1. 引言
图像隐写术是信息隐藏的一个重要分支,它在尽量不改变图像统计规律的前提下,嵌入秘密信息,外人难以察觉图像差异,从而达到隐藏秘密信息的目的 [1]。
当前图像隐写算法的设计有三大原则 [2]:
(1). 复杂度优先。在复杂度优先原则指导下,秘密信息应优先嵌入至图像纹理复杂的区域。图像隐写算法一般用像素修改代价来衡量图像的纹理复杂程度,处于图像纹理复杂区域的像素赋予较小的修改代价,这是因为图像纹理复杂区域难以建模与统计,在该区域进行修改难以被检测,有益于掩盖因载体图像像素修改带来的影响,而处于图像纹理平滑区域的像素赋予较大的隐写代价。因此需要设计一个合适的失真函数以度量图像各个区域的纹理复杂程度与像素修改所造成的修改代价,如ASDL-GAN (Automatic Steganographic Distortion Learning framework with GAN) [3] 使用生成式对抗网络(Generative Adversarial Network, GAN) [4] 的对抗学习来获取修改代价。Tang等 [5] 在上述算法的基础上,使用对抗样本的梯度方向动态调整修改代价,获得的数值更准确。WOW (Wavelet Obtained Weights) [6] 则使用方向滤波器计算每个方向的代价,若每个方向的代价都较小,则赋予该点较小的修改代价,否则赋予较大的修改代价。MG (Multivariate Gaussian Model) [7] 将图像像素看成独立的随机高斯变量,对图像的每个像素点建立图像概率模型。MVGG (Multivariate Generalized Gaussian) [8] 改进了MG算法,使用更好的方差估计器,同时使用五元编码降低修改率。MiPOD (Minimizing the Power of Optimal Detector) [9] 则使用广义高斯分布来建模,同时使用最优检测器来获取更准确的图像纹理复杂度。
(2). 代价扩散。根据复杂度优先原则,得到载体图像每个像素的修改代价后,引入代价扩原则,能够使载体图像的每个像素的修改代价更准确。代价扩散原则认为:相邻像素应该有相似的修改代价。将修改代价较小像素的修改代价扩散到邻域像素的修改代价中,使邻域像素的修改代价也相应地变小。同理,修改代价较大的像素的邻域像素也应该有较大的代价。Li等 [2] 用实验证明了可以使用低通滤波器来进行修改代价扩散。HILL (HIgh-pass, Low-pass, and Low-pass) [10] 利用了这一原则,使用一个高通滤波器计算图像纹理复杂度与每个像素的修改代价,再使用两个低通滤波器将代价扩散,隐写安全性得到有效提升。后续算法如MVGG [8] 与MiPOD [9],都使用均值滤波进行代价扩散,以提高隐写的安全性能。
(3). 修改聚集原则。秘密信息的嵌入区域应该尽量聚集在一起,使得像素的修改尽可能集中。由于载体图像在修改聚集后的SPAM (Subtractive Pixel Adjacency Matrix) [11] 特征的MMD (Maximum Mean Miscrepancy) [12] 距离明显小于修改分散的距离,因此修改聚集能更好地保持载体图像的自然统计特性,使隐写图像更接近自然图像,提升安全性。Zheng [13] 所设计的算法就很好地利用了这一原则,利用最大值滤波将隐写区域集中,使秘密信息的嵌入更加集中,隐写安全性得到提升。CMD (Clustering Modification Directions) [14] 则拓展了修改聚集原则。提出了聚集修改方向的新策略,认为除了修改区域集中外,相邻像素的修改方向也应该同向,并用实验证明了有效性。
