1. 引言
近年来,随着移动定位技术的普及,许多在线社交网络应用引入了位置服务,将虚拟社交网络与真实地理位置连接起来,用户可以对自己访问的兴趣点进行打卡或签到(check-in),使得位置社交网络(Location-based social network, LBSN)迅速发展 [1],如Yelp、滴滴、美团等。与此同时,兴趣点的数量爆发式增长,如影院、酒店、餐厅等,大量的信息涌入用户视野,用户无法做出快速有效的选择。而兴趣点推荐应用的诞生,服务于用户的个性化需求,可以帮助用户快速选择感兴趣的位置,减少用户的决策时间,受到学者的重视。
现实中人类运动呈现序列模式的特点:在时间上,用户访问的兴趣点存在先后顺序;在空间上,用户访问的兴趣点存在远近关系。而当前兴趣点推荐研究大多忽视了用户签到数据的序列性和连续性。因此出现了通用兴趣点推荐的一个延伸问题——连续兴趣点推荐(successive POI recommendation) [2],基于时间连续性特征的时空序列模式用于兴趣点推荐,其主要目的是在给定时间下,通过挖掘用户的历史签到记录以及其他类型的相关信息,预测用户下一个可能访问的地点。
连续兴趣点推荐对用户和兴趣点商家都有非常重要的应用价值。一方面,对于用户而言,连续兴趣点推荐是为用户推荐下一个可能感兴趣的兴趣点,时效性强,使得信息超载问题得到有效解决。另一方面,对于商家而言,连续兴趣点推荐可以帮助商家发现潜在的用户,为商家推广兴趣点或者服务,使服务更精确地呈现在用户眼前,有助于商家及时调整经营策略从而提高收入。
基于位置的社交网络是一种包含用户与用户之间关系、用户与兴趣点之间关系、兴趣点与兴趣点之间关系的复杂异构网络,与传统推荐任务相比,连续兴趣点推荐存在一些新的问题。
1) 数据稀疏性。基于位置社交网络的签到数据是一种独特的时空数据,在一定的时空区域内,由于单个签到记录的有限性和兴趣点数量的海量性,用户的签到数据远比传统推荐系统的数据(如书籍评分数据)稀疏。
2) 基于位置社交网络的兴趣点推荐中,在进行社交信息建模时,大多只关注用户显性社交信息,即真实的朋友关系,而忽视了用户隐性社交信息,即非朋友关系,但却共同签到了许多相同的兴趣点。现实中,用户之间显性社交信息是十分稀疏的,大多数社交信息都属于隐性社交信息,同时用户的显性社交信息中可能包含一些噪声,并不能很好的展示出推荐系统的性能。因此,在进行连续兴趣点推荐中,需要研究如何充分利用用户的显性和隐性社交关系,进而对用户社交信息进行更好的拟合,提高连续兴趣点推荐的精度。
基于以上问题,本文提出了一种融合隐性和显性社交信息的连续兴趣点推荐模型。本文贡献总结如下:
1) 利用非负矩阵分解技术,通过引入显性因子
,将包含用户隐性和显性的社交关系图转化为低维稠密向量,缓解数据稀疏性问题。
2) 将LSTM结构进行改进,构建了融合隐性和显性社交信息的连续兴趣点推荐模型——SLSTM。遗忘门、更新门和输出门的值不仅仅根据当前时刻的兴趣点和上一时刻的隐藏状态决定,还由加入当前时刻的上下文信息同时决定。通过共享非负矩阵分解模型训练的图顶点向量,实现了图结构数据和签到序列数据的有效融合。
3) 使用真实的LBSN签到数据集:Gowalla和BrightKite,进行实验评估SLSTM的推荐性能,实验结果表明SLSTM优于其他先进的连续兴趣点推荐模型。
2. 连续兴趣点推荐问题研究现状
2.1. 连续兴趣点推荐
