1. 引言
股票投资是广大投资者投资理财的重要组成部分,银行类企业股票是股票市场中一类重要的股票。银行类股票占有市场的权重较大、一般业绩都比较好、抗风险能力强,它是股民广泛关注的一类股票。因此,有必要研究银行类股票的投资。讨论市场上投资的方法主要有量化投资、基本面分析与技术分析等三种。 技术分析是更常用的一类方法,它以股票价格作为主要研究对象,从历史K线图入手,分析总结价格波动规律 [1] [2]。但少有文章研究银行类指数与其成分股之间的关系。本文以银行类指数及其成分股为研究对象,以源于大智慧应用软件的数据为研究样本,基于R软件,通过聚类分析、回归分析、岭估计等多元统计方法,处理异常数据、消除变量间的多重共线性,得到描述股指与成分股的最优变量,并据此给出复合实际的银行类指数和其成分股之间的线性回归方程。其中样本数据包括银行类指数(指数代码BS991017)及其19支成分股从2014年10月30日至2014年11月18日的15分钟K线收盘价,共计222个样本数据,原始数据从略。在这段时间内,对于缺失的股票数据采用上一时段的数据补齐。
2. 银行类指数成分股的基本统计分析
轮廓图和调和曲线图均为多元数据的可视化方法,它们基于“线”的形式,将高维数据映射到低维空间(三维以下)内表示多元数据出来,同时兼顾信息损失最少和利于肉眼辨识,这有助于进行变量的聚类分析 [3]。基于研究样本,由R软件得到其轮廓图与调和曲线图。在样本轮廓图横坐标上取19个点,依次表示19个成分股(即变量),每个拐点代表一支股票;纵坐标对应各个成分股经过标准化变换后的观测值。由轮廓图可以发现6号股票安信信托,指标变动范围非常大。与之相比较,四大国有银行(10号、11号、13号、14号)指标相对较小,而且表现也很平稳。而所研究样本的调和曲线图显示各曲线基本上拧在一起,只是不同成分股的活跃程度大不相同。
变量聚类法是多元统计中的一种重要方法。在系统分析或评估过程中,为避免遗漏某些重要因素,在一开始选取指标时,往往考虑尽可能多的相关因素。这会导致变量过多、变量间的相关度高,给系统分析与建模带来很大的困难 [4]。因此,需要研究变量之间的关系,按照变量之间的相似关系将其聚合成若干类,进而找出影响系统的主要因素。现将银行类19支成分股按照2014年10月30号到2014年11月18号的收盘价进行聚类分析。利用SPSS进行成分股聚类,聚类结果显示不管将这19支股票分成几类,陕国投A、安信信托、爱建股份始终单独分成一类,没有和其它16支股票聚类在一起的。同时我们也可以看出南宁银行、宁波银行、北京银行、平安银行也逐渐被分出来,而且单独成为一类。
3. 银行指数和成分股的正回归分析与回归诊断
运用最小二乘法无偏估计模拟参数,对于银行类指数及其成分股,可以得到如下线性回归方程:
。
其中
表示银行指数,
表示19支成分股。从回归方程中可以看出,仅截距项是负的。经计算可得此时的残差平方和为2547.926,与其他估计方法所得的残差相比,该残差平方和是最小的。
根据指数的编制方法可知,回归系数出现负值虽然真实地反应了一段时间内,指数与成分股的实际相关关系,但这种负相关是不正确的,这是因为指数公式中每个成分股对指数的贡献都是正的,即均正相关。此时需要考虑非负最小二乘问题。R软件中的nnls数据包提供了非负系数的计算结果,虽然大部分都是正系数,但仍然有些变量的系数为零 [5]。由于对于指数公式,所有成分股的权重都不会是零,因此这也是不符合要求的。若成分股对成分指数无贡献,该成分股的存在则不合理了,此时需对模型进行修正从而得到正回归结果。
银行类指数是19只成分股股价的加权平均,权重与成分股的市值有关,因此银行类指数是各个成分股的线性函数,它受所有股份股的影响都应该是正的,且不应该有常数项。进行正回归分析,为了避免出现零系数,采用限定最低门限的方法,参考银行类指数板块最小市值股票/总市值 = 4891.9/1142308.8 = 0.004282467,以此为阈值,利用nnls计算,得到所有系数为正的回归系数。计算出残差平方和为2566.827,并画出残差图(图1)和实际走势与正回归预测的效果图(图2)。从两图可以看出,残差服从白噪声分布,并且预测基本和实际走势吻合。

Figure 1. The residual graph of positive regression analysis
图1. 正回归分析残差图
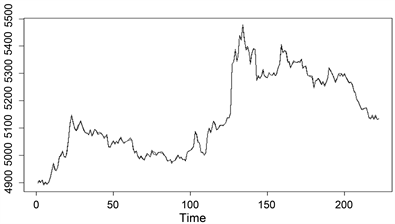
Figure 2. The fitting diagram of positive regression
