1. 引言
在教室课堂场景下的学生学习状态检测是指在课堂图片中检测出头部状态的过程,状态分为抬头与低头。学生作为受教育的主体,从学生课堂学习状态的研究出发,可作为学生课堂学习效率的评价指标之一。目前教师普遍通过课堂观察以及提问等方式来实时了解学生的课堂学习情况,这会造成课堂信息传递与反馈的滞后性和片面性 [1]。并且,随着智能手机等电子设备的普及,目前的课堂教学过程中,出现了大批“低头族”。因此,通过统计“抬头率”可以在一定程度上判断学生的课堂专注度,从而有助于有效地提升课堂教学效率 [2]。学生的课堂学习状态与课堂学习效率息息相关。目前课堂场景中对于学生课堂学习状态的研究主要从课堂学习行为 [3]、课堂疲劳状态 [4]、课堂人脸检测及关注度研究方面 [1] 展开。
在计算机视觉和模式识别中,近几年深度学习网络得到了广泛的应用,比如,2012年,以AlexNet [5] 为代表的卷积神经网络(CNN)方法被广泛应用在目标检测领域,精度取得了显著提升。2014年,GoogLeNet [6] 的面世,在保持预算不变的情况下增加网络的深度与宽度,从而实现大规模图片的目标检测。2015年,ResNet [7] 深度残差网络的提出,解决了深度网络过深而浪费现有资源的问题,Fast R-CNN [8] 是一种快速基于区域的卷积网络方法,在提高训练和测试速度的同时,提高了检测精度。2016年,ResNeXt [9] 通过重复一个构建块来构建,聚合了一组具有相同拓扑结构的转换,在保持复杂的限制条件下,增加基数也能很好地提高分类精度。而SSD [10] 及YOLO [11] 的提出,让目标检测算法从两个阶段向一个阶段(端到端)迈进。2017年,YOLOV2 [12] 不仅提高了检测速度,而且检测类别高达9000种,在数据集PASCAL VOC和COCO上,是最先进的多尺度训练方法。2018年,YOLOV3 [13] 的提出,不仅简化了网络模型,更是对小目标检测起到了领航的作用。
深度学习虽然应用广泛且效果较好,但是对于不同的研究对象有不同的研究方法,本文针对于教室课堂场景,研究学生学习状态,以头部为目标,把头部状态分为抬头和低头,我们借鉴了tinyyolov3与dropblock的结合 [14],把yolov3与dropblock相结合,实验证明它对于网络卷积层是特别有效的正则化方法。
2. 基本原理
2.1. Yolov3
yolov3 [13] 提出了一个阶段克服了两种操作缓慢的缺点阶段检测算法。它是一种卷积神经实现端到端的目标检测和识别。它只使用一个CNN网络直接预测不同目标的类别和位置节省了大量的时间来检测对象。在这项工作中,我们选择yolov3模型提取头部特性。yolo算法的基本思想是:首先通过特征提取网络对输入特征提取特征,得到特定大小的特征图输出。输入图像为460 × 460,会分成13 × 13、26 × 26、52 × 52的网格,接着如果真实框中某个物体的中心坐标落在某个网格中,那么就由该网格来预测该物体。每个物体有固定数量的边界框,Yolov3中有三个边界框,使用逻辑回归确定用来预测的回归框。图2是dropblock与yolov3的网络结构。
2.2. Dropblock
过拟合在计算机视觉领域普遍存在,模型在已有的训练集上表现比较好,而在新的未知数据集上表现较差。对于这一现象,在深度神经网络中首次提出了dropout [15] 算法。dropout一般放在全连接层后。在卷积层中添加dropout没有明显的效果。由于卷积层可以通过drop掉的神经元附近学习到相似的信息,因此为了在卷积层中防止过拟合现象,出现了dropblock [16] 模块。dropblock [16] 是一种用于卷积层的正则化方法。这两种算法的主要区别在于dropout随机灭活全连接层的神经元,而dropblock [16] 随机灭活卷积层的单元。在实验中,我们在yolov3模型中加入了dropblock [16] 模块,从而获得更好的模型。
dropblock层以块的形式丢弃特征单元,减少网络对某一特征的依赖。block_size和
是dropblock的两个重要参数。block_size表示要丢弃的块的大小,而
控制的是要删除活动单元格的数量。block_size的大小对于所有的特征图都是一样的,不管特征图的分辨率如何。实际上,