连续兴趣点推荐要建模用户的签到序列数据,为用户推荐下一个可能感兴趣的地点。Chen Cheng [3] 是提出连续兴趣点推荐问题的第一人,使用马尔科夫链模型对用户的访问序列建模。Jing He等人 [4] 将马尔科夫链模型与矩阵分解技术结合起来,利用三阶向量和马尔科夫链建模用户签到位置的序列影响。然而上述方法存在一定缺陷,即只考虑用户邻近访问的兴趣点信息,所包含的信息量太少。现实中,不仅依赖于最近的访问地点,还受到历史签到点的影响。Liu等人 [5] 提出了一种基于多阶马尔可夫模型的连续兴趣点推荐算法,该算法基于当前位置和先前位置预测用户下一个最喜欢的兴趣点,并将用户签到的兴趣点的地理影响和时间流行度结合到算法中。
还有学者利用张量分解解决了连续兴趣点推荐问题。Zheng等人 [6] 利用张量分解模型,对用户的历史签到信息建模,构造用户–位置–评分张量,以优化兴趣点推荐的结果。Zhao等人 [7] 等人提出了时空潜在排序模型(STELLAR),该模型基于张量分解框架,对连续兴趣点进行建模,捕捉并利用了签到兴趣点的时空影响,但是STELLAR模型只关注了一组连续的兴趣点对,未能对用户整体的签到序列建模。
近年来,循环神经网络在序列建模中取得了巨大的成功,因此大多数学者将其用于连续兴趣点推荐。Qiang Liu等人 [8] 提出了时空循环网络(ST-RNN),基于时间矩阵和空间矩阵在网络的每一层对局部时间和空间建模。但是循环神经网络存在梯度消失问题,为了缓解此问题,Zhao等人 [9] 提出了一个基于LSTM变体的模型——ST-LSTM,该模型将时间门和距离门引入LSTM单元中,用以捕捉连续签到点的时空信息。Li等人 [10] 提出了一个神经网络模型——TMCA,基于LSTM单元的编码–解码(Encoder-Decoder) [11] 框架,去自适应的学习深度时空表示,并用嵌入技术以一个统一的方法融合上下文信息用于连续兴趣点推荐。
2.2. 基于社交信息的兴趣点推荐
LBSN中的社交信息富含用户的相似行为偏好,可以缓解数据稀疏问题,因此许多学者利用社交信息提高兴趣点推荐的精度 [12] [13]。有些学者基于用户与好友的影响,计算用户之间的相似度,利用协同过滤方法进行兴趣点推荐 [14] [15] [16]。还有研究人员将社交信息作为基于矩阵分解或张量分解的正则项或者权重。李鑫等人 [17] 提出了一种基于相同兴趣圈的推荐系统——CSCR,模型同时采用了朋友和专家2种社会关系作为矩阵分解的两个正则化约束项。Gao等人 [18] 着重关注了签到数据中的隐性社交影响进行分析,提出基于高斯径向基核函数的支持向量回归(SVR)模型,预测用户之间的显性信任值,设计一种新的基于信任的推荐模型,同时将显性和隐性社会信任信息纳入其中。温彦等人 [19] 基于地理位置中的用户偏好和用户社交关系偏好,提出了一种推荐模型MFDR,基于矩阵分解求解用户关系矩阵,将社交关系的兴趣偏好进行细化。上述研究工作均是将社交关系作为基于矩阵分解或者张量分解潜在因子模型的正则项或者权重,这种方法仅仅将社交关系作为辅助信息进行兴趣点推荐,没有将这种社交信息真正融入推荐模型中。
3. 研究思路与框架
3.1. 连续兴趣点推荐问题描述
为了更好地描述本文所提出的连续兴趣点推荐算法,本节定义了相关概念和关键数据结构,正式给出连续兴趣点推荐问题的规范定义。
令
为用户的集合,M代表用户的数量。
为兴趣点的集合,N代表兴趣点的数量,其中每个兴趣点主要有两个属性:兴趣点ID和兴趣点的经纬度坐标。
定义1 签到记录:用户在LBSN中的签到记录r由一个三元组
