1. 引言
当前,关系数据库得到了广泛的使用 [1]。但是,数据库的创建、传输和共享显著增加的同时带来了如数据盗窃、非法复制和侵犯版权的安全风险。近年来,即使在数据敏感的领域,如医疗保健领域,也经常发生数据库泄漏事故的报道 [2]。从历史上看,水印技术已被用于确保各种数据格式(例如,图像,视频和音频)的所有权保护和防篡改。数据库加水印是一种相对较新的技术,将消息嵌入通常独立且离散的数据库记录中。数据库水印由Agrawal和Kiernan于2002年首次引入 [3]。此后,国内外学者提出了几种方法 [4] [5] [6] [7]。
在 [4] 中,提出了一种鲁棒的持久性水印方法,该方法同时嵌入了私人和公共水印。根据水印是否对数据库数据进行了任何更改,水印技术可分为两类:基于失真的水印和无失真水印 [8]。可逆水印可以看作是水印的一种特例,它不仅可以成功地提取嵌入的水印,而且可以完全还原出原始载体。当前,它在军事通信,医疗保健,政府安全通信和执法方面越来越受到关注。
关系数据库的第一个可逆水印方案是在2006年提出的 [9],其中直方图扩展用于可逆数据库水印。但是,这种方法对于强大的攻击并不可靠。2008年,基于差异扩展的水印(DEW)被提出。文献 [10] 的工作能够以可逆的方式给数据库加水印。Bhattacharya和Cortesi在2009年提出了一种方法 [11],将元组划分为置换后嵌入水印。但是,考虑失真约束时,DEW的嵌入率会大大降低。在 [12] 中,遗传算法(GA)被用来设计鲁棒的密钥方法。然后,一种基于差分扩展水印(GADEW)技术的遗传算法被提出,作为一种健壮且可逆的数据库水印解决方案 [13]。 [14] 中提出了一种新的可逆数据库水印方法,该方法将DEW与萤火虫算法(FFA)相结合,FFA选择最佳属性值以产生较低的失真并增加水印容量。尽管FFADEW最小化了数据失真并增加了水印容量,但是信息失真仍然很严重。2019年 [15] 提出了遗传算法和直方图移位算法GAHSW,但是其只适用于数值型数据库,实用性较差。同时其使用生成主键,前期计算量非常大。
现有的文本可逆水印方法主要存在两个问题:水印嵌入容量低、附加信息共享量大。针对这两个问题, [16] 从无损数据压缩的角度提出了一种基于自适应二进制算术编码的可逆自然语言水印算法。所提出的方法首先在每个同义词集中仅对具有最大词频的两个词进行编码,从而实现出现在封面文本中的同义词的二进制。由于封面文字中频率较高的同义词的数量远远多于频率较低的同义词 [17],量化封面文字中的同义词产生的二进制序列严重不一致,因此存在很大的冗余空间,可以提供压缩的可能性。从这一观点出发,选择自适应二进制算术编码来无损地压缩二进制同义词序列。然后,将压缩的二进制化同义词序列附加水印和一些其他信息通过同义词替换嵌入到封面文本中。通过对水印文本中的同义词值进行解码来提取水印,同时可以通过使用算术编码对提取的压缩数据进行解压缩来恢复原始同义词。
我们通过对现有的数值型水印方法进行优化,同时结合文本水印方法,构造了一种新的数据库水印方法GHSA。通过实验表明,在数值与文本并存的实际数据库上,该方法的鲁棒性更强,安全性更高,并且该方法适用范围更全面,更适合实际生产生活应用。
本文第2节阐述了我们方法所用的相关知识,第3节具体阐述了我们使用的数据库水印方案流程,第4节提供对比实验结果进行验证,最后我们在第5节得出结论。
2. 相关知识
2.1. 遗传模拟退火算法GASA