没有确定的值,但可以按如下方式进行计算
(1)
其中,kepp_prob可以理解为灭活中的单元格被保留的概率。有效种子区域的大小为
,feat_size是特征图的大小。
3. 方法
Yolov3与Dropblock结合
为了提高模型的泛化能力,我们在yolov3中加入了dropblock (下文简称db)层。在实践中,在yolov3中添加了8个dropblock层。在yolov3模型中,在第1个卷积层之后加入了第一个dropblock层。在dropblock层中,根据设定的参数,将这些被激活的神经元块随机灭活。将丢失一些活跃单位的特征图传递给下一层。在第1、2、3、4、5个resnet模块后添加了第2、3、4、5、6个dropblock层。在第1个上采样层的前面卷积层之间放入第7个dropblock,然后再放最后一层dropblock层在第2个上采样层的前面卷积层的中间(如图1所示)。db1-1代表的是第一个dropblock层,db1-2代表的是第二个dropblock层,依此类推,db1-8代表的是第八个dropblock层;图中Conv2D表示卷积层,BN表示批归一化处理,LeakyReLU表示激活函数,resunit表示一个残差单元,resunit*n表示n个残差单元,resn表示n个r残差模块,zero padding表示零填充层;DBL由卷积层、批归一化处理、激活函数组成,resunit由两个DBL层组成,resn由一个零填充层与一个DBL层和n个残差单元组成,block1-1表示第一个由1个DBL层和一个卷积层组成的模块,显然,图中有三个这样相同的模块。
4. 实验结果
本实验在python3.6、框架tensorflow1.13.1及keras2.2.4环境下进行课堂环境学生抬头低头检测,整个训练过程的学习率及批量尺寸分别为0.01及4,并且迭代20次。整个实验在独立显卡AMD Radeon Pro WX3100并且有Intel(R)Core(TM)i7-9700 CPU和64GB储存的台式电脑上进行。
数据集ClassUD:此数据集是自己创建完成,摄像机的型号为SNOY HXR-MC2500,其中包含2820张教室上课时的学生图片作为训练及测试集,以及240张图片作为测试数据,这些测试数据皆是模仿监控视角的位置与高度拍摄所得数据,范围为一个教室的3~4排左右,且240张图片由40分钟视频以10秒一张图片的截取方式获得,实验数据分布如表1所示。
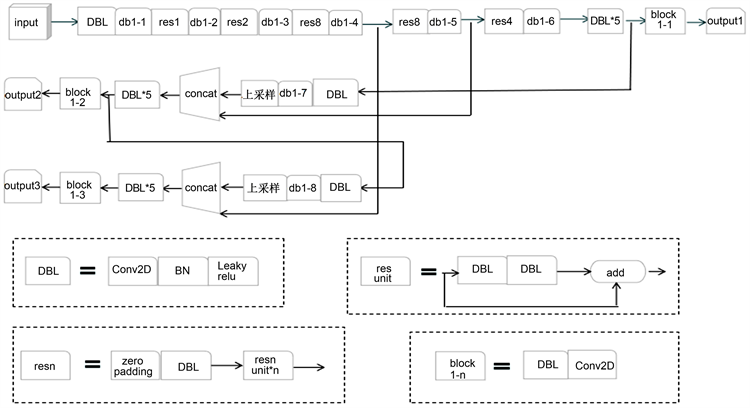
Figure 1. Yolov3 network architecture combined with the db layer
图1. Yolov3与db层结合的网络体系结构

Table 1. Experimental data distribution
表1. 实验数据分布
实验分为三个部分进行,第一个实验用的是yolov3模型在ClassUD数据集上进行训练及测试,第二个实验是在yolov3的基础模型上加了dropblock层(具体网络图如图2),同时也是在ClassUD数据集上进行训练及测试。第三个实验用的是yolov3的精简版tinyyolov3在ClassUD数据集上进行训练及测试。
4.1. 第二部分实验
在这个实验中,我们用yolov3加入dropblock在数据集ClassUD上进行测试,得到的实验结果如图3。其中up AP表示抬头平均精度,down AP表示低头平均精度;从图中我们可以看出抬头的平均精度为91.83%,低头的平均精度为87.01%。

Figure 3. Yolov3 + db P-R curve
图3. Yolov3 +db P-R曲线图
4.2. 第三部分实验
在这个实验中,我们用模型tinyyolov3在数据集ClassUD上进行测试,得到的实验结果如图4。其中up AP表示抬头平均精度,down AP表示低头平均精度;从图中我们可以看出抬头的平均精度为78.06%,低头的平均精度为48.71%。

Figure 4. Tinyyolov3 P-R curve
图4. Tinyyolov3 P-R曲线图
4.3. 实验结果及分析