表示,表示用户u在t时刻访问了兴趣点y。
定义2 用户u的历史签到序列:每个用户所有签到记录的集合
,其中
表示用户u在T时刻的签到记录。
定义3 签到时间:本文主要考虑两种时间信息,一种是将一天划分为24小时,另一种是将一周划分为工作日和非工作日,0代表工作日,1代表非工作日,用符号
表示。
定义4 社交关系矩阵:为了将隐性社交信息和显性社交信息同时考虑在内,本文定义了一个社交关系矩阵
,M表示用户的数量。具体表示如3.1节式(1)所示。
本文的关键符号及其含义如表1所示:

Table 1. Key symbols and definitions
表1. 关键符号及定义
3.2. 基于非负矩阵分解的社交信息模型
对于位置社交网络的用户社交信息,如图1所示,一方面,受朋友之间显性社交关系的影响,人们经常会访问他们朋友推荐的兴趣点,用户朋友签到的兴趣点会影响用户的签到行为。另一方面,位置信息作为一个新的维度嵌入到社交网络中形成新的社交网络,社会联系将会扩大。例如,两个互不认识的用户访问了同一个地方,说明他们处于同一地理位置,而且二者签到相同的兴趣点数越多,二者行为偏好越相似,那么他们很可能被联系起来,这种社交关系被称为隐性社交关系。因此通过引入显性社交关系,可以提高那些签到数很少,但有丰富社交关系用户的推荐质量,同时缓解了推荐中的冷启动问题;通过引入隐性社交关系,可以提高那些签到数较少,同时社交关系匮乏用户的推荐质量。基于此,本文利用非负矩阵分解技术,将包含用户隐性和显性的社交关系图转化为低维稠密向量,以用于连续兴趣点推荐模型中。
1) 构建融合隐性和显性社交信息的特征矩阵
为构造社交信息特征矩阵,本文首先初始化一个社交矩阵
,M为数据集中用户的数量,并将矩阵的初始值设置为0。矩阵元素
计算方法如式(1)所示,其中矩阵的对角元素为
,表示用户i访问的兴趣点个数;矩阵其余元素
分两种情况进行统计,当用户i与用户j为陌生人,即不存在显性社交关系时,
,
表示用户i与j访问的相同兴趣点的个数;当用户i与用户j存在显性社交关系时,
,其中
为正整数,表示显性关系影响因子。到此,构造出了同时包含隐性和显性社交信息的矩阵。
(1)
2) 非负矩阵分解
在上一小节中,本文将用户的社交网络图转化为特征矩阵的形式,由于数据集中用户数量多,构造的特征矩阵极为稀疏,所以这样的特征矩阵还不能直接用在连续兴趣点推荐模型中,需要对数据进行降维。观察到社交特征矩阵为非负矩阵,本文采用非负矩阵分解技术 [20],来学习社交特征矩阵的特征表示。
本文采用非负矩阵分解的思路是将社交信息的特征矩阵
分解成一个基矩阵
和一个系数矩阵
,如式(2)所示,其中
。其实质是将社交信息特征矩阵映射到一个低秩的特征向量空间,学习用户特征信息在该特征空间下的向量表达。分解后得到的低秩矩阵
称为原始特征矩阵的基矩阵,基矩阵中的每一行都对应一个用户的社交信息,称为用户在该特征空间下的隐向量。由于
,就可以实现对原始矩阵的降维处理。
(2)
非负矩阵分解只能去求原始特征的近似解,本文使用基于欧式距离的弗罗贝尼乌斯范数代价函数,如式(3)所示,去度量近似矩阵
和原始矩阵F之间的相似度。
(3)
其中,
是对社交信息特征矩阵分解后得到的基矩阵,
是系数矩阵,
是
中隐向量的维度,
表示矩阵的罗贝尼乌斯范数,
是
范数,
为正则化参数,
为
正则化占总正则化项的比例。基矩阵
和系数矩阵
,通过随机梯度下降进行求解。
