1. 引言
随着我国消费市场的不断发展,市场上的消费模式已经逐步由“以物为主”转变为“以客为主”。在新零售行业,性价比不再是顾客衡量是否购买物品的唯一标准,人们的需求也不仅仅是单一的追求实用性,而是更多的考虑时尚性,把注意力放在“个性化、时尚、美观”等方面。在这类特殊需求的推动下,新零售企业的生产模式逐步向多品种、小批量迈进,这让商场内零售店铺里的饰品和玩具等种类变得更加琳琅满目,同时也给零售行业的库存管理增加了很大的难度。如何根据层级复杂,品类繁多的历史销售数据,以区域层级,小类层级乃至门店skc (单款单色)层级给出精准的需求预测,是当前大多数新零售企业需要重点关注并思考的问题。
2. 基于灰色关联分析的模型
考虑到各种因素对目标商品销售量的影响,结合实际生活和附件信息,选取了三个因素进行研究,分别是库存信息、节假日折扣、预计加权销售额。需要确定累计销售额排名前50的商品,然后可根据近大远小的加权原则 [1] 分别预测得四个节日的销售额,将此三个作为影响销售量的因子,采用灰色关联度分析得到各因素对skc销售量的影响情况。
2.1. 计算流程
本问首先需要确定从2018年7月1日至2018年10月1日累计销售额最多的skc,由于附件数据非常庞大,使用大数据的方法进行求解,求解思路如图1所示。
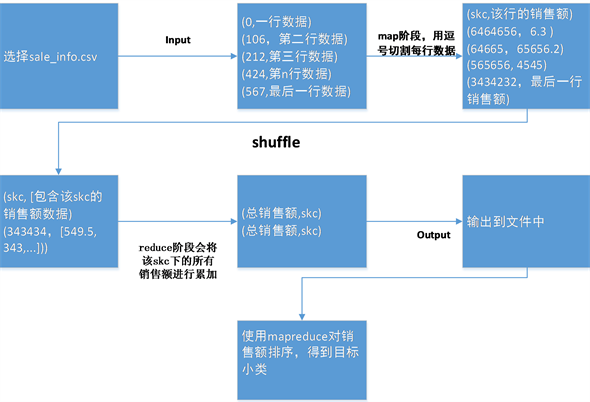
Figure 1. Flow chart of big data solving target skc
图1. 大数据求解目标skc流程图
利用大数据框架Hadoop的mapreduce进行数据处理,对sale_info.csv的数据,在map阶段对数据切割,因为csv格式是按逗号分隔的,用Java的split函数以逗号分隔。其次把skc编号作为key,把销售额当成value,同一个key会对应到同一个reduce中,对同一个key的value即销售额进行累加得到一个sum值,再将sum作为key,skc编号作为value,即可算出该skc的销售额。最后将算出的数据再次进行mapreduce,自定义排序方法为降序排序,把sum值当成key。取销售额最多的50个,即为目标skc。
2.2. 灰色关联分析模型的建立
在灰色系统理论 [2] 中,提出了一种新的关联度分析方法,即根据因素之间发展态势的相似或相异程度来衡量因素间关联的程度,它揭示了事物动态关联的特征与程度。
1) 参考数列的选取
选择某节日的目标商品你的销售量
为参考数列,则有如下表达式。
(1)
其中,i表示节日,i为0时为国庆节,i为1时表示双十一,i为2时表示双十二,k表示时刻。
2) 比较数列的选取
选择影响目标skc的变量
为比较数列,则有如下式子。
(2)
其中,j = 1时表示为第i个节日的库存信息,j = 2时表示为第i个节日的折扣,j = 3时表示为第i个节日的加权预计销售额。
3) 关联度的建立
根据灰色关联分析,得到比较数列
对参考数列
在k时刻的关联系数
,其表达式如下。
(3)
其中,
为分辨率系数,
越大,分辨率越高;
越小,分辨率越高;为了将(3)式中的各个时刻的分散的关联数集中分析,因此在它的基础上,定义一个新的式子表示
对参考数列
的关联度为
(4)
2.3. 模型的求解
代入已计算得出的结果,结果如表1所示。