图2. 正回归拟合图
为进行残差分析和探测异常点,需进行回归诊断。首先讨论残差分析,考虑回归分析模型
。
对于随机误差
需满足如下假设:1) 正态性;2) 零均值;3) 等方差;4) 独立性。
如果实际数据与这些假设偏离较大,则最小二乘估计不能保证其仍是无偏估计或有效估计,也不能进行进一步的假设检验和区间估计,此时得到的回归方程失去了意义,由此得到的分析结果不再成立。上述假设不成立便会引起随机误差
分布的变化,从而导致残差的分布变化。因此可以通过对残差“表现”的分析来诊断关于
的哪些假设不满足,此即残差分析。这也是回归诊断需要解决的第一个问题 [5]。
残差图是进行残差分析较为简单且效果较好的方法。正回归残差图1是关于时间序列的残差,可以看到残差基本上是白噪声的,从而可推断随机误差满足假设。此外,也可以绘制残差关于预测值的散点图,散点图显示残差大致在一个纵坐标为0的中心带状区域内随机散落,无规律性和趋势性,由此可推断随机误差大致满足四条假设。
另一方面,检查残差是否服从正态性假定是必要的。关于正态性的假设的检验,可采用Shapiro-Wilk正态性检验(简称W检验)作更准确的检验。通过R程序计算,W = 0.9928,p-value = 0.3587,即显著的概率是0.3587,因此残差满足正态性假设,接受正态性假设。
异常点的探测是回归诊断的第二个问题。如果一组数据的残差比其它组数据的残差大得多,我们称其为异常点。由于异常点可能对回归的估计以及其他推断具较大影响,所以异常点探测尤为必要。我们用基于距离的方法来检测收集的银行类股票数据中的异常点,主要有COOK距离法、WK距离法以及协方差比准则 [5]。可以得到如下检测结果:
1) 用COOK距离来诊断,R程序运行结果显示距离值较大的两个是135号(3.170640e−02)和27号(4.866316e−02),即11月11日和10月31号的数据。经查,这两天银行类指数出现上涨。同时分析其他板块,房地产、建筑等指数那两天表现很平庸。数据上确实存在异常。
2) 运用WK距离法运行R程序,发现222个样本数据中总共12个异常值,由此可以看出,样本中数据有异常,但是异常不是太大。
3) 继续用协方差比来诊断,R程序运行结果显示132号样本的协方差比值与1的偏离超过0.92,对应的是11月11日的数据,经查,这天指数出现上涨。仍然和建筑、房地产等其他板块相比较,而这几个板块指数表现平稳。这说明,该样本点对模型的影响还是存在的。
由回归诊断函数可以看出,不管是用上面三个准则中的哪一个,均发现27号,132号,135号,即10月31日和11月11日的数据比较异常,尤其是11月11日这天的数据。通过观察11月11日这一天银行类的股票走势可以看出,这一天的股票是持续涨高的,这可能是“双11”掀起的购物狂潮而引起的,其中中国银行、农业银行,工商银行涨势更高。
4. 银行指数和成分股回归分析的有偏估计
在回归分析过程中,进一步分析样本数据可以发现变量间存在严重的多重共线性。经计算,19个变量间相关矩阵的条件数为2885.554,大于1000,最小特征值是0.0049,均方误差MSE近乎无穷大,这导致最小二乘无偏估计没有意义,因而不可再用。有偏估计是解决多重共线性最直接的方法,比较有代表性的有偏估计有均匀压缩估计、主成分估计、岭估计、刘估计、几乎无偏估计等。
下针对前述回归分析中出现的共线性问题,用岭估计的方法来估计回归系数。岭估计通过解决如下的条件极值问题获得
,
其中k拉格朗日乘数。岭估计有如下表达式
。
其中
是岭参数。通过对k值的选择,可以减少多重共线性的影响,取不同的k值,可以得到不同的估计,因此岭估计
是一个估计类。当
时,
即为常用的最小二乘估计 [5] [6] [7] [8]。
由于岭估计含有一个参数k,因此作岭估计之前需先选择合适的k。实际中如何选择k,可有多种方法。首先考虑通过岭迹法选择岭参数。岭迹法的方法是将p个分量
的岭迹画在同一个图上,参数k的选择要使得岭估计
的各分量的值大体稳定,并且要兼顾到系数没有不合理的符号,残差平方和上升不太多等 [5]。绘出岭迹图,由岭迹图可知当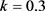 时,各条曲线基本趋于稳定。
时,各条曲线基本趋于稳定。
此外,R软件还通过函数select()提供了三种选择岭参数的方法,分别是HKB (Hoerl-Kennard-Baldwin)选择,L-W (Lawless-Wang公式)选择和GCV (Generalized Cross Validation)最小值选择。
