1. 引言
分位数回归模型传承于经典最小二乘回归模型,相比于经典最小二乘回归模型,分位数回归模型提供了更多的信息,有利于解释因变量与自变量之间的关系。近年来,分位数回归在各个领域得到广泛的应用,很多学者越来越关注因变量在任意分位数水平下与自变量的关系。
1978年Koenker首次提出“分位数回归”概念 [1],用于解释因变量与自变量之间的关系。1999年Koenker和Machado研究了非对称拉普拉斯分布和分位数回归之间的关系 [2]。2001年Keming Yu [3] 介绍了一种贝叶斯分位数回归思想,采用基于非对称拉普拉斯分布对参数进行估计,并证实无论数据的原始分布如何,使用非对称拉普拉斯分布对贝叶斯分位数回归建模是一种非常自然且有效的方法。自此,贝叶斯估计方法在分位数回归中有越来越多的应用。
目前,对于分位数回归模型的研究,基本集中在贝叶斯分位数估计、离散选择分位数回归估计、分位数处理效应模型以及无条件分位数回归方法的研究。针对贝叶斯分位数回归估计,它的关键在于将误差项设定为服从某种分布,由于非对称指数幂分布的优良性质比非对称拉普拉斯分布较好,而且非对称拉普拉斯分布还是非对称指数幂分布的一个特例,本文利用这一思想,使用非对称指数幂分布的似然函数来进行贝叶斯分位数回归参数估计。
2. 非对称拉普拉斯分布与非对称指数幂分布
对贝叶斯分位数回归模型进行参数估计,需要假定分位数回归中的误差项服从非对称拉普拉斯分布或者非对称指数幂分布。根据概率密度函数构建极大似然函数,依据贝叶斯定理,从参数先验分布中求解后验分布。两种分布的概率密度函数如下:
非对称拉普拉斯分布(Asymmetric Laplace Distribution, ALD)的概率密度函数为:
(1)
其中,
为偏度参数,
为尺度参数,
为位置参数。
非对称指数幂分布(Asymmetric Exponential Power Distribution, AEPD)是由Zhu Dongming [4] 等提出的,其概率密度函数为:
(2)
其中,
为gamma函数,
为偏度参数,
为尺度参数,
和
分别控制左尾和右尾参数,
为位置参数。当
和
时,AEPD分布为对称的指数幂分布;当
和
时,AEPD分布为标准的正态分布;当
时便是ALD分布;
值越小,则左尾(右尾)越厚,
值越大,则分布呈现为左偏。
3. 贝叶斯分位数回归
在进行贝叶斯分位数回归模型的参数估计时,需要构建一般线性回归模型,假定回归模型中的误差项服从ALD分布与AEP分布,对此构建相应的似然函数。通过贝叶斯定理、参数先验分布求解该分布的后验分布。由于似然函数的复杂性,为了更快的求解后验分布,采用吉布斯抽样算法的思想。
3.1. 设线性回归模型
(3)
其中,
为自变量,
为因变量,
为未知参数向量,误差项
和
。
3.2. 非对称拉普拉斯分布似然函数(ALD)
根据假设分位数回归模型的误差项服从ALD分布,其似然函数为:
(4)
其中,
。
为了在分位数回归中采用吉布斯算法,因此参考2011年Kozumi和Kobayashi [5] 在文章中给出的吉布斯抽样方法,对此进行贝叶斯分位数回归参数估计。
3.3. 非对称指数幂分布似然函数(AEPD)
Naranjo在2012 [6] 和2015 [7] 年对SEP分布和AEP分布进行相关的研究,提出了关于非对称指数幂相关的理论和方法。
设
,
,且概率为
