1. 引言
移动互联网的快速发展使得手机、iPad等成为人们从互联网获取信息的主要终端设备 [1]。不过,现存的网站大多是为大屏幕PC机设计的,并没有对移动端如手机进行适配,直接用手机浏览时用户体验较差。通过页面转换技术重新优化布局页面,能使其在移动终端具有良好的展示,从而实现网页对移动端的自动适配 [2]。
现存的网页自动适配方法主要分为两类。样式模板适配法 [3] [4] 将整个网页看作一个不可分割的单元,先对大量网页进行聚类,生成每一类网页对应的模板,构成模板库。在适配网页样式时,计算网页的结构与库中模板的相似度,并选取相似度最高的模板作为该网页的样式模板。由于网页数量庞大,结构复杂多变,这种针对完整网页设计的模板与待适配网页特性的吻合度低,且相似度计算开销大,难以满足网页适配的实时性要求。
网页分割适配法 [5] [6] [7] 将网页分块后再进行移动端适配,在一定程度上避免了样式模板适配法的缺陷。由于目前的多数网页均采取标签与样式分离的原则设计,其网页样式信息主要保存在外部CSS样式表中,网页内部含有的样式信息很少,很容易造成分割后的页面样式信息丢失 [8]。要使分割后的页面块符合移动端设计要求,必须重新设计块的样式,如何有效处理这些样式是算法成功的关键。
本文提出了一种基于模块化样式模板匹配的混合式适配方法。该方法先将组成网页的页面块归结为有限类型并建立样式模板库。在适配样式时,利用分割技术将网页分块,并映射到有限类型,再依据页面块所属类型与对应类别的样式模板关联,进而完成各页面块乃至整个网页的适配。该方法能够简化样式模板库的构造,提高效率,对结构复杂的页面也有更好的自适应性。
2. 页面块分类
2.1. 页面块分类依据和流程
页面块分类是模块化样式模板匹配的基础。按照页面块功能或风格特征,本文共设置了图片组/轮播图、导航、页面主体/正文、侧边栏、图片链接列表、非导航链接列表、页眉和页脚8个类别,基本覆盖了常见的Web页面组成元素。页面块分类算法主要依据HTML5中的如下标签和属性进行:
1) HTML5中的语义化标签;
2) 常见的class和id;
3) 页面块的属性和标签。
具体分类时,算法将按照1)、2)、3)顺序依次对页面块进行判别。这里假设ni为某页面经分割后形成的一个页面块,具体分类步骤如下:
Step1:判断页面块ni是否包含语义化标签,如果包含,使用语义化标签分类;否则,进入下一步;
Step2:判断页面块ni是否包含常见的class和id,如果包含,使用常见的class和id进行分类;否则,进入下一步;
Step3:判断页面块ni是否至少满足一个属性值和标签条件,如果包含,依据页面块的属性值和包含的标签判断类别;否则,将页面块归为其他类别。
2.2. 基于HTML5中的语义化标签的类别判断
HTML5引入了一批新的标签和属性,这些标签使得HTML在定义了网页结构的基础上还可以定义网页的内容类型,使开发者构建网页更加便利且易于搜索引擎识别 [9]。表1列出了HTML5引入的新的语义化标签及其定义的内容区域描述,页面分类可以根据这些语义化标签直接判断页面块类型。例如,

Table 1. New semantic tags introduced by HTML5
表1. HTML5引入的新的语义化标签
2.3. 基于class和id的类别判断
现有很多的网页样式表中用于CSS选择器的class和id的命名已经形成了行业内的默认规范,例如header、footer、nav、article、left、right等。表2为部分常见的class和id以及它们对应的含义。依据class和id判别页面类别时,其中的版权信息可划分为正文类,其他相关链接可划分为链接列表类。若页面块包含多个常用class和id,则以更靠近根节点的标签的class和id为准。
2.4. 基于页面块属性值和包含关系的类别判断
组成网页的各个不同内容块的标签和内容往往差别很大。例如导航块就是由一个或多个短文本链接列表组成的,网页的正文通常包含大量的文字,版权信息一般在页面底部等。因此本文利用这些不同页面块的特征来判断页面块类别,将页面块的图片数量、链接数量等9个属性作为判断依据 [9],其对应的特征量和判定条件如表3和表4所示。其中,表3中中心相对横坐标代表的含义是页面块的中心坐标点与页面垂直中线的距离。
Table 2. Some common classes and ids
表2. 部分常见的class和id
Table 3. Feature attributes of page blocks as the judgment basis
表3. 作为判断依据的页面块特征属性
以导航块的判定条件为例,表4的判定条件意味着当页面块中链接数量大于等于3个且平均链接文本长度小于12字节,而且页面块的HTML代码包含
当页面块的属性符合多个条件时,规定当前页面块的类别优先级由高到低依次为:图片链接列表→导航、非导航链接列表→页面主体→图片组→页脚、页头、侧边栏。
Table 4. Determination conditions of the page block type
表4. 页面块类型判定条件
3. 页面块样式模板库的构造
网页分割后,需要对分割后形成的页面块进行模板的匹配,因此需要针对每一类页面块的特点设计相应的模板。
3.1. 样式模板设计要求
针对用户操作移动设备的习惯和移动端屏幕的特点,保证适配后的页面拥有良好的用户体验,设计的样式模板应遵循以下要求:
1) 将垂直滚动设为浏览页面的主要方式,避免水平滑动。
2) 样式模板的元素使用相对宽度与位置,确保能够适配不同的移动终端分辨率。
3) 图片等比例缩放至与屏幕同宽,但缩放过程不能超过图片的原始尺寸。
4) 每个页面块的宽度与屏幕宽度相同,并能够根据屏幕宽度自动微调布局。
5) 响应元素一律设置为块级元素,适当扩展可点击区域的边缘。
3.2. 样式模板设计
以文字导航模块为例说明模板设计方法。本文设计的导航块样式模板分为标签式文字导航、隐藏式文字导航两种,是否隐藏以及标签列数可以根据目标页面的导航链接的数量自动调整。图1和图2分别为3列和4列文字导航的样式模板示例。
由于移动端屏幕空间有限,不宜展示PC端复杂繁多的导航列表,所以当网页中导航栏的链接数量过多时,应考虑将导航隐藏,用户需要导航时则可以点击按钮来弹出导航。这种隐藏式导航在移动端的显示效果如图3和图4所示。