在上述算法中,MiPOD的安全性能最优 [15],因为它所使用的估计图像概率模型计算得到的图像纹理信息更准确,满足复杂度优先原则,同时使用均值滤波作为代价扩散的方式,满足代价扩散原则。但MiPOD在嵌入秘密信息对图像像素进行修改时,使用的是随机正负1的修改方式,并不满足修改聚集原则,因此MiPOD算法的安全性仍然有提升的空间。若能改变MiPOD的像素修改方式,使其满足修改聚集原则,就能有效提升该算法的隐写安全性能。
因此,为了能有效改变秘密信息嵌入时像素修改方式,我们提出了一种新的基于最小值滤波和感知哈希算法的图像隐写算法。新算法在MiPOD算法的基础上,使用最小值滤波筛选需要同向修改的区域,在此区域中修改的方向是一致的。此外,我们利用哈希感知算法比较图像的各个区域,相似区域则使用相同的修改方向。两种方法的结合能够使算法更准确地找出需要同向修改的区域,使算法满足修改聚集原则,进而提升算法安全性能。实验证明,我们提出的新算法比现在的主流算法具有更好的性能。
2. 算法
由于本文算法是在MiPOD算法基础上改进的,加入了修改聚集功能,因此本文算法命名为“MiPOD-Cluster”。本文算法(MiPOD-Cluster)主要的改进包括两大步骤:
聚集区域与修改方式选择。使用最小值滤波处理修改代价矩阵,代价矩阵会出现局部数值相等的情况,数值相等的局部区域就是修改的聚集区域。并将数值相等的局部区域内数值对应的像素修改方向作为整个局部的修改方向。
修正相似区域的修改方式。将载体图像切割为若干个小块,使用感知哈希算法 [16] 计算小块之间的相似度,若不同小块之间相似,则赋予两个相似小块相同的修改方式。
2.1. 算法基本原理
MiPOD算法中用以度量像素修改代价的是通过概率模型建模得到的Fisher信息 [17] 矩阵。载体图像像素的Fisher信息越小,表明此像素处于的纹理区域越复杂,并且拥有较小的修改代价,在此像素嵌入秘密信息的安全性较高。反之亦然。所以Fisher信息矩阵能够近似表征载体图像的纹理复杂程度。
2.1.1. 最小值滤波原理
在实际图像隐写中,由于Fisher信息较小的像素通常处于载体图像纹理复杂的区域中,安全性较高,因此MiPOD一般在Fisher信息较小的像素上嵌入秘密信息。这意味着在载体图像中,这些Fisher信息较小的像素具有较高的修改优先级,在嵌入秘密信息会优先被修改由此可知修改聚集的主要问题是如何处理这些Fisher信息较小的像素。
最小值滤波通过选取区域中的最小值作为当前像素的值,不仅能除去不必要的噪声,筛选出的区域还能更为紧凑。此外,筛选区域中会出现局部区域内各个元素相等的情况,可将该局部区域中最小值原本的随机修改方式作为整个区域的修改方式,从而降低算法复杂度,达到修改聚集目的的同时又能减小对图像隐写效率的影响。所以使用最小值滤波处理Fisher信息矩阵时,可以将当前元素邻域中的最小值对应载体图像的修改方式作为当前元素的修改方式。
因此本文选择使用最小值滤波作为隐写候选像素的筛选聚集区域与修改方向的方法。
2.1.2. 感知哈希算法原理
载体图像中往往有一些相似的区域,这些相似的区域往往不重合,甚至可能相隔甚远,使用低通滤波的方法无法将它们联系在一起,这就需要其他方法寻找这些可能会相似的区域。
本文使用感知哈希算法 [16],是因为该算法在图像相似图片搜索领域已经非常成熟,算法速度非常快,并且图像的高度、宽度、亮度、颜色等基本信息发生变化,该图像的哈希值也不会改变,算法准确率相当高。本文算法是将图像分割成若干份,并使用图像相似算法计算它们之间的相似值,计算量较大,因此算法成熟、计算方法较快的感知哈希算法符合本文要求。
感知哈希算法的基本原理如下:
(1). 图像大小归一化;(2). 简化灰度减少计算量;(3). 计算平均灰度值;(4). 比较像素与平均灰度值的大小,若大于则记为1,小于则记为0,按照一定顺序排列成2进制的指纹编码;(5). 最后对比两幅图的指纹编码,若差异数据位小于阈值,则证明图像相似,若大于2倍阈值,则说明图像不相似。
2.2. 本文算法(MiPOD-Cluster)流程