该非负矩阵分解可以看作对社交信息中的特征进行聚类,从而挖掘所有用户在隐性和显性社交信息中的特征,并学习在该特征空间下的最佳向量表示。给定指定的用户u,完成分解后,该用户u在基矩阵
中对应的行向量即为其隐向量,符号表示为
。
3.3. 基于LSTM的连续兴趣点推荐模型
近年来,循环神经网络(Recurrent Neural Network, RNN)在时序分析问题上取得了很大的成功 [21]。本文研究的连续兴趣点推荐问题,基于的位置社交网络数据是人类的移动行为轨迹,即用户在某个时刻访问了某个兴趣点,具有很强的时间序列性和空间序列性,因此本文考虑用循环神经网络进行连续兴趣点推荐,其网络结构对兴趣点签到序列进行建模可以有效提取到序列特征。但是用户的签到序列会很长,传统的RNN结构会出现梯度消失,无法处理长期依赖问题。长短时记忆单元(Long Short-Term Memory, LSTM) [22] 是为解决RNN梯度消失问题提出的。本文通过拓展一般的LSTM模型结构,将社交信息融入到LSTM的门控结构中,提出了一种融合隐性和显性社交信息的连续兴趣点推荐模型(Long Short-Term Memory with Social Information, SLSTM)。
1) 改进的LSTM模型
融合隐性和显性社交信息的连续兴趣点推荐模型SLSTM的基本架构如图2所示。在SLSTM模型中,其遗忘门、更新门和输出门的值不仅仅根据当前时刻的兴趣点和上一时刻的隐藏状态决定,还由加入当前时刻的上下文信息,主要包括社交信息、地理信息和时间信息来同时决定。本文用
表示第t个时间步的上下文信息。具体地,
,其中
是本文第3.2节基于非负矩阵分解得到的社交关系特征的隐向量。
是用户在t时刻签到时间的形式化表示,主要是签到时间的小时数以及工作日和非工作日的表示。
表示本次签到与上一次签到的时间差和距离差,其中,签到序列的第一个时间步,时间差和距离差均用0表示。该模型将这4个特征进行向量拼接,输入到LSTM中,利用神经网络去学习这些输入特征的高阶和非线性的交互,这样就实现了社交信息、时空序列信息等异质信息的有效融合。

Figure 2. The basic frame work of SLSTM
图2. SLSTM的基本框架
SLSTM模型的遗忘门
,更新门
和输出门
计算过程如式(4)-(6)所示:
(4)
(5)
(6)
其中,
表示上一时刻的隐藏状态,
表示当前时刻的上下文向量,
表示当前时刻兴趣点的向量表示。如图3所示,遗忘门、更新门和输出门的值不再仅仅根据当前时刻的输入
和上一时刻的隐藏状态
决定,还加入当前时刻的上下文信息
。遗忘门
输出向量的取值范围为
,决定让网络忘记之前多少用户签到的信息;更新门
决定在细胞状态中,存放多少新的用户信息;输出门
决定记忆细胞
输出的内容。
是遗忘门、更新门和输出门的权重矩阵,
是对应的偏倚项。激活函数是sigmoid函数,取值范围为
,计算公式如式(7)所示:
(7)
SLSTM计算t时刻的候选记忆细胞
和记忆细胞
,计算过程如式(8)和(9)所示:
(8)
(9)
其中,
表示第t个时间步候选记忆细胞,是由当前时刻的输入
,上一时刻的隐藏状态
和当前时刻的上下文信息
共同决定。
表示第t个时间步记忆细胞,用以保存网络的长期记忆,它是LSTM的关键部分,它由两部分构成,前半部分是由遗忘门
和第
个时间步的记忆单元
组成,后半部分是由更新门
和候选记忆单元
构成。
的激活函数为tanh函数,取值范围为
,计算公式如式(10)所示:
(10)
