1. 引言
语音合成又称为文语转换技术(Text-to-Speech Synthesis, TTS) [1],是一项广泛应用于文本阅读器与人机交互的技术。因而语音合成技术愈发受到研究学者的关注,语音合成的方法从最早的拼接法语音合成 [2] 和统计参数语音合成 [3],到近年来以直接输入文本或注音字符指导语音合成的端到端语音合成系统不断发展,使得合成语音的质量不断提高,几乎接近于人类的语音质量 [4]。但尽管如此,目前合成的语音普遍缺乏情感色彩以及语气信息。在日常对话中,语气(Mood)是表示说话人对某一行为或事物现象的看法和态度 [5]。在不改变句子所陈述内容事实的同时可以给话语信息带来广泛的情感色彩。中英语气大致可以分为陈述句、疑问句、感叹句、祈使句,当然每种语气可以细分到更小的粒度,如疑问句可以分为是非疑问句,特指疑问句等 [5]。而本文主要讨论陈述语气、感叹语气与疑问语气。
为了提高合成语音的自然度,论文 [6] 从情感方面,提出一种迁移学习与自学习情感表征的情感语音合成方法,构建出端到端情感语音合成器,实现个性化语音合成。同时论文 [7] 中采用VAE模型分别用来对噪声、基频、说话能量和音素时长进行学习,实现说话人的语音控制。目前对语音合成的研究大多在情感以及韵律、音调等进行研究,但是合成语音在语气上的表达没有考虑在内。所以本文主要研究目标是在语音合成系统中将语气信息考虑在内,对输入文本,实现特定的语气输出,达到语气控制。
相比论文 [8] 中将VAE引入端到端语音合成,虽然可以达到有效合成带有风格的语音,提高自然度。但是对于端到端语音合成的方法存在需要大量语料库训练、模型复杂度高、合成语音速度缓慢等缺点。所以在本文中,我们主要采用统计参数语音合成方法,其系统主要由文本分析、声学建模、声码器三个模块组成。在声学建模的训练过程,我们加入语气模型的训练并引入变分自编码模型(Variational Autoencoder, VAE) [9] 以无监督学习的方式捕捉声学特征F0的语气信息,更好的模拟说话人个性的整体语言特性。提出了一个称为语气语音合成的系统,包括模型训练与合成两部分(详细介绍见2.2节),尝试在不改变语义信息表达的情况下,实现带有语气的语音合成。最后通过主观与客观的评测方法对语气语音合成的性能进行评估。
2. 模型
在这一部分,我们首先介绍与回顾一下VAE的概念以及模型的相关细节,并且给出关于损失函数的理解。最后对于我们提出的语气语音合成系统进行论述。
2.1. Variational Autoencoder (VAE)
与生成式对抗网络(Generative Adversarial Networks, GAN)一样,VAE是生成模型 [10] 的一种,其主要目标是以无监督学习方式 [11] 对输入高维数据信息的特征进行表征学习 [12],并且最终让生成数据和原始数据分布的分布尽可能接近。VAE是由Kingma等人于2014年提出 [9],如图1为经典的隐变量概率模型示意图。

Figure 1. The graphical representation of VAE: where X is the observed data, N is the number of samples, Z is the latent variable, ∅ is the variable fraction parameter, and θ is the model parameter
图1. VAE的概率图模型表示:其中X为观测数据,N为样本数,Z为隐变量,∅为变分参数,θ为模型参数
橙色线部分表示推断过程,通过编码器(Encoder)实现。是对观测数据X与隐变量Z进行建模,目的是确定关于隐变量Z的后验分布概率分布
:
(1)
但是对于真实的后验概率分布
难以显式计算 [13],而变分推断(Variational Inference) [14] 提供了此类问题的解决方法。通过引入识别模型
去逼近无法确定的后验分布
。对于识别模型与真实后验分布的匹配程度,可以通过Kullback-Leibler (KL)散度 [15] 来衡量优劣。那么,对于概率分布p(x)与q(x)的KL散度定义为:
(2)
对于蓝色线部分表示生成过程,可以通过解码器(Decoder)实现。VAE框架中对于隐变量采用了重参数技巧(Reparameterization Techniques),作为神经网络的编码器根据样本