Figure 1. Three-column text link navigation
图1. 三列文字链接导航
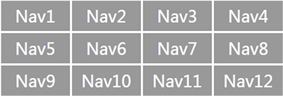
Figure 2. Four-column text link navigation
图2. 四列文字链接导航
当一个页面中所有的页面块均匹配了相应的模板后,也就完成了页面的适配过程,如果页面块分类过程中出现了其它类,则此页面块会适配通用样式模板。通用样式模板只对页面中图片、列表和链接等组成网页最基本的元素进行处理,不添加影响网页结构的样式。图5为完整的页面模板示例。
4. 实验与结果分析
实验分为两个部分:页面块分类方法的准确性测试、经适配后的网页在移动终端的显示效果测试。其中,页面块分类测试之前,首先要进行网页的分割。
4.1. 网页分割算法的选取
网页分割算法主要分为基于视觉特征、基于文本信息、基于标签以及基于DOM树的方法。其中作为当前广受关注的分割方法,DOM树法是利用了HTML文档经过DOM解析后可以形成准确描述网页中各个元素之间层次关系,且便于计算机处理的树型结构这一特点而提出的。本文采用的网页分割算法为一种改进的基于DOM树的网页分割算法 [10],综合考虑了DOM树节点的内容特征和结构特征,利用节点信息熵和最大子树文本密度来衡量一个节点是否为独立的页面块,最后通过节点融合生成网页的分割结果。该算法相对准确且能快速地对网页进行分割。
4.2. 页面块分类方法测试
本文随机选取了新闻类网站、企业机构的门户网站、论坛社区类网站的主页及其子页等100个结构不同的网页作为分类方法的测试对象。设网页Pi为网页集中第i个网页(1 ≤ i ≤ 100),Ai为Pi的页面块分类准确度,其定义如公式(1)所示:
(1)
其中,
为Pi中正确分类的页面块数,
为Pi经分块算法分割形成的页面总块数。则评价所有页面块分类准确度A的定义如公式(2)所示:
(2)
测试方法为页面块自动分类后的类别与人工标注的类别进行对比,类别相同即为分类正确,反之分类错误。经实验测得的准确度A为78.15%。通过对错误分类的页面块进行分析,发现造成错误分类的主要原因是网页分割错误,将原本应属于同一区块的内容进行了过度分割,或没有将本应属于多个页面块的内容进行分割。图6为错误分割的页面示例。

Figure 6. The webpage segmentation result of the original algorithm
图6. 原始算法的Web页面分割结果
通过对网页分割算法的阈值进行手动调整(阈值在算法中决定分割的粒度),使其能够正确地对网页进行分割。对分割结果进行修正后,经实验再次测得的分类准确度为89.52%,此时造成错误分类的主要原因包括页面块结构的特殊性、页面块HTML代码的不规范,以及存在无法自动修复的语法错误等。
4.3. 样式模板匹配实验
样式模板匹配以国内某高校门户网站的主页为例进行测试,该网页的PC版页面经调整阈值后的页面分割算法分割后的结果如图7所示。其中,每个矩形框内的内容即代表经页面分割后此区域的内容为一个独立页面块,该页面经适配后的结果如图8和图9所示。
图中可见,该页面分割后的页面块被归类为页眉、导航、轮播图、图文链接导航、链接列表等类型,并分别匹配了对应的样式模板。其中,原网页中文字导航的数目为13个,此时导航块采用隐藏式导航的样式模板;图文链接导航数量为9个,采用九宫格式的样式模板;原网页中的图片进行了缩放处理,链接列表也进行了自动换行处理。样式模板匹配完成后,将所有页面块在垂直方向重新组合即可形成适合在移动端浏览的完整的页面,此时该页面的页面元素布局和字体大小比较合理,用户浏览页面时只需上下滑动,无需缩放或左右滑动页面,部分不适合在移动端显示的内容也做了精简处理。经模块化样式模板匹配后的页面非常适合在移动端进行显示且更符合用户的操作习惯。

Figure 7. The webpage segmentation results after adjusting the threshold
图7. 调整阈值后算法的Web页面分割结果
5. 结语
本文提出了一种模块化样式模板匹配方法。利用网页分割结果,将结构简单、类型有限的页面块作为模板匹配的基本单元,相对于传统的基于网页的整体匹配,模块化样式匹配更加灵活也更易实现,且通过组合简单的样式模板就能应对较为复杂的页面,使其更符合移动端页面的显示要求,用户体验更好。在未来的工作中,可以将页面块分类规则与现有的视觉信息提取技术和文本的语义信息分析技术相结合,以提高分类的准确率。
基金项目
本文受辽宁省教育厅科学技术研究项目:产业信息服务平台的微信平台迁移技术研究(LFGD2017014)资助。