通过R程序,HKB选择、L-W选择与GCV选择分别给出的k值为0.06、0.01与0.16。由于岭估计是一种有偏估计,是求解回归系数时的一种无奈之举,因此总是倾向于选择偏差较小的有偏估计。对于岭估计而言,
就是无偏估计,因此通常选择较小的k值。故此时取L-W选择给出的参数
,因此得到如下经验回归方程
。
由于原来的最小特征值0.0049经过岭参数的附加,变成了0.0149,均方误差大幅降低,模型中存在的多重共线性明显得到改善,而此时模型的残差平方和为2548.012,和最小二乘无偏估计相比几乎没有增加。因此岭估计在银行类指数及其成分股的参数模拟上是比较理想的。
5. 银行指数成分股最优子集的选择
对于大量金融数据,不同的变量有着不同的影响,部分变量影响甚微,部分变量具有高度的关联性。考虑到数据收集的成本和分析的时效,并不需要收集全部变量。因此在对金融数据的统计分析中,变量的选择变得尤为重要。此外,基金管理者,投资所有股票并不现实,往往只能选择部分成分股进行投资,用尽量少的变量达到对指数的追踪,从而实现持有的股票组合与股指期货空单形成完全对冲,达到保值的目的 [5]。从上面的绝对约束估计可以看出,用该方法并不能很好的实现符合该目的变量最优子集的选择,所以需要进一步进行变量选择。变量选择的方法很多,本文中采用绝对约束估计(Lasso)和弹性约束估计来完成银行类指数成分股最优子集的选择。
绝对约束估计就是要找到满足条件
,使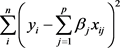 达到最小的
。其中
是一个调整参数,它控制着估计压缩的程度。设
是普通最小二乘估计,
,当
将
达到最小的
。其中
是一个调整参数,它控制着估计压缩的程度。设
是普通最小二乘估计,
,当
将
引发趋向于0的压缩,因此绝对约束估计也是压缩估计 [9] [10] [11]。
R软件的Lars软件包提供了解决实际中的变量选择问题的方法。Lars算法中有一个正则化参数
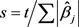 ,可以采用BIC (bayes information criterion)准则来选择最佳的s。其中BIC准则是一种变量选
,可以采用BIC (bayes information criterion)准则来选择最佳的s。其中BIC准则是一种变量选
择的准则,即选择使得BIC统计量
(p表示所选模型变量的个数(含常数项))达到最小的模型。变量选择的具体步骤是通过Lars中的predicts函数参数s的设置,给出不同的变量子集和回归系数,通过对结果的分析,算出BIC值,选择BIC达到最小的s值即可 [5]。求得样本数据BIC值最小值为10.21,对应的
,最优子集含有14个变量,残差平方和为3097.37。由此得到的含有14个变量的回归模型为
。
模型中不包含
(陕国投A)、
(安信信托)、
(爱建股份)、
(平安银行)、
(宁波银行)这5支股票变量。
进一步,可以得到自变量和预测值的拟合图(图3),从图中可以看出,拟合效果较好。
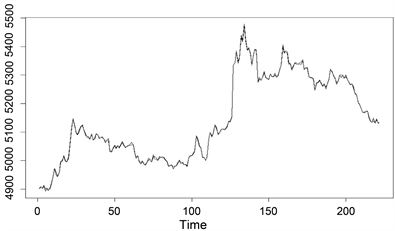
Figure 3. The fitting diagram of absolute constraint estimation
图3. 绝对约束估计拟合图
尽管在很多情况下绝对约束估计都得到很大认可,但在某些条件下其有效性也会受到限制,尤其是在面临高维数据的时候。当变量个数p大于样本容量n时,绝对约束估计只能选出n个变量,此时绝对约束估计就不再有效。即使是一般情形
的情况下,有时岭回归估计比绝对约束估计表现的要好。
2005年邹(Zou)和赫斯第(Hastie)提出合并考虑岭回归和Lasso的约束方式,提出了弹性约束估计 [12]。其定义如下
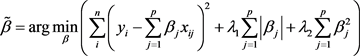 ,
,
这等价于找到满足条件
,使
达到最小的
[13]。
显然,弹性约束估计同时具有绝对约束估计和岭估计的特点。在弹性约束估计中,当参数
时弹性约束估计为岭回归,当
时弹性约束估计为绝对约束估计。
在R软件中,较为方便的是可利用函数cv.glmnet进行自动CV交叉验证,从而确定出最佳的
值。基于银行类指数及其成分股的样本数据,得到
。按此参数值,R程序运行结果保留变量个数是13个,残差平方和为5233.348。这时相应的得到的最优子集当中仅含有13支股票,其中不包括
(陕国投A)、
(安信信托)、
(爱建股份)、
(北京银行)、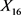 (平安银行)、
