1. 引言
微博是具有巨大用户群体的社交网络平台,用户在微博上发表自己的观点,情绪,记录自己的生活,大量用户的情感趋向对于政府的决策起到很重要的作用。情感分析分为有监督学习和无监督学习。有监督学习需要手动提取特征,如传统的决策树、随机森林等,无监督学习无需手动提取文本特征,借助词典方式或者对句子语法分析进行提取情感信息。
彭丹蕾 [1] 在商品评论情感分析中使用机器学习的SVM方法和深度学习LSTM方法进行对比分析,发现LSTM能够更好的提取词向量中隐藏的情感信息,达到更好的效果。Subarno Pal [2] 等人在电影评论数据集中使用LSTM,并使用LSTM彼此堆叠和双向LSTM进行对比研究,研究发现双向LSTM在此数据集中准确度更高。Luong等人 [3] 提出局部注意力机制,对一个窗口范围内的词进行分布式表示,对固定大小的窗口范围内所有隐状态进行权重计算。本文使用word2vec在已有微博情感语料库中进行词向量训练,同时去除了部分低频词。为了加强词语关联性,提升情感分析准确率,在Bi-LSTM中引入Attention机制应用在已有微博情感评论数据集进行情感分析,实验表明引入Attention机制的Bi-LSTM要优于基准Bi-LSTM算法。
2. 算法描述
本文使用Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification (基于注意力的双向长短期记忆网络关系分类网络)算法,以下简称ATT-Bi-LSTM。这是一种改进的RNN算法模型,模型结构如图1所示。与传统RNN模型相比,此模型的双层LSTM能解决了循环神经网络中的梯度消失问题。LSTM具有门机制,从而能够控制每一个LSTM单元保留的历史信息的程度以及记忆当前输入的信息,保留重要特征,丢弃不重要的特征 [1]。并且引入了Attention机制,解决传统中文文本分类对于长序列编码解码精度下降的问题,针对时序获取关键信息。
2.1. Word2vec模型
Word2vec是Tomas Mikolov通过NNLM模型的改进而研究出来的工具 [4]。Word2vec模型如图2所示,将每个词映射到低维空间,并且其中意思相近的词会被映射到向量空间中相近的位置,解决了表征语义信息、数据稀疏、维度灾难问题。Word2vec主要分为CBOW (Continuous Bag of Words)和Skip Gram两种模式,模型采用的方法也类似,均是根据上下文语句推断当前词发生的概率。本文主要运用Skip Gram进行词向量训练,因为此训练模式在大型语料中效果更好。
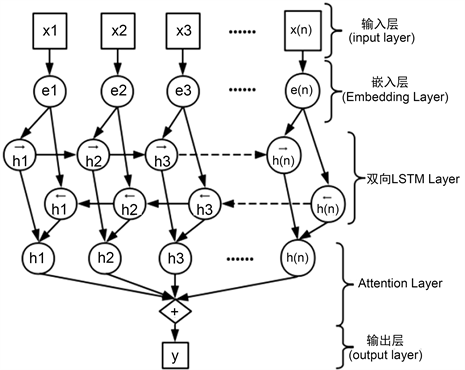
Figure 1. Structure of Attention Bi-LSTM
图1. Attention Bi-LSTM结构
2.2. LSTM模型
LSTM模型解决了RNN模型存在的梯度消失和梯度爆炸的问题,在网络加入了输入门、输出门、遗忘门,可以学习长期依赖信息。结构如图3所示 [5],xt为输入序列;it为输入门;ot为输出门;ct为激活向量;ht表示单元输出激活函数。
遗忘门用来控制遗忘上一层细胞状态的内容,根据上一序列的ht−1和本序列的Xt−1为输入,通过sigmoid激活函数,计算得出需要遗忘的信息ft;输入门用来计算保存到单元终得信息it和当前添加到单元中的新信息
,输出门用来计算输出的信息ot,再乘单元状态通过函数tanh的值,得到输出ht。
根据LSTM结构图得到公式(1)~(6):
(1)
(2)
(3)
(4)
(5)
(6)
其中σ为sigmoid激活函数,tanh为tanh激活函数,w为权重矩阵,b为偏置项,ht表示单元输出激活函数。
LSTM可以对任意长度文本序列进行处理,有效解决了文本不定长问题,并且使当前单元得到本单元之前所有单元的信息,缺点是无法获得本单元之后单元的信息 [6]。考虑到网络能否同时学习前向和后向数据,提出了Bi-LSTM。
2.3. Bi-LSTM模型
Bi-LSTM将正向和逆向LSTM结合起来,一个负责前向信息传递,一个负责后向信息传递,两个LSTM信息组合,传入输出层,解决了汉语的双向语义依赖。
2.4. 注意力机制层
Attention层将LSTM层输出的向量集合表示为
。其Attention层得到的权重矩阵由下面的方式得到公式7~9:
(7)
(8)
(9)
其中,
,dw为词向量的维度,wt是一个训练学习得到的参数向量的转置。最终用以分类的句子将表示公式如下:
(10)
