程中,生成图像的质量逐渐变好。
3.2.2. 角度保持损失函数
角度保持损失函数的主要作用是在生成器生成一张真实人脸图像的时候确保生成人脸的角度和我们指定的角度代码c是一致的。当在迭代优化生成器和鉴别器的时候,我们分别在生成器和鉴别器上计算角度保持损失函数的值。也就是说,我们把角度保持损失函数分为两部分,分别优化生成器和鉴别器。用来优化鉴别器的目标函数表示如下:
(2)
代表一张真实人脸图像被正确分为角度
的概率,由于是损失函数,所以需要在公式前加负号。另一方面,用来优化生成器的目标函数定义为:
(3)
同样,通过最小化这个损失函数来优化生成器G,使得生成的人脸图像的角度被正确分类为角度代码c。
3.2.3. 身份保持损失函数
在生成指定角度的人脸图像的时候,我们希望人脸的身份信息得到保留。在本算法中,我们采用了身份保持损失函数来保留人脸的身份信息。在本文中,我们使用了ResNet18作为身份分类器。ResNet18首先在Multi-PIE数据集上进行预训练,使之可以正确分类人脸的身份信息。由于身份信息相同的人脸在一些显著特征上必然相似,所以我们使用某些中间层的激活值来作为衡量指标:
(4)
F代表中间层,
和
代表中间层的空间维度。
确保生成图像和真实图像在深度特征空间有较小的距离。
3.2.4. 循环一致性损失函数
通过最小化对抗损失函数以及角度保持损失函数、身份保持损失函数,生成器在生成真实的人脸图像。然而,通过最小化以上损失函数并不能确保生成的人脸图像仅仅在角度上转换为我们指定角度而在其它方面保持不变。为了解决这个问题,我们引入了循环一致性损失函数。循环一致损失的定义如下:
(5)
如图5所示,首先把输入图像
和目标角度c输入到生成器G中,生成目标图像
。然后把
和
的原始角度
输入到生成器中,生成图像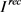 。我们通过输入图像
和重构图像
之差的L1模来计算
。我们通过输入图像
和重构图像
之差的L1模来计算 。值得注意的是,在此训练过程中,我们用到了同一生成器两次。通过最小化
,可以确保输入图像
和输出图像
在除角度之外的方面尽可能相似。
。值得注意的是,在此训练过程中,我们用到了同一生成器两次。通过最小化
,可以确保输入图像
和输出图像
在除角度之外的方面尽可能相似。

Figure 5. The calculation process of cycle consistency loss
图5. 循环一致性损失计算过程
3.2.5. 整体损失函数
在此给出分别用来优化生成器G和鉴别器D的目标函数:
(6)
(7)
其中,
到
这4个超参数用来调节其它损失函数相对于对抗损失函数的权重。在本文的实验中,我们使用
,
,
,
。
4. 实验结果分析
4.1. 实验环境(表1)

Table 1. Experimental environment configuration
表1. 实验环境配置
4.2. 数据集
Multi-PIE数据集是世界上最大的人脸生成和人脸识别数据集。这个数据集分为4个部分,总共包括337个人的人脸图像,这些人脸图像的角度在0度到90度之间。Multi-PIE数据集同时包含多种表情的人脸图像,但是在本文中只有自然表情的人脸图像被使用。另外,相机编号为08_1和19_1所拍摄的照片在本算法训练过程中没有被使用。我们使用数据集的80%作为训练集,另外的20%作为测试集。所有图像的尺寸被处理为
。
4.3. 模型训练策略
首先训练身份分类器和角度分类器,在本文中,我们使用ResNet18作为我们的身份分类器和角度分类器。Resnet18在训练数据上进行训练,使之能正确分类人脸的身份和角度信息。然后,我们使用mini-batch size 16,学习率1e−4在数据集上迭代训练生成器和鉴别器。对于训练过程中,本算法使用MTCNN进行五官位置的标注。在训练过程中,角度代码c是采用独热编码的方式,在训练过程中,我们随机生成独热编码,即随机指定生成图像的角度,在训练足够多次之后,我们建立了任意角度之间的映射。
如图6所示,如果采用传统的GAN训练方式,建立两个角度之间的映射需要对GAN训练两次,即
。以图6为例,建立5个角度之间的两两映射需要的GAN训练20次,这极大的增加了训练的时间成本。采用本文所述的训练方法,在一次训练中就能实现任意两个角度之间的映射。
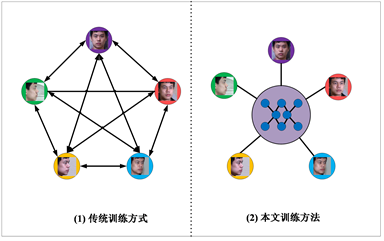
Figure 6. Comparison of traditional training methods and our training methods
图6. 传统训练方式和本文训练方式对比
4.4. 人脸转正效果及准确率分析
在本小节中,我们系统的对比了我们的多角度人脸重构算法和几种有代表性的人脸转正算法的转正效果图以及人脸识别的准确率。由于大部分算法只致力于解决人脸角度小于60˚的人脸转正,我们比较了从45˚转到0˚的人脸转正效果,如图7所示,我们比较了DR-GAN、CPF、Amir et al. [19]、HPEN [20] 以及TP-GAN和我们算法的正脸生成效果,实验效果说明我们的算法可以生成视觉逼真的真实人脸图像,并且和真实的正脸图像高度一致。

Figure 7. Comparison of the effects of face frontalization
图7. 人脸正面化效果对比
除了进行了人脸正面化的定性分析以外,我们还比较了FIP [21]、MVP [22]、CPF、DR-GAN、Light-CNN [23] 以及TP-GAN与本文的人脸重构算法的Rank-1识别率。在实验过程中,对于DR-GAN、TP-GAN以及本文所提算法,在对侧脸图像进行识别时,采用的是先把侧脸图像正面化,再进行识别的方式。对于其它算法,则直接进行识别。实验结果如表2所示。实验结果表明,随着人脸角度的增加,本文人脸重构算法的识别准确率大幅领先除TP-GAN外的其它算法。在大偏角情况下,TP-GAN采用了对称损失函数,故可能使得人脸转正效果较对称,因此可能得到更好的准确率。
Table 2. Comparison of face recognition accuracy (%) between algorithms
表2. 各算法人脸识别准确率(%)对比
4.5. 多角度人脸生成
除能生成真实且人脸身份保持的正脸图像之外,本文提出的多角度人脸重构算法能实现角度之间的互转,即多角度的人脸生成,我们从0˚到90˚之间选出7个有代表性的角度,具体效果如图8所示。前3行实现了由0˚人脸图像到其余各角度的互转,后3行实现了45˚人脸图像到其余各角度的互转。图8中,第1列是真实的人脸图像,其余各列由第1列生成。实验结果表明,我们的多角度人脸重构算法能够进行多角度人脸转换。
5. 结束语
本文提出了一种基于生成对抗网络的多角度人脸生成算法,通过把对抗损失函数、身份损失函数、角度损失函数、循环一致损失函数结合在一起,能够生成多个角度的身份保留真实人脸图像,有效地提高了人脸识别的准确率。该算法除能提高后续的身份识别、人脸识别的准确率外,也可起到图像增强,扩充人脸数据库的作用。
基金项目
本文得到“面向柔性制造的智能质量检测系统及示范应用(2018B010109007)”、“精品罐质量缺陷智能巡检机器人研发与产业化(CXZJHZ201730)”、“大南海区域广东高分大数据平台与应用示范(83-Y40G33-9001-18/20)”的资助。