以下是本文算法的完整流程,其中步骤1至步骤5为MiPOD [9] 的方差估计器,步骤7为利用最小值滤波得到图像像素的修改方式分布图,步骤8为使用感知哈希算法修正图像修改方式:
步骤1:计算噪声残差。假设隐写图像
是8位灰度图像,图像大小为
,具有初始像素值
,
,使用维纳滤波器(Wiener filter) F去噪,计算噪声残差r:
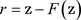 (1)
(1)
步骤2:对残差r中的第n个像素以及它的
邻域建模,边界使用镜像填充的方法扩展:
(2)
这里
是大小为
的列向量,数值为第n个像素的
邻域内的残差r的值。G是一个大小为
的矩阵,由式(3)可得,它定义了残差r的参数模型,该模型有q个参数,
是
的向量,
是噪声和建模误差的集合。
(3)
其中
、
、
是
的向量,
为单位向量,
由矩阵
(式4)展开获得,
由矩阵
展开获得,
,l是G中二维余弦多项式的阶数,G中含有
个元素,由文献 [9] 可知,
,
,
可以获得最佳的性能。
(4)
步骤3:由残差
得出参数
的最大似然估计
:
(5)
步骤4:接下来计算出残差
的估计期望
:
(6)
步骤5:假设第n个
块中的像素具有相同或相似的方差,第n个像素(第n块中的中心像素)方差的最小二乘估计为:
(7)
在估计方差较小的像素处,对估计方差进行限制:
(8)
步骤6:使用估计方差
计算得到隐写图像第n个像素的Fisher信息:
步骤7:对所有的像素点分配一个随机值,根据随机值大小随机分配修改方向。统计所有像素点的Fisher信息,得到Fisher信息矩阵Fisher_Infor。使用最小值滤波处理Fisher_Infor,中心像素置为最小值的同时,将该最小值像素的修改方向同步到中心像素中,得到图像修改方式分布矩阵Modify,里面的数值都为±1。
步骤8:将图像分割成4份,使用感知哈希算法计算两两图片的相似度。若相似则统一相似的部分图像的图像修改方式分布,若不相似,则继续切割图像,并重复该步骤。为利于计算,最大切割数量为16份,但分割后的图像最小不小于
。最后得到修正后的图像修改方式分布图Modify_new。
步骤9:根据Fisher信息矩阵Fisher_Infor与负载Payload确定需要修改的像素,根据修正后的图像修改方式分布图Modify_new确定需要修改像素的修改方向,将秘密信息嵌入至图像中。嵌入完成后,隐写完成。
3. 实验
本文使用MG [7]、MCGG [8]、MiPOD [9] 这三种效果较好的隐写算法与本文算法MiPOD-Cluster进行实验对比。
实验所使用的图像来自目前隐写算法常用的图像库BOSSbase1.01 [18]。实验使用里面10000张大小为8 bit的
的PGM格式灰度图片,其中50%用于训练,50%用于测试。嵌入的秘密信息为随机的01字符串,隐写负载分别为0.05、0.1、0.2、0.3、0.4、0.5,单位为bpp (bits per pixel)。隐写分析则使用SRM (Spatial Rich Model) [19] 特征与maxSRMd2 (max Spatial Rich Model) [20] 特征,两种方法都可提取图像34671维度的特征。选用的隐写分类器为目前隐写分析中常用的Ensemble [21] 分类器,版本为2.0,并使用默认设置。安全性能用隐写分析的检错率来表征,检错率用最小平均分类错误率
来表示,使用式(9)计算:
(9)
其中,
表示错警率(Probability of False-Alarm),
表示漏检率(Probability of Missed-Detection),
越大,说明隐写分析检测时出现错误的概率越大,隐写算法的安全性越强。
3.1. 修改聚集实验
3.1.1. 最小值滤波器的最佳窗口大小