SLSTM使用第t个时间步记忆细胞
和输出门
组合,得到当前时刻的隐藏状态
,计算过程如式(11)所示:
(11)
其中,
是隐藏单元,由输出门
和记忆细胞
共同决定,用以保存网络的短期记忆。
表示矩阵逐元素对应相乘。
经过
个时间步LSTM单元的前向传播后,模型输出第
个时间步的隐藏单元
,如图1所示,将
放入全连接层进行训练,输出与第T个时间步访问的兴趣点相关的向量
。为了得到用户在第T个时间步对每个兴趣点访问的概率,本文将连续兴趣点推荐看作一个多分类问题,在模型最后引入Softmax层,计算公式如式(12)和(13)所示,用以获取每个兴趣点的访问概率。
(12)
(13)
为了减少运行内存和计算时间,同时考虑到地理的邻近性,本文令
,而不是令Q为所有兴趣点的数量,即选取与第
个时间步在空间上邻近的前100个兴趣点作为候选兴趣点,进行兴趣点推荐。
表示用户在第T个时间步中,选取的100个兴趣点,每个兴趣点访问的概率向量。本文选取前k个概率最大的兴趣点,作为用户topk的推荐列表。
总的来说,SLSTM模型融合了兴趣点签到序列中的隐性和显性社交信息、时间信息,打破了序列推荐中较短序列带有的信息量有限的局限,从而能够在LSTM结构基础上更好地对兴趣点签到序列中隐含的用户偏好进行挖掘。
2) SLSTM模型训练
SLSTM模型的参数为
,其中
是遗忘门
,更新门
,输出门
和候选记忆细胞
的权重矩阵,
表示对应的偏倚项,模型训练的目标是优化以上所有参数,使得所有兴趣点签到序列里的每一次兴趣点的签到都能被预测到,这个目标体现在本文采用的Softmax损失函数中,如式(14)所示:
(14)
其中
为one-hot编码,表示用户在第T个时间步真实访问的兴趣点,P表示训练样本的数量。为了达到上述目标,本文在模型训练阶段使用深度学习中经典的Adam优化算法 [23] 对模型参数进行更新。SLSTM模型具体的训练过程如算法1所示:
4. 实验
4.1. 实验内容和数据集
本文设置三组实验以验证模型的有效性,并与主流连续兴趣点推荐模型进行比较。具体包括:SLSTM模型与主流连续兴趣点推荐模型的推荐性能进行比较;显性社交因子对连续兴趣点推荐结果的影响;序列长度对推荐结果的影响。
本文使用公开数据集Gowalla和BrightKite来评估本文推荐算法的性能。首先对原始数据进行预处理,删除访问少于20个兴趣点的用户,删除访问少于20次的兴趣点 [24]。此外,为了确保序列长度,要求每个用户的签到次数不低于20,本文实验数据集的统计情况如表2所示。在本文实验中,遵循前人的研究 [10],分别选取每个用户历史签到序列的70%,20%,10%作为实验的训练集、测试集和验证集。
4.2. 评价指标
由于要预测用户下一个要访问的兴趣点,所以本文采用连续兴趣点推荐算法中最常见的评价指标召回率
[9] [25] 来衡量连续兴趣点推荐任务中相关算法的性能。
表示预测出Topk个用户可能访问的兴趣点,其中预测对的兴趣点数占所有要预测的兴趣点数的比例,k表示推荐列表的长度。具体定义如式(15)所示:
(15)
其中,
表示给用户推荐的k个兴趣点的集合,
表示用户在测试集中访问的下一个兴趣点的集合。
计算了推荐列表中准确推荐在用户测试集的所有兴趣点的占比,该比例越大,表明推荐算法的推荐结果越精确。
4.3. 对比算法介绍
为了证明本文所提出模型的有效性,本文与以下几个主流连续兴趣点推荐方法进行比较。
1) FPMC:个性化马尔科夫链模型 [26],应用矩阵分解方法将个性化的马尔科夫链映射到高维空间,对用户的签到行为进行建模。