遗传模拟退火算法GASA [18] 是将遗传算法GA与模拟退火算法SA相结合构成的一种优化算法。遗传算法的局部搜索能力较差,但把握搜索过程总体能力较强;而模拟退火算法具有较强的局部搜索能力,并能使搜索过程避免陷入局部最优解。但是模拟退火算法对整个搜索空间状况了解不多,不便于使搜索过程进入最有希望的搜索区域,效率不高。将遗传算法和模拟退火算法相结合,互相取长补短,可以成为性能优良的全局搜索算法。其特点有:
1) GASA是标准GA,SA和并行SA的统一结构。
2) GASA是一个两层并行搜索结构,进程层次上在各温度下串行依次进行GA和SA搜索,其中SA的初解来自GA的进化结果,SA抽样后的解又成为GA进一步进化的初始种群。
3) GASA利用了不同的邻域搜索结构,混合算法过程中包含了GA的复制,交叉,变异和SA的状态产生函数等不同的搜索结构,增强了算法在解空间的探索能力和效率。
4) GASA搜索行为可控,混合策略的搜索行为可以通过退温历程加以控制。
5) 混合策略利用了双重准则,抽样稳定准则可以判定各温度下算法的搜索行为,算法终止准则可以判定优化性能的变化趋势和最终优化性能。
由此可见,GASA结合了两者的特点,使各自的搜索能力得到补充。GASA算法具体步骤将在第3节详细展开。
2.2. 直方图移位HSW
直方图移位于2006年首次用于数据库水印 [9]。 [15] 改进了直方图移位方法,使得该方法能更好解决水印嵌入失真问题。在HS中,使用预测变量来创建要素元素以进行扩展嵌入。
假设我们有一个属性值y和嵌入一个比特位值ω。首先我们使用公式(2.1)计算预测变量:
(2.1)
其中j为属性列的标注,然后,使用公式(2.2)计算预测误差以构造直方图:
(2.2)
在HS嵌入之前,根据直方图中的预测误差的绝对值确定具有非零频率的峰值。我们表示峰值为 ,使用数组pa存储所有p,并将其用于水印提取和数据恢复。我们使用公式(2.3)计算新的相关预测误差
:
(2.3)
然后,我们使用公式(2.4)计算新的属性值
,完成水印嵌入:
(2.4)
通过峰值数组pa以及其他辅助信息,我们可以将水印值
还原为原始属性y,并取得水印嵌入位ω。还原操作即为嵌入操作的逆操作,将在第3节给出。
2.3. 同义词替换和算术编码SSAC
我们使用的文本水印方法为 [16] 提出的同义词替换和算术编码SSAC。其采用的同义词量化规则定义为:如果同义词集中的同义词是频率最高的同义词MFS,它将被编码为“0”;如果是频率第二高的同义词SMFS,则将其编码为“1”;否则,将其视为没有编码值的普通单词。由MFS和SMFS的编码值组成的二进制序列应具有可压缩的空间,以有效地压缩为较短的二进制序列。通过自适应二进制算术编码,可以对封面文本中同义词的编码值进行压缩,然后可以无损地对其进行解压缩以恢复原始同义词。如果将压缩的二进制序列与水印信息一起嵌入到封面文本中,则可以从水印文本中可逆地恢复封面文本。由于每个同义词至少可以嵌入到一个比特信息中,因此当添加的二进制同义词序列的压缩二进制水印信息比封面文本中的原始二进制同义词序列短时,它们可以通过同义词替换成功嵌入。我们将在第3节给出文本水印添加的具体过程。
3. 数据库水印方案GHSA
本节分为三个部分,3.1节介绍遗传模拟退火算法GASA的流程,3.2节介绍对数值型数据的整体算法操作,3.3节介绍对文本数据的同义词替换和算术编码SSAC水印增加和提取算法操作。
3.1. 遗传模拟退火算法GASA