,和
,
,且概率为
,则
。
根据假设分位数回归模型的误差项服从AEPD分布,其似然函数为:
(5)
其中,
,
,
,
,
。
根据贝叶斯定理,参数的联合后验密度为:
(6)
其中,
均为待估参数的先验密度函数。
设定参数的先验分布为:
(7)
其中,
为参数为1的指数分布,IG为逆伽玛分布,Beta为贝塔分布,N为正态分布,
为多元正态分布。
根据贝叶斯定理可得参数的待估后验密度为:
1)
(8)
(9)
其中,
为指示函数。
2)
(10)
当
时,
,化简为:
当
时,
,化简为:
由此可得:
。
3)
(11)
当
时,有
化简可得:
4)
(12)
(13)
5)
设
为不含第j个参数的向量,
的先验分布服从多元正态分布,根据贝叶斯定理和多元正态分布性质可得:
(14)
其中,
,
,
;由似然函数可知:
当
时,化简为:
当
时,化简为:
由此可得:
4. 数据模拟分析
针对一般化的形式,数据由以下设定生成:
(15)
由于不同的误差项分布会影响分位数回归系数的变化,本文将讨论误差项
和
,生成两种不同的模拟数据。
图1给出了标准化非对称拉普拉斯分布的密度图。从中可以看到,随着偏度参数(p)不断的变化,该分布也呈现出不同的变化:当
时,ALD密度图的取值集中在中右尾,当
时,ALD密度图呈现左偏现象,取值偏在右尾,当
时,两侧分布是对称的。

Figure 1. Normalized asymmetric Laplace distribution (ALD) density map
图1. 标准化非对称拉普拉斯分布(ALD)密度图
图2给出了非对称指数幂分布(AEPD)随偏度参数(
)变化密度图。从图中可以看到,随着偏度参数
不断的增大,该图呈现左偏现象。
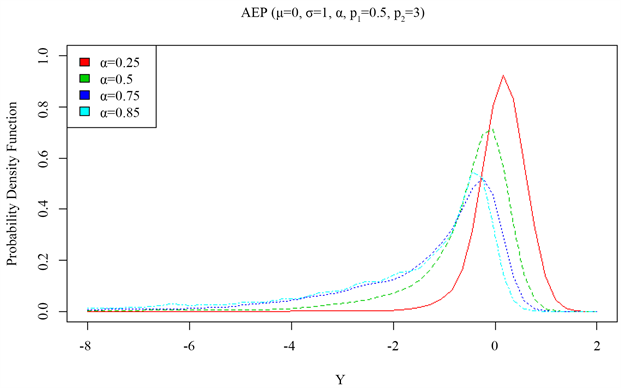
Figure 2. Density diagram of asymmetric exponential power distribution (AEPD) with skewness parameter (α)
图2. 非对称指数幂分布(AEPD)随偏度参数(α)变化密度图
图3给出了非对称指数幂分布(AEPD)随着左尾参数(
)变化密度图。从图中可以看出,随着左尾参数
不断的减小,该分布呈现左尾厚重的现象。
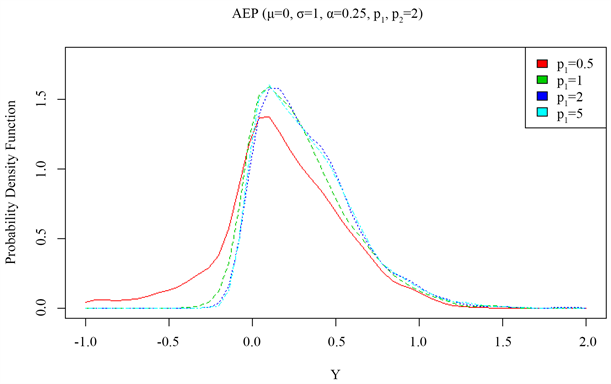
Figure 3. Density diagram of asymmetric exponential power distribution (AEPD) as a function of the left tail parameter ( p 1 )
图3. 非对称指数幂分布(AEPD)随着左尾参数(
)变化密度图
图4给出了非对称指数幂分布(AEPD)随着左尾参数(
)变化密度图。从图中可以看出,随着左尾参数
不断的减小,该分布呈现右尾厚重的现象。
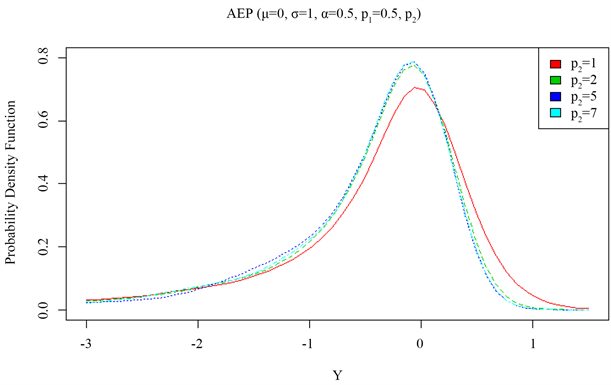
Figure 4. Density diagram of asymmetric exponential power distribution (AEPD) with the right tail parameter ( p 2 )