2) BPR:贝叶斯个性化排序 [27],利用用户对兴趣点喜好的排序关系,并不断优化这种排序关系来学习用户以及兴趣点的隐向量,从而实现个性化推荐。
3) ST-RNN:时空循环神经网络 [8],同时考虑时间和空间因素,挖掘用户的兴趣偏好。
4) SERM:融合上下文信息的循环神经网络 [28],同时考虑地理、时空、用户特征,利用循环神经网络挖掘用户签到的序列信息。
4.4. 参数设置
为了进行公平的比较,在本文实验中,参考相关文献设定每种方法的优化参数,从而保证每种方法都可以实现最佳性能。对于本文模型SLSTM,设置批量为256,优化器选择Adam,学习率设定为0.001。对于本文中的非负矩阵分解模型,Gowalla数据集和BrightKite显性社交关系的影响因子
均设置为1;包含用户社交信息的潜在向量维度d设置为60;签到序列的长度设置为10。
4.5. 实验结果
1) 性能对比
由于兴趣点的海量性以及用户签到数据的稀疏性,基于位置社交网络的连续兴趣点推荐准确率普遍偏低,所以在本文实验中,实验评价指标召回率的数据是普遍偏低的。随着推荐的兴趣点个数的增加,召回率会不断上升 [29]。由于在实际应用中,用户往往更关注推荐列表中排名比较靠前的兴趣点,所以我们遵循前人的研究做法 [30],只展现推荐兴趣点个数k = 2,5,10和20的比较结果。由表3所示,无论在Gowalla还是BrightKite数据集中,本文提出的模型SLSTM在推荐效果上优于他对比模型。例如在top-10上,Gowalla数据集上,我们模型与目前先进的SERM模型相比,在召回率上提高17.0%;BrightKite数据集上,我们模型与目前先进的SERM模型相比,在召回率上提高15.2%,说明SLSTM模型在基于位置社交网络的连续兴趣点推荐中的有效性。
Table 3. Performance comparison of methods based on Gowalla and BrightKite datasets
表3. 基于Gowalla与BrightKite数据集的各方法性能对比
具体地,由图4所示的比较结果中,我们可以发现以下几点:
1) FPMC在Gowalla和BrightKite两个数据集上性能最差,因为FPMC基于马尔科夫模型只考虑用户邻近访问的兴趣点信息,而忽视用户周期性签到行为。
2) BPR的性能略高于FPMC,但效果表现也不佳,因为BPR仍然依赖于简单的矩阵分解,即分解了用户–兴趣点的访问矩阵学习用户行为偏好,没有利用位置社交网络中用户签到的地理信息;另外,BPR将所有未知因素视为负面反馈,会降低推荐精度。
3) ST-RNN与SERM均利用循环神经网络进行建模,由图4可知,这两种方法的性能均优于FPMC和BPR,体现了循环神经网络在解决序列问题上的优越性。
4) ST-RNN同时考虑了时间和空间因素,利用位置社交网络中用户的地理信息对用户的行为偏好建模,表明了连续兴趣点推荐任务中建模签到行为的地理因素的重要性,而用户的地理空间关系是连续兴趣点推荐任务和传统推荐任务的本质区别。
5) SERM同时考虑了多种外部因素:地理,时间和用户特征,因此性能优于ST-RNN,但二者基于基本的循环神经网络进行连续兴趣点推荐,存在梯度消失问题;SERM模型平等的处理了地理、时间和用户特征对用户行为偏好的影响,并不能有效建模不同特征之间的联系,因此推荐效果不如本文模型。