从上面的三个实验可以看出,在yolov3模型上的抬头检测精度为89.42%,低头检测精度为75.48%,经计算均值平均检测精度为82.45%;在yolov3+dropblock模型上的抬头检测精度为91.83%,低头的检测精度为87.01%,计算出均值平均检测精度为89.42%;在tinyyolov3模型上的抬头检测精度为78.06%,低头检测精度为48.71%,计算得到均值平均检测精度为63.39%。yolov3+dropblock模型相比yolov3模型在抬头的检测精度上提高了2.42%,低头的检测精度提高了11.53%,均值平均检测精度提高了6.97%;yolov3+dropblock模型相比tinyyolov3模型在抬头检测精度上提高了13.77%,低头的检测精度提高了38.3%,均值平均检测精度提高了26.03%;yolov3模型相比tinyyolov3模型在抬头的检测精度上提高了11.36%,低头的检测精度提高了26.77%,均值平均检测精度提高了19.06%。
实践中,我们在yolov3模型结构中加入了dropblock层,并且我们设置drop_size = 7和keep_prob = 0.9。yolov3+dropblock模型实验结果及yolov3 (tinyyolov3)模型实验结果如图5。图5(a)表示yolov3模型下的实验结果;图5(b)表示yolov3+db模型下drop_size = 7、keep_prob = 0.9的实验结果;图5(c)表示tinyyolov3模型下的实验结果,可以看出图5(b)检测的准确率比图5(a)、图5(c)情况都要好,这正是我们在yolov3中加入dropblock层且参数drop_size = 7、keep_prob = 0.9的实验结果。其中蓝色的框线表示状态的真实值,绿色的框线表示检测与真实值相符的结果,红色的框线表示错检的结果,粉红色的框线表示漏检的结果。
在计算机视觉领域的目标检测中,使用深度学习来做目标检测的实验有很多,每一张图片都包含了不同的目标,我们仅对于我们的研究方向建立了数据集,数据图片中包含一种物体(人),但我们把她们在课堂学习中的两种状态(抬头低头)看出是两种目标来进行检测,从而有了我们这篇论文的思想。在本论文中,我们通过均值平均精度(mAP)来评估实验模型,评估的结果如表2,所有的测试均在ClassUD数据集上进行。从表可以看出中,当drop_size = 7、keep_prob = 0.9时,精度比原有的模型提高了6.97%,可以看出,在yolov3+dropblock模型中,drop_size = 7、keep_prob = 0.9时好于yolov3的情况。而yolov3模型又好于tinyyolov3的情况。这证明了dropblock层对于yolov3是有效的,在相同的实验环境下,yolov3模型的训练时间为58.79 h,测试每帧图片的时间为0.57 s,而yolov3+db模型的训练时间为61.51 h,测试每帧图片的时间为0.59 s,tinyyolo3模型的训练时间为14.37 h,测试每帧图片的时间为0.12 s,虽然在训练过程中tinyyolov3的训练速度快于yolov3,但是它的精度却远远低于yolov3。在训练时间与测试时间相差不大的yolov3模型与yolov3+db模型下,显然yolov3+db模型对我们的检测任务效果更好。
Table 2. Evaluation results of different models
表2. 不同模型的评估结果
5. 结论
本文建议的方法利用yolov3结合dropblock进行教室场景学生课堂抬头低头检测。当数据流入dropblock层时,语义信息区域被成块的丢弃,这使得网络不得不集中精力学习剩余语义信息区域中的特征。在ClassUD上的抬头低头检测结果证明我们提出的网络结合在性能上比原来的模型要好。该方法有效地提高模型的鲁棒性和泛化能力。但是教室场景的抬头低头检测仍然面临着一系列的问题,如光照、状态不明显(低头幅度较小,可能误检为抬头)、图像质量(摄像头清晰度较低会影响检测效果)和遮挡问题。未来的工作将集中在寻找一种更适合于教室场景抬头低头状态检测的算法,该算法可以实现更好的鲁棒性,提高检测的精度。