本文修改聚集的第一个步骤就是使用最小值滤波处理MiPOD中的Fisher信息矩阵,滤波窗口的大小决定着最小值滤波对Fisher信息矩阵的影响程度,因此本小节需要讨论在本文算法中,如何选择最小值滤波器的最佳的窗口大小。
需要对比的是修改聚集在最小值滤波不同窗口大小下的算法安全性能。实验参数与Li等 [2] 一致,滤波器窗口大小从
增加到
,步长为2。隐写分析选择SRM特征,隐写负载为0.2 bpp、0.3 bpp、0.4 bpp,每个滤波窗口大小实验次数为10次,最后取平均值。测试的结果如图1。
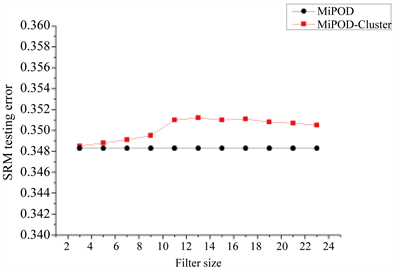 (a) 0.2 bpp负载
(a) 0.2 bpp负载 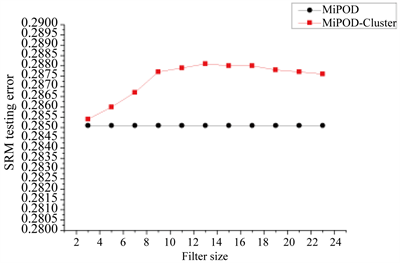 (b) 0.3 bpp负载
(b) 0.3 bpp负载  (c) 0.4 bpp负载
(c) 0.4 bpp负载
Figure 1. The influence of minimum filter and filter size on the security of MiPOD-Cluster under different payloads
图1. 不同负载下,最小值滤波不同窗口大小对MiPOD-Cluster算法安全性的影响
由图1可知MiPOD-Cluster在0.2 bpp、0.3 bpp、0.4 bpp负载的抵抗SRM特征的安全性均优于MiPOD,并且MiPOD-Cluster的安全性随着最小值滤波窗口的增大而升高,在窗口大小为13时得到最大值,当滤波窗口继续增大时,算法安全性趋于平稳。
由于隐写图像在修改聚集后的SPAM特征的MMD (Maximum Mean Miscrepancy)距里明显小于修改分散的距离 [2],因此MiPOD-Cluster在MiPOD的基础上引入了修改聚集原则后,MiPOD-Cluster隐写的图像比MiPOD的隐写图像更接近自然图像,因此MiPOD-Cluster算法的隐写安全性更高。
修改聚集的性能随着最小值滤波窗口的增大而逐渐增强,这是因为随着滤波窗口的增大,最小值滤波在图像中筛选的聚集区域范围越来越大,所寻找到的图像纹理聚集区域越多,过滤噪声的能力也越强。在滤波窗口足够大之后,修改聚集的性能趋于平稳,还有下降的趋势,这是因为图像适合修改聚集的纹理部分大小有限,滤波窗口太大,会导致本不属于一类聚集区域的聚集点集合到一起,形成大范围都为+1或都为−1的情况,降低隐写的安全性。
由此可以得出结论:MiPOD-Cluster使用
窗口大小的最小值滤波作为修改聚集的方法能够获得最好的安全性能。
3.1.2. 修改聚集的处理效果对比
为了更直观地说明本文修改聚集方法的效果,本小节讨论MiPOD-Cluster与MiPOD处理隐写图像的差异。在图像库BOSSbase1.01 [18] 中选取其他文献 [2] [22] 中常用的编号为“1013”的图像作为示例图像,分别使用MiPOD-Cluster与MiPOD对这张图像嵌入0.4 bpp的秘密信息。
实验结果如图2所示,图2(a)为示例图像,图2(b)为MiPOD在示例图像嵌入秘密信息时被修改的像素,图2(c)为MiPOD-Cluster在示例图像嵌入秘密信息时被修改的像素。图2(d)~(f)分别为图2(a)~(c)红框内截取的放大图。
图2(e)与图2(f)中,修改方向为−1的像素显示为黑色,修改方向为+1的像素显示为白色,修改方向为0时,也就是不做修改的像素显示为灰色,其中图2(e)与图2(f)的两个红框为两者有明显区别的区域。
对比图2(a)与图2(c),图2(a)的图像有一定的对称性,图2(c)的像素修改方向从整体来看,也有一定的对称性,与图2(a)的对称性相似。