图4. 非对称指数幂分布(AEPD)随右尾参数(
)变化密度图
针对模型(15)产生相应的分布数据,ALD分布随机数可由R语言中ald包中的rALD函数生成;对于AEPD分布随机数可由3.3节中生成。采用Gibbs抽样算法对两种分布进行参数抽样,在对非对称指数幂分布进行参数抽样时,可依据(8)、(9)、(10)、(11)、(12)、(13)和(14)进行贝叶斯条件后验密度参数抽取。从条件后验密度中可以看出,对每种共轭分布进行参数抽样时,都必须进行截断处理,可使用R语言中的LaplacesDemon包,对常见的截断分布进行随机数抽样。

Table 1. Comparison table of estimated simulated values and true values following ALD distribution and AEP distribution
表1. 服从ALD分布和AEP分布的估计模拟值与真值对照表
从上表1中可以看出,非对称指数幂分布对于贝叶斯分位数回归来说是非常适应的,由于非对称指数幂的优势,在处理数据的偏度和重尾时,非对称拉普拉斯分布就稍逊一些,ALD分布只能处理偏度问题,对于拖尾的数据,ALD分布并没有参数对其进行控制,所以AEP分布相对处理起来就比ALD分布灵活一些,也更适合现在的数据。在低分位点和高分位点可以看出,对于未知参数的估计有所变化,ALD分布的参数估计使得参数值在变小,而AEP分布的参数估计却在变大。也可以看到,AEP分布在其他未知参数的估计也比较接近真实值;在样本量为25时,AEP分布的模拟结果更加接近真实真;在样本量为100时,各分位点下,AEP分布的模拟结果都稍接近真实值。
图5中给出了样本量为100时,迭代5000次,去掉前500次,服从ALD分布的
,
在0.25分位点的MCMC抽样轨迹图,可以看出,均在设定值上下波动,因此抽样构成的马尔科夫链收敛。
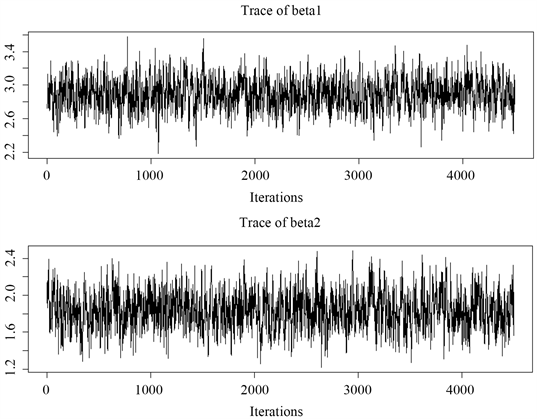
Figure 5. Traces of MCMC sampling values of
and
following ALD distribution
图5. 服从ALD分布的
,
的MCMC抽样值轨迹图
图6中给出了样本量为100时,迭代5000次,去掉前300次,服从AEP分布的
,
在0.25分位点的MCMC抽样轨迹图,可以看出,均在设定值上下波动,因此抽样构成的马尔科夫链收敛。
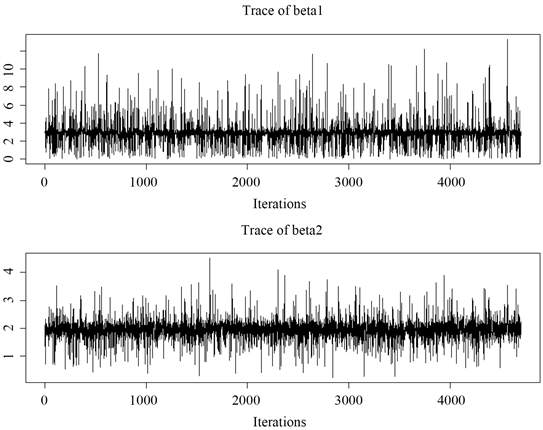
Figure 6. Traces of MCMC sampled values of
and
following AEP distribution
图6. 服从AEP分布的
,
的MCMC抽样值轨迹图
5. 结束语
本文对贝叶斯分位数回归的参数估计,从以往的ALD分布扩展到AEP分布,并对ALD分布和AEP分布进行Gibbs算法抽样。从ALD分布和AEP分布的密度图可以看出,AEP分布相对于ALD分布来说对于数据的适应性更强。从模拟的情况来看,AEP分布针对数据在低分位和高分位时,参数的估计值会比较接近真值,这也体现了它的优势。由于AEP分布的特点,AEP分布在金融数据中会得到更好的运用,由于金融数据的复杂性,ALD分布在厚尾状况下,无法对数据进行处理,而AEP分布刚好能处理这方面的问题。