总体来看,在这三个因素中,加权预计销售额的相关程度都是最高的,可见它对目标skc的影响颇大,而在双十一、双十二时期,库存相关程度都是最低的,这与实际情况相符合,现实生活中,双十一、双十二只有一天,因此商家都会预先准备充分的产品供用户购买,因此相对来说,它库存的相关程度是最低的,而在国庆时期,由于是全国统一的节假日,而且有七天的时间,用户购买欲较平常而言相对较高,而商家没有办法一次性准备充分的产品,因此货存相对而言它的相关程度就会比折扣更高。
3. 灰色预测GM(1,1)模型的建立与求解
灰色预测是指利用GM模型对系统行为特征的发展变化规律进行估计预测,同时也可以对行为特征的异常情况发生的时刻进行估计计算,以及对在特定时区内发生事件的未来时间分布情况做出研究等等。这些工作实质上是将“随机过程”当作“灰色过程”,“随机变量”当作“灰变量”,并主要以灰色系统理论中的GM(1,1)模型 [3] 来进行处理。
3.1. 数据准备
本问首先需要确定从2019年6月1日至2019年10月1日累计销售额最多的小类,由于附件数据非常庞大,使用大数据的方法进行求解,求解思路如图2所示。
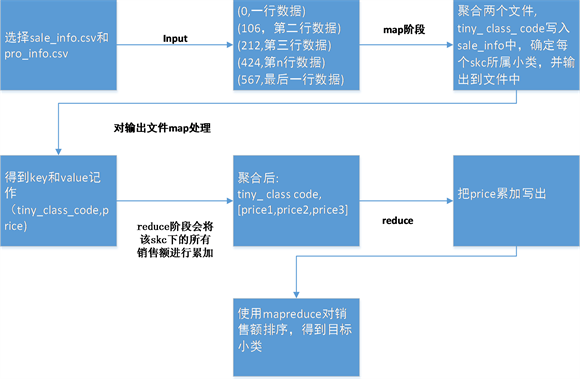
Figure 2. Flow chart of solving target subcategories of big data
图2. 大数据求解目标小类流程图
由图可知,确定目标小类时需要使用附件sale_info.csv和prod_info.csv的数据,首先对其进行一次map聚合,把prod_info附件中的tiny_class_code属性写入到sale_info.csv的与之相对应的skc,以此确定每个skc所属小类。其次对sale_info的数据,使用大数据技术,在mapreduce和map阶段,对一行数据切割,取tiny_class_code作key,取销售额为value,同样写入reduce,同一个key写入同一个reduce,将销售额进行累加,得到每个小类的销售额。最后把tiny_class_code为key,总销售额为value,即可得出21个小类在2019-06-01到2019-10-01中的销售额,选出前十的小类即可。
3.2. 灰色预测GM(1,1)模型
1) 参考数列的选择
本问主要研究的是预测问题,即预测目标小类在2019年10月1日后3个月中每个月的销售量,因此选择各小类的1到9月的销售量作为参考数列
,其中
(5)
m表示第几个小类,n表示第几个月。
2) 累加数列与均值数列的选择
在式(5)的基础上,做一次累加(AGO)得到累加数列
,则有
(6)
在此基础上,得到均值数列
(7)
3) GM(1,1)模型的建立
基于参考数列、累加数列和均值数列建立得到灰微分方程为
(8)
由最小二乘法求得达到最小值的
,因此可以求得(1,1)模型为
(9)
3.3. GM(1,1)模型的求解
为了保证模型的可靠性,需要对数据进行预处理和检验。
1) 求解步骤
首先计算参考数列
的级比,级比数列定义为
(10)
在计算时需要所有的
的范围都处于
中,以保证可以使用参考数列
作为处理灰色预测模型GM(1,1)的数据。当
的范围不处于
之中时,取适当的常数c,作平移得到新的参考数列
(11)
,与原参考数列的关系为从而也得到一个新的级比
其定义为
(12)
根据式(10)即可求得在10月、11月和12月的预测值。
2) 数据的检验