6) 本文模型SLSTM在所有的参考模型中表现最优,表明了SLSTM在连续兴趣点推荐中的有效性。相比于其他模型,SLSTM在循环神经网络中使用了LSTM单元,解决了梯度消失的问题;并基于非负矩阵分解的特征表示法得包含隐性和显性社交信息的特征表示,并利用SLSTM有效建模了这些特征对最终推荐结果的深层次联合作用,从而取得了令人满意的推荐效果。
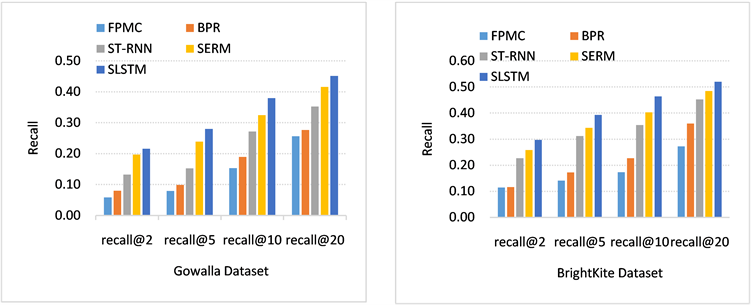
Figure 4. Comparison results of Recall@k indicators of each model in Gowalla and BrightKite datasets
图4. Gowalla与BrightKite数据集各模型Recall@k指标对比结果
2) 参数影响
调整模型参数,发现非负矩阵分解模型中显性社交关系的影响因子
和推荐模型中签到序列的长度
对SLSTM模型的性能是重要的。因此,这一部分本文研究模型参数
和
的对推荐效果的影响。
由图5可知,本文在Gowalla和BrightKite两个数据集对显性因子
进行参数分析,
的取值为
。在两个数据集中,随着
越来越大,Recall@10的值越来越来小,因此在两个数据集中本文均选择显性因子
进行社交信息建模,这样可以更好的还原用户的显性和隐性社交关系。由此证明隐性社交关系对用户行为偏好影响要大于显性社交关系,很可能是由于用户之间显性社交信息是十分稀疏,大多数社交信息都属于隐性社交信息,同时用户的显性社交信息中可能包含一些噪声,并不能很好的展示出推荐系统的性能。

Figure 5. Results of Recall@10 in different implicit social factors
图5. 显性因子不同时,Recall@10的结果
由图6可知,本文实验探究了签到序列长度l从8到13的变化对推荐性能的影响。Recall@10的值随着签到序列长度l的增加先增加,是因为随着签到序列的增加,模型可以更精准的模拟出用户的长期偏好。当
时,推荐精度达到最高,随着继续增加,模型的复杂度随之增加,对于提高模型性能就不明显了。

Figure 6. Results of Recall@10 in different length of checkin sequence
图6. 签到长度不同时,Recall@10的结果
5. 结语
针对连续兴趣点推荐问题,本文提出一种融合隐性和显性社交信息的连续兴趣点推荐模型——SLSTM。该模型利用非负矩阵分解技术,对用户的社交信息进行建模,同时考虑了用户的显性社交关系和隐性社交关系,将社交网络图转化为低维特征向量;并通过改进LSTM结构,提出了融合社交关系的连续兴趣点推荐模型SLSTM,将非负矩阵分解训练的社交向量和用户的序列信息进行融合,用于连续兴趣点推荐。本文在真实LBSN签到数据集Gowalla和BrightKite上进行实验,结果表明在Gowalla数据集上,SLSTM模型在Recall@10指标的性能较SERM模型提高了17%,在BrightKite数据集上,Recall@10指标提高了15.2%,说明SLSTM模型在连续兴趣点推荐中的有效性。在未来工作中我们将结合评论文本信息或者地理信息,进一步提高连续兴趣点推荐的性能。
基金项目
本文系上海市自然科学基金项目“基于自适应的多阶段差分进化计算研究”(项目编号:15ZR1401600)的研究成果之一。
NOTES
*通讯作者。