与遗传算法的总体运行相类似,遗传模拟退火算法也是从一组随机产生的初始解(初始群体)开始全局最优解的搜索过程,他首先通过选择,交叉,变异等遗传操作产生一组新的个体,然后再独立地对所产生的各个结果个体进行模拟退火,将其结果作为下一代群体中的个体。过程反复迭代进行,直至满足条件为止。下面给出模拟退火算法的流程描述:

3.2. 数值型数据整体操作
首先我们应用GASA算法获取最适合数据库分组的密钥KS,这属于我们的前期工作。然后,我们选择数据库中部分文本型数据属性列(必须非空),根据这些文本型数据生成主键PK。具体操作可以选择很多种方法,这里我们选择将文本数据转换为十六进制并将其重复循环,直至生成统一长度的主键值,长度可以由用户自己确定,但是要确保主键的长度满足互不重复的保障条件。在我们进行数据库水印提取的时候我们只要确定是哪几个属性列以及生成方法就可以确定主键,在传输过程中主键不会进行传输,节省了存储空间,同时,避免因主键被恶意删除使得水印无法恢复,从而无法确认的问题。
然后,应用该密钥,使用公式3.1对数据库的数据进行分组:
(3.1)
最后采用第2节介绍的HSW直方图移位法对数值型数据加水印。其具体算法如下所示:


其中,D代表数据库,z为用户输入的数值,其小于用户数据库数值型数据的数量。
数据库水印的提取和数据恢复是上述过程的逆过程。我们的方法在添加水印过程中并未对最大值和最小值进行变换,所以水印增加前后,
的大小是不变的,在增加了水印的数据库中存放的值为
,由此,根据公式(3.2),我们可以计算得到
:
(3.2)
将
与pa数组中存储的p相比较,我们可以通过公式(3.3)来恢复原始数据:
(3.3)
由公式(2.3)可知,如果
,有水印位ω为0,如果
或是
,则水印位ω为1。至此,水印数据也被提取出来,原始数据库也恢复完成了。
水印提取数据库恢复的具体算法步骤在此不再给出,如果有兴趣可以参考[文章1]的解密步骤,我们的方法与其方法在数值型水印提取过程大致相同。
3.3. 文本数据水印的增加和提取
信息嵌入过程完成后生成水印文本,并将压缩后的同义词序列与水印信息一起嵌入。SSAC文本水印的增加和提取流程如下。
1) 同义词识别。遍历文本并检索准备好的同义词数据库,如果单词是MFS或SMFS,则将其识别为同义词。
2) 二进制量化。将识别出的同义词量化为二进制序列。如果存在同义词,则获得n位同义词序列Q。
3) 压缩。通过采用自适应二进制算术编码将Q压缩为较短的m位二进制序列Q'。由此可以获得一些冗余空间来容纳附加水印信息。
4) 水印信息二进制化。水印信息也根据其字符的ASCII值转换为二进制序列。
5) 附加信息估计。为了将压缩的同义词序列Q'与水印信息M区分开来,当将它们串联在一起嵌入到文本中时,应将其长度记录并发送给接收者。
6) 嵌入式信息生成。附加信息与Q'和水印信息M串联,形成一个完整的嵌入式信息S。
7) 比较。将嵌入信息S与原始同义词序列Q相比较,找到某些对应位置的不匹配值。
8) 同义词替换。对于不匹配的位置,原始同义词将被其同义词替换,该同义词的编码值等于嵌入的信息位。匹配位置不会进行替换。当所有嵌入的信息位都嵌入后,带水印的文本生成完成。
带水印的文本将被发送到接收方,接收方可以提取水印信息并恢复原始封面文本而不会产生任何失真。由于同义词数据库共享,所以接收方可以很容易完成同义词的统计并进行二进制量化。在得到同义词序列 与水印信息 的长度后,接收方可以轻易完成水印提取和数据恢复,该过程即为水印添加的逆过程。
4. 实验结果与分析
本文实验采用四个随机生成的数据集对设计的算法进行实验验证。随机生成的两个数据集分别包含80条,120条和200条记录。我们从效率和鲁棒性两个方面对本方法与已知的数据库水印方法进行对比。