(宁波银行)这6支股票。对应的经验回归方程为
(平安银行)、
(宁波银行)这6支股票。对应的经验回归方程为
预测值拟合图如图4所示
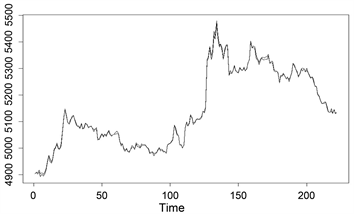
Figure 4. The fitting diagram for an elastic constraint estimate
图4. 弹性约束估计预测值拟合图
由于glmnet程序计算时结果不固定,保留变量个数在12和13之间变化。通过系数对比,发现
的系数相对较小(7.480314e−03),应该在临界线上,所以导致结果的不确定性。舍弃该变量,最终得到的回归模型中含有12个变量
。
接下来,根据指数的编制方法,进一步进行正回归分析,得到最终的回归模型为:
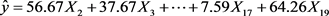 。
。
残差平方和为3109.354,残差图和预测指数追踪图分别如图5与图6所示:
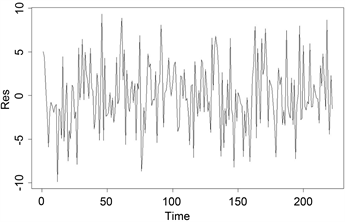
Figure 5. The fitting diagram for an elastic constraint estimate
图5. 弹性约束估计预测值拟合图
Figure 6. The fitting diagram for an elastic constraint estimate
图6. 弹性约束估计预测值拟合图
图6中符号“*”是实际银行类指数的收盘价,实线是模型预测值。易见,实际走势和12只成分股的跟踪走势基本重合,基本跟踪到了指数的运行趋势,与指数运行吻合。
回归模型中各变量对应系数具体如表1所示。在最终的回归模型中,不含有的成分股分别为
(陕国投A)、
(安信信托)、
(爱建股份)、
(南京银行)、
(北京银行)、
(平安银行)、
(宁波银行),中国有四大银行回归系数最大,可见其对银行类指数的影响是相对较大,这也与实际相符。

Table 1. The Table of coefficients of positive regression analysis for 12 variables
表1. 12个变量正回归分析系数表
6. 总结
收益与风险是相对应的,也就是两者是相伴而生的。一般地,收益高则风险大,风险小则收益低。正所谓“高风险,高收益;低风险,低收益”。许多人都知道,在有价证券投资中,股票的投资收益高,但统计发现,真正赢利的人一般只占投资者的1%左右,而且一旦投资决策错误,在股票价格下跌的情况下会损失惨重。所谓的“投资有风险,入市需谨慎”绝不是危言耸听。当然,股票市场的投资如此,其他项目的投资规律也是这样。
随着资本市场的不断发展,股票数量的增长,基金规模的扩大,信息传导的加速,量化投资策略能够有效规避非理性的负面效应,以客观的方式捕捉市场中的异常讯息,获得超额收益。
量化投资是回避金融风险的有效方法,也是当今非常重要的投资思想,但量化投资的基石是模型,只有不断地根据市场的变化,建立合理实用的投资模型才能有效的实现利益的最大化和有效的规避风险 [14] [15]。
对非结构化数据分析,将看起来相关性并不强的因子纳入量化投资模型,并分配权重,丰富量化投资模型交易的精度和维度。
在本文的分析中,从聚类结果和回归分析过程中,陕国投A、爱建股份、安信信托这三支股票的表现都不同于其他股票。这主要是因为这三支股票是普通股,而其他16支股票是沪深300指数成分股。其中,沪深300成分股在运行中有较好的盈利性、成长性和分红收益能力,同时,相对于市场平均水平,其估值优势也比较明显,已经逐渐成为投资机构投资者乃至整个市场的投资取向标杆。与之相比,作为普通股的这三支股票就会被频繁的“区别”出来。从正回归系数表1中可以看出,中国银行、农业银行、工商银行、建设银行四大银行所占权重在19支成分股当中是最大的。这是与这四大银行代表着中国最雄厚的资金力量十分不开的。
在量化投资规避风险过程中,需要注意的是数据并非绝对安全,也可能存在风险隐患。现代社会是大数据时代,大数据可能存在这样一种现象:投资者被数据包围,无法判断数据的真实有效性,对于存在缺陷的数据进行建模分析,可能导致所得到的结论不能与现实真实市场环境相一致。例如,当统计模型的样本发生了变动,最终可能导致结论不正确而无法适用于交易决策中。所以在量化投资规避风险时要注意数据陷阱的风险隐患。
基金项目
陆军工程大学基础学科培育金项目(KYJBJQZL1922);陆军工程大学基础学科培育金项目(KYJBJQZL1921)。