通过上述方式预测出的销售量可能存在较大误差,因此需要做检验,从两个角度进行检验,第一个是残差检验,第二是级比偏差值检验。
令残差为
,若残差
,则可认为达到一般要求,若残差
,则可认为达到较高要求。
根据级比数列
,结合发展系数a求出相应的级比偏差
,若残差
,则可认为达到一般要求,若残差
,则可认为达到较高要求。
3.4. 模型结果
通过编写c语言程序进行求解,得到目标小类在2019年10月、11月和12月的销售量的预测值,部分计算结果如表2所示。根据所求数据使用计算得出各个月份的MAPE值如表2所示。
每个月的MAPE值均小于0.17,因此可以认为使用此模型进行预测,其准确度较高,可靠性较强。
4. 引入平衡因子的优化GM(1,1)模型
4.1. 数据准备
在问题二的基础上,继续找到每个类的所有skc,为了更精准的预测skc每月的周销量,需要计算得到每个skc在2019年每个月内每周的周销量,同样使用大数据分析,求解思路如图3所示。
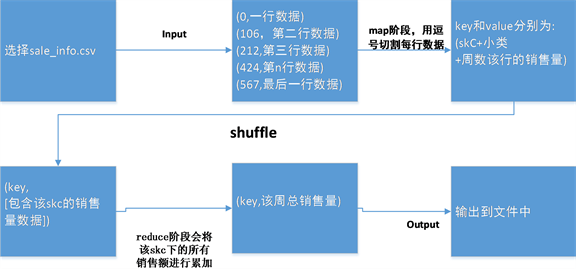
Figure 3. Weekly sales flow chart for solving skc with big data
图3. 大数据求解skc的周销量流程图
根据tiny_class_code的sale_info,用Java的Date类进行Date化,接着对Date对象Calendar化,取出该周是2019年的第几周,先把2019-09-30的数据对应第40周,因此取第四十周为第一周,取30~51周的数据,即前十周和后12周数据。取出该时间段数据后,把key写成skc,tiny_class_code,week,把value写成销售量,写出到reduce,同样对value相加,sum为value,得到相应的value值,即可得出前十周和后十二周的数据。
4.2. 优化后的GM(1,1)模型
根据本问的要求以及计算结果,依次得到累计销售额排名前十的小类对应的skc分别有11417、1676、3777、1475、6125、5906、2362、634、1257、721个,数据量非常大,并且需要预测每周的销售量。为了提高数据的精准性和可靠性,对各类商品的需求进行精准预测,因此可在问题二所建立的模型基础上,引入平滑因子c [4],得到一个新的模型,称之为BGM(1,1)模型。
在问题二的模型中,有参考数列
,对它做1-AGO操作,得到
,为了满足一定的平滑条件,则需要满足以下表达式
(13)
在引入平滑因子c之后,可得
(14)
结合式(15)和式(16),可得
(15)
4.3. 模型的结果
使用问题二的求解步骤,并增加约束条件式(17),编写C语言程序,求解得到以下结果,通过编写c语言程序,求得2019年10月1日后12周的预测MAPE。如表3所示。
总体来看,每周的MAPE维持在一定范围上,但均小于0.25,在周销量信息如此不足的情况下,预测效果总体来看可以认为是可靠的。
5. 结术语
通过Excel、Java语言等工具完成数据的筛选及分析,建立了影响商品销售量及销售额的灰色关联模型,其中最相关因素分别为库存信息、节假日折扣、预计加权销售额,并在此基础上建立了灰色预测GM(1,1)模型以及在引入平滑因子后的优化模型。本模型综合考虑了商品库存、节假日等实际因素,在一定程度上能精准预测商品的销售量及销售额。可作为零售企业对各类商品的需求量的参考。
NOTES
*通讯作者。