序列输入时,随着序列的不断增长,原始根据时间步的方式的表现越来越差,这是由于原始的这种时间步模型设计的结构有缺陷,即所有的上下文输入信息都被限制到固定长度,整个模型的能力都同样受到限制。引入Attention机制的基本思想是:打破了传统编码器-解码器结构在编解码时都依赖于内部一个固定长度向量的限制。通过保留LSTM编码器对输入序列的中间输出结果,然后训练一个模型来对这些输入进行选择性的学习并且在模型输出时将输出序列与之进行关联。即生成一个权重向量,通过与这个权重向量相乘,使每一次迭代中的词汇级的特征合并为句子级的特征。
3. 微博情感评论情感分析流程
3.1. 分析流程
针对微博情感评论,实验主要包括四步:利用微博情感评论构成语料库、对语料库进行预处理如:分词、去停用词、训练词向量,将训练数据和测试数据传入Attention-Bi-LSTM模型,最后得出模型评价。流程如下图4:
3.2. 数据准备
微博是具有巨大用户群体的社交网络平台,本文选用已分类标注好的微博情感数据集评论进行研究,数据集有119,987条数据,分为正向59,993条和负向59,994条,分别用1和0进行标注,1为正向情感,0为负向情感。部分评论如表1所示。
3.3. 数据预处理
将全部的正向评论和负向评论通过jieba分词进行数据分词、并进行去除停用词后储存合并为一个txt文件得到词集A,部分结果如表2所示。

Table 2. Some results of word set A
表2. 词集A部分结果
通过Python工具包gensim对词集A进行Word2vec词向量训练,得到词集A中所有词的词向量。
3.4. 词向量表示
将预处理完的微博情感评论文本数据传入Word2vec中获得文本的词向量表示,并将生成的此索引通过词嵌入层转换成ATT-Bi-LSTM的输入。
3.5. 情感分析结果生成
最后加入分类器。将实验数据分成两类:正向(1),负向(0),并计算评估指标。
4. 实验结果及分析
4.1. 实验环境
本实验环境如下:Windows10操作系统;CPU Intel CORE i7-6500U;内存大小为8个G,GPU为AMD Radeon R7 M360,开发环境为Tensorflow1.7,开发工具为Pycharm [3]。
4.2. 模型参数
实验参数对于训练结果有着很大影响,本文通过固定参数的方法对ATT-Bi-LSTM参数进行调整,最终词嵌入层大小为200,批尺寸(batch-size)为128,epoch为8,丢弃率(Dropout)为0.5,L2正则值为0.2,隐藏节点数为128。如表3所示。
4.3. 评价指标
本文使用精准率(Precision),和召回率(Recall),F值(F-Measure)对模型进行评价 [7],精准率是分类正向情感正确的示例在实际分类正向情感中的比例,反映了模型对样本的正确识别能力;召回率是模型所有检测出来分类正确的数据占总数据集的比例;F值是精准率和召回率的调和均值,当β = 1时,即为F1值。公式如下。
(11)
(12)
(13)
其中,TP为“真正向”,FP为“假正向”,TN为“真负向”,FN为“假负向”。如表4所示。
4.4. 实验结果及分析
本文通过对比不同epoch下,精准率、召回率和F值,如图5所示。发现在Epoch为30时精准率与召回率、F值明显下降。Epoch为8时模型效果为最好。
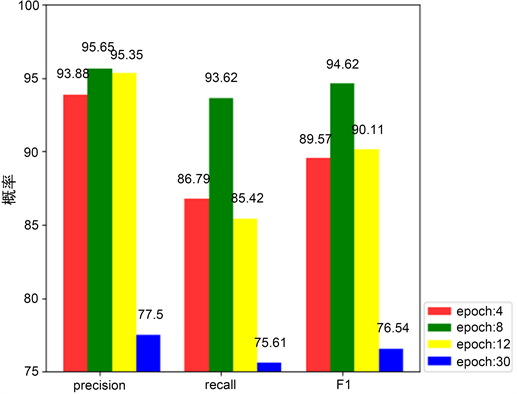
Figure 5. Comparison of results of different epoch
图5. 不同Epoch结果比较
4.5. 算法对比
本文算法与Bi-LSTM的对比在相同数据集和词向量上进行实验对比情况如表5所示。
Table 5. Experimental results of Micro Blog sentiment dataset
表5. 微博情感数据集实验结果
通过对比发现引入Attention机制能提高对于局部信息的提取,模型的精准率、召回率、F1值分别提升了4.54%、4.49%、4.51%。
5. 结束语
本文在微博评论情感分类中对Bi-LSTM引入attention机制,发现引入attention机制对情感分类的效果要优于Bi-LSTM,但训练时间比Bi-LSTM时间长。后续对词典无用低频词进行删除,完善词典的准确度,进一步提高情感分类的效率。
基金项目
北京市教委科技计划项目(KM202011232022);北京信息科技大学2019年度“实培计划”项目;国家自然科学基金(U1936119,61941116);国家重点研发计划课题(Grant No. 2019QY(Y)0602)。
NOTES
*通讯作者。