学习计算出均值
与方差
,所以我们通过从噪声分布采样得到隐变量:
(3)
而生成模型的目标是希望由推断产生的隐变量变分概率分布拟合出观测数据x的近似概率分布
,即:
(4)
所以编码器与解码器的模型结构实现了推断与生成过程,通过联合训练学习,只要优化变分下界ELBO (Evidence lower bound Objective):
(5)
ELBO中第一项是编码器推断近似后验分布的误差称为KL损失,而第二项起着解码器的作用,是对隐变量z进行重构出观测数据x的重构误差。
2.2. 基于VAE的语气语音合成模型
本文为了实现有效表征学习说话人的语气特征,我们将VAE模型引入语气语音合成系统。论文 [16] 提出了一种基于VAE的语音合成基频离散化表征方法,但无法有效进行特定语气的合成。为此,本文进一步提出基于VAE的带有分类器辅助的基频离散化学习方法,进行语气语音合成。如图2所示,该系统分为三个部分。
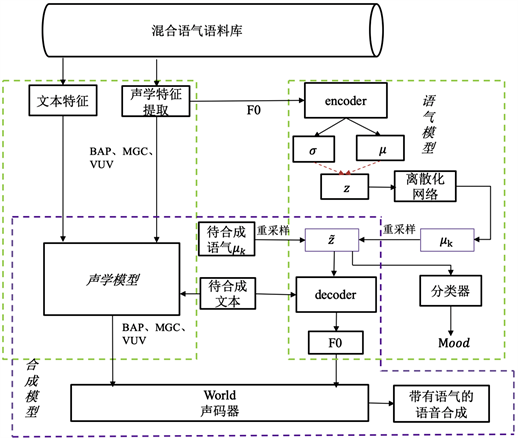
Figure 2. VAE-based speech synthesis framework with mood
图2. 基于VAE的语气语音合成框架
本模型包括模型训练和目标语音的合成两个阶段。其一在模型训练部分,如图2绿色框图部分所示,包括声学模型的训练和语气模型的训练。声学模型是以待合成文本特征作为输入,输出是合成语音所必须的声学特征,如谱参数MGC (Mel-Generalized Cepstral)、BAP (Band Aperiodicity, BAP)、VUV (Voice, Un Voice)及基频参数F0 (Fundamental Frequency)等 [17]。而声学模型的训练,是以语料库提取的声学特征 [16] 作为训练目标,对声学参数分布进行建模。声学模型算法从传统的基于HMM到基于神经网络的声学模型,发展为近年来的基于端到端的声学模型,使得统计参数语音合成逐渐发展,而本文主要采取神经网络声学模型 [18]。通常声学特征F0反映出说话人的音调高低,其曲线的包络在语气控制中起着尤为重要的作用,所以提出的语气模型是以F0对语气进行建模,达到合成语音带有语气控制。
语气模型中使用了典型的编–解码结构,编码器(Encoder)可以学习输入输入数据的潜在特征,把数据压缩至潜在空间表示,而解码器(Decoder)则根据学习到的低维特征,从潜在空间中重构出原始数据。将提取到的声学特征F0作为编码器的输入,通过编码器学习并计算出隐变量z的均值
和方差
。对于k个不同种类的语气,预期学习到k个不同组合的均值与方差,即k个高斯分布代表不同语气。如前所述,根据重参数技巧,可以从噪声分布中进行采样得到表征语气的隐变量,得到的Z的分布应该近似逼近混合高斯模型,计算两者KL散度为:
(6)
我们通过训练离散化的神经网络得到表征不同语气的均值
,最终利用重采样技巧得到隐变量
。将隐变量 经过解码器重构得到声学特征F0,即所谓的生成模型。与此同时为了提高模型学习到语气信息的准确度,我们将采样得到的隐变量
作为已经训练好的分类器输入,计算其输出目标语气的概率:
(7)
其中n为语气标签类别个数,因此整个语气模型的损失函数为:
(8)
损失函数中的第一项为编码器推断近似后验分布的误差,第二项是通过隐变量z、文本t以及语气m重构出观测数据的误差,当然
为分类器的损失函数,
为隐变量z与高斯混合模型的KL散度。
其二紫色框图为语音合成部分,将待合成文本输入到训练好的声学模型生成合成所需要的声学特征,同时待合成文本与语气模型中重采样得到表征语气信息的隐变量
一同输入到解码器重构F0。最后利用声码器,例如WORLD [19],实现从声学特征中重构出语音波形,产生带有语气的语音合成。
3. 实验与结果分析
3.1. 数据库
基于语气语音合成系统训练的语料库要求语音数据在语气种类上尽量丰富,有着丰富情感色彩,并存在与语音数据相对应的文本。我们采取Usborne公司出版发行的语料库Blizzard Challenge 2018 [20],该语音共包含6.5小时,约7250个句子的专业录音。演讲者的名字叫Lesley Sims,她是一位以英语为母语的女性,通过以故事表达的方式讲述给4~6岁的观众。这种带有丰富变化语气的语音更加有利于VAE在其潜在空间中捕捉到更多的语气变化,学习各种语气种类的特征。考虑到语气系统的复杂性,加之时间有限,故而本文主要考虑对陈述语气、疑问语气以及感叹语气在语音合成中实现语气语音合成。为了有效地生成隐变量混合高斯模型,提高模型学习语气的确率,模型中引入了分类器进行语气判断。因此,数据预处理阶段,我们需要对语音文本自动进行标签,区分出语气种类即陈述语气、感叹语气以及疑问语气。如表1为所举样例文本:
3.2. 实验评估
实验在Ubuntu18.04系统下,基于PyTorch平台实现对模型的训练。对于提出的语气模型具有自动编码器结构,通过对F0特征进行有效信息编码学习和重建出目标语气F0。MLPG [21] 使用全局标准差来生成F0轮廓,最后使用WORLD声码器从声学特征中恢复语音波形。
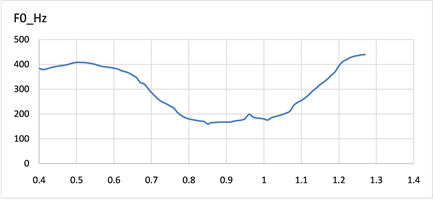
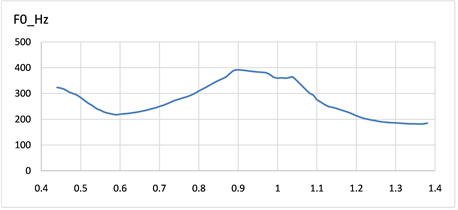
我们从语料库中选取了三种不同语气的F0轮廓图,如图3~5可以看出不同种语气的F0轮廓图呈现出不同的趋势。图3中图3(a),图3(b)分别对应表1中S1与S2,疑问语气句尾呈现语调上升趋势,侧重表达疑问的内容。对于图4中图4(a),图4(b)分别对应表1中S3与S4,除去异常时间数据下F0值,陈述句往往表现出语气舒缓,平稳的特征。图5所示图5(a),图5(b)分别对应表1中S5与S6,感叹语气F0轮廓与陈述语气大有不同,表现出起起伏伏,感情色彩强烈。
 (a)
(a)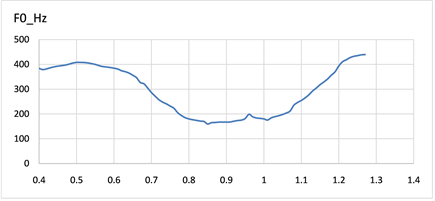 (b)
(b)
Figure 3. F0 contour diagram of the interrogative mood
图3. 疑问语气F0轮廓图
 (a)
(a) (b)
(b)
Figure 4. F0 contour diagram of the indicative mood
图4. 陈述语气F0轮廓图
 (a)
(a) (b)
(b)
Figure 5. F0 contour diagram of the exclamatory mood
图5. 感叹语气F0轮廓图
本文从主观与客观两个方面对语气语音合成性能做出评估。如图6所示为待合成文本在提出的系统下合成的目标语音的声学特征F0曲线即合成语音的客观评价。其中,易知语句1为陈述句:“This is an Usborne audio production.”;语句2为疑问句:“Is this part of the show?”;语句3为感叹句:“Oh dear!”。可以看出不同的语气具有明显不同的基频特性,反映了说话者语调的变化。并且其基频轮廓特性和图3至图5相应的语气呈现一致的轮廓。实验结果表明,提出的语气语音合成系统可以合成带有语气的语音,并且在不同语气上有较好的区分度。
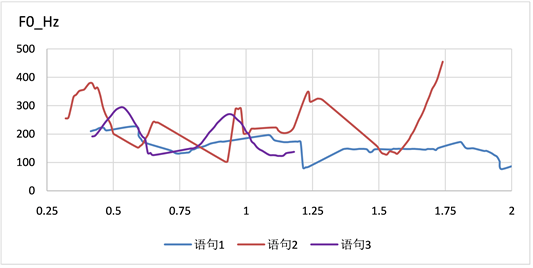
Figure 6. F0 contours for different mood
图6. 合成不同语气的F0图
最后,我们同时也采用了主观意见评分(Mean Opinion Score, MOS)对本语气语音合成系统进行进一步的性能评估。MOS是语音合成领域测评中主流使用的评分方法之一,且因为语音合成的目的与MOS方法都是基于评测人的主观感受,所以具有说服性。我们随机选取15句进行语音合成实验,4位评测人进行主观打分(分值为1~5,保留一位小数),最后计算加权平均数。如图7所示,4位评价者对合成的语音MOS打分较为接近,评价较为一致。表明合成的语音带有明显语气节奏,可懂度高。
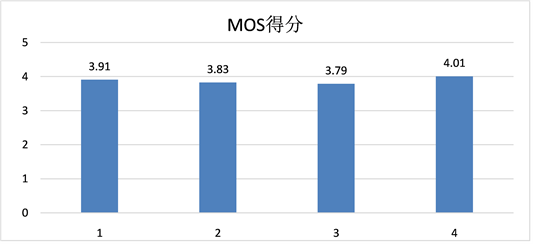
Figure 7. Subjective evaluation of results
图7. 主观评测结果
4. 总结
在本篇文章中,我提出一个语气语音合成系统模型,主要包括语气模型、声学模型、合成模块。我们主要对于表征语气信息F0进行建模,希望解决当前语音合成系统在语气输出上的短板。我们通过VAE网络学习句子潜在的语气信息,通过离散化神经网络与分类器提高模型学习的准确率。最后通过实验表明,对于待合成的文本输入,借助WORLD声码器重构语音波形,可以输出预期目标语气的合成语音,更具表现力。整个系统可以达到很好的性能。未来的下一步工作会增加研究语气的种类与中英文语气语音合成的实现。