4.1. 效率对比
首先我们对存储效率进行分析。可知在数据库属性列越少的情况中,使用文本属性生成主键提高的存储效率就越大。同时,因为不用在传输过程中传输主键,通信效率也进一步提高了。
之后我们对遗传模拟退火算法GASA进行效率分析,将其与遗传算法GA,模拟退火算法SA,并行模拟退火算法PSA相比较。实验初始条件设置种群数为10,交叉变异概率为0.99和0.9,指数退温速率为0.9,退温条件为最优值连续20步不变。最终我们采用平均优化值的波动率即相对误差作为指标。
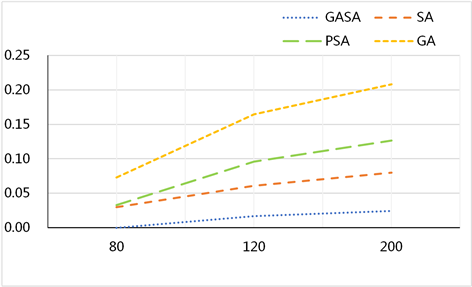
Figure 1. Comparison of perturbation rates of different algorithms
图1. 不同算法的扰动率对比
我们在三个数据库上都做了实验分析,由图1可知,遗传模拟退火算法GASA的扰动率远低于其他算法,说明其结果较好,作为密钥时计算效率更高。
4.2. 鲁棒性对比
我们采用通用的数据库增加,删除,修改三个攻击方式进行测试遗传算法和直方图位移法GAHSW,文本水印嵌入法SSAC及我们提出的综合水印法GHSA三者的鲁棒性。我们采用被破坏的水印位数与水印总体位数比值ω作为错误率来估计三种方法的鲁棒性。
首先,我们使用数据库增加攻击,我们向数据库增加随机生成的数据和部分数据修改后的数据。由实验结果可知,对于GAHSW和我们提出的GHSA方法来说这两种攻击方式均不会奏效,但是修改后的文本数据可能会对文本水印方法产生一定的破坏效果。图2是在200条数据记录的数据库中随着增加修改后文本数据的数量三种方法ω的变化。
其次我们使用数据库删除攻击。在三个数据库案例中,我们分别实行不同程度的删除攻击,然后取三个数据库收到删除数据后错误率的平均值进行分析,如图3所示。可见我们的方法比其他两种效果都要好。
最后我们使用数据库修改攻击,在三个数据库上删除20%,40%,60%,80%数据并检测出错误率,之后取平均值,如图4所示。可见我们的方法也优于另两种方法。
综上所述,我们可以认为我们的GHSA方法在安全性能上优于现有的数据库水印方法。
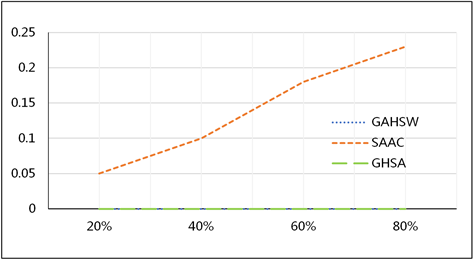
Figure 2. Comparison of the error rates of the three methods with increasing data
图2. 三种方法在数据增加情况下的错误率对比
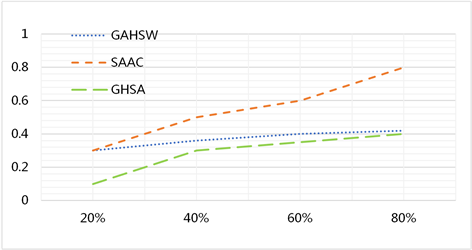
Figure 3. Comparison of the error rates of the three methods in the case of deleting data
图3. 三种方法在删除数据情况下的错误率比较
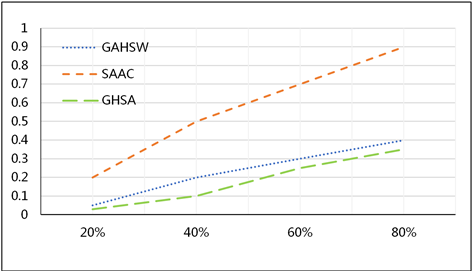
Figure 4. Comparison of the error rates of the three methods in the case of modifying data
图4. 三种方法在修改数据情况下的错误率比较
5. 结论
我们将优化后的数值型水印方法与文本水印方法相结合,构造了一种新的数据库水印方法。通过理论分析与实验验证,在数值与文本并存的实际数据库上,该方法的鲁棒性更强,安全性更高,并且该方法适用范围更全面,更适合实际生产生活应用。