由图2(e)与图2(f)对比可知,MiPOD-Cluster的像素的同向修改方向都集中聚集在某个局部单位内,而MiPOD的像素修改方向基本是随机±1的修改方式。对比两图中的红框区域,MiPOD-Cluster的修改区域与修改方向相对集中,局部都为黑色像素或白色像素,而MiPOD的修改区域与修改方向相对分散。
由于本文算法MiPOD-Cluster使用了感知哈希算法 [16] 来计算图像部分区域的相似度,因此在图像内容比较对称的情况下,图像的聚集修改方向也有一定的对称性。本文修改聚集方法中使用的最小值滤波能够选取周围像素中修改代价最小的点,作为中心像素新的修改代价,利用它的原理,可以使最小值滤波选取周围像素中修改代价最小点的修改方向,作为中心像素新的修改方向。因此本文的修改聚集方法既能找到聚集区域,又能快速确定该区域的聚集修改方式。
由此可以得出结论:本文的修改聚集方法能有效改善MiPOD算法的像素修改方式。
3.2. 算法的安全性对比
本节讨论MiPOD-Cluster、MiPOD、MVGG、MG四种算法的安全性能。对比使用的隐写分析特征为SRM与maxSRMd2,对比的项目为隐写分析的检错率,检错率越高,说明隐写算法的安全性越高。
由表1可知本文算法MiPOD-Cluster的抵抗SRM与maxSRMd2特征的检错率均高于其他三种现有算法,相比较三种现有算法中性能最好的MiPOD,本文算法MiPOD-Cluster的检错率平均提升了0.72%。
由图3可知,MiPOD-Cluster在隐写负载较低时,其性能与MiPOD几乎相同,随着隐写负载的增加,MiPOD-Cluster优于MiPOD,并且它们之间的垂直差距逐渐增大。
MiPOD-Cluster与MiPOD的算法流程比较,MiPOD-Cluster加入了修改聚集步骤,使其满足修改聚集原则,因此在隐写负载较高时,能够更合理地处理被修改像素的修改方向,使隐写图像更接近自然图像,隐写安全性自然得到提高。
由此可以得出结论:引入修改聚集原则的MiPOD-Cluster算法的安全性能优于MiPOD、MVGG、MG三种效果较好的现有算法。

Table 1. Comparison results of testing error rate with four algorithms
表1. 四种算法检错率的比较
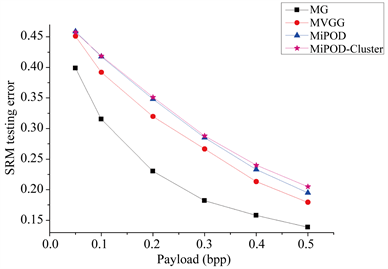 (a) 四种算法SRM检错率对比
(a) 四种算法SRM检错率对比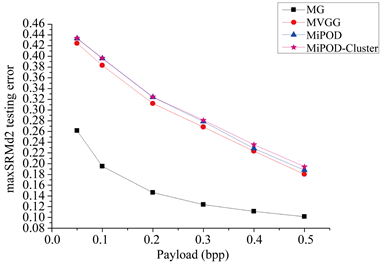 (b) 四种算法maxSRMd2检错率对比
(b) 四种算法maxSRMd2检错率对比
Figure 3. Comparison of testing error rates with four algorithms under SRM and maxSRMd2
图3. 四种算法在SRM与maxSRMd2下的检错率对比
4. 结论
本文提出了一种基于最小值滤波与感知哈希算法的图像隐写算法(MiPOD-Cluster)。其中最小值滤波能够使Fisher信息矩阵出现局部区域数值相等的情况,并将此数值对应像素的修改方向作为整个局部区域的修改方向,达到局部修改聚集的目的。哈希感知算法则能通过计算载体图像不同区域之间的相似度,寻找图像相似的区域,并使两个相似区域有一样的修改聚集方式,达到整体修改聚集的目的。两种方法结合,能够使算法找到更准确的修改聚集区域与方式。实验证明,本文算法充分利用修改聚集原则,无论是抵抗SRM特征还是maxSRMd2特征,都有较好的安全性能。
致谢
DDE实验室的代码共享http://dde.binghamton.edu/download/;匿名审稿老师对本文提出了宝贵的修改意见,在此表示感谢!
基金项目
本课题得到广西自然科学基金面上项目(No. 2017GXNSFAA198371),广西大学科研基金(No. XGZ170107)资助。
NOTES
*通讯作者。