1. 引言
《“健康中国2030”规划纲要》中提出,健康中国建设需要从以“治已病”为中心向以“治未病”为中心转变 [1],同时随着体检机构的信息化建设的推进,健康体检向健康管理过渡成为一种必然趋势。2016年,国务院印发《关于促进和规范健康医疗数据应用发展的指导意见》,文件指出健康医疗大数据是国家重要的基础性战略资源,其应用发展将带来健康医疗模式的深刻变化,有利于激发深化医药卫生体制改革的动力与活力,培育健康医疗大数据应用新业态 [2]。近几年,随着人工智能、云计算、大数据、物联网等相关技术的发展,已初步建立区域级的健康医疗大数据平台,积累了一定的数据量,形成一个巨大的数据“矿产”。体检中心作为较为成熟的医疗机构,一方面数据格式相对统一,另一方面数据量巨大,如能利用机器学习、人工智能等技术手段挖掘数据背后的知识具有较大科研价值和社会效益。目前因数据隐私等问题体检大数据尚未得到有效利用,体检中心的体检信息缺乏智能算法的分析,只是简单堆积罗列的健康档案文档 [3],同时导致用户从体检到获得体检结果的时间周期很长。
通过文献检索发现关于“健康指数”相关研究目前还鲜有开展,本文创新性的提出一种基于体检大数据,并利用机器学习算法建立一个可以持续跟踪群体健康状况的量化指标——健康指数。该健康指数可以及时客观地反应用户的整体健康状况,以此描绘健康画像,结合历史数据预测健康走势。同时该模型通过用户各项体检指标的变量选择和参数估计,初步揭示群体身体状况与各种指标之间的相互联系,抓住影响健康的关键因素,为用户的健康管理提供参考,达到预防慢性非传染性疾病,提高人群生活质量,降低医疗支出的目的 [4]。
2. 数据和分析方法
2.1. 数据来源
本数据来源某体检医院,包含两个数据表,分别是MEDICAL_DIAG_EXPORT2010和MEDICAL_ INO_EXPORT2010,MEDICAL_INO_EXPORT2010为体检项目记录表,含有数据记录3,529,829条,MEDICAL_DIAG_EXPORT2010为体检诊断结果表,含有数据记录202,203条 [5]。利用Python的Pandas模块提取并转换为Dataframe格式,数据基本情况如表1、表2所示。

Table 1. Results of physical examination
表1. 体检诊断结果表
Table 2. Items of physical examination
表2. 体检项目表
2.2. 数据预处理
2.2.1. 缺失值处理
体检信息数据中45,375例体检者原始数据进行初步筛选,设定阈值剔除缺失值超过体检者2/3的体检指标,剩余102项指标,同时加入“年龄”连续变量数值指标。针对体检诊断结果表格,将“诊断类型”数量为0的患者归为“健康”,用“0”编码;诊断类型数量大于0的为“非健康”,用“1”编码。数据显示,这种归类下健康的病例为25,543例,非健康的病例为19,832例。
2.2.2. 异常值处理
体检信息表诊断标志作为分类变量,存在小数的异常情况,取其整数部分。
连续变量中的年龄数值,如图1所示,存在197岁的异常值,使用中位数替换。同时1岁的体检数据最多,初步推断是婴幼儿体检,而[2, 16]这个年龄区间内数量很少,如果特征没有离散化,可能用户年龄增长一岁就会产生完全不同的输入,会给模型造成很大的干扰。为了让模型具有更好的鲁棒性,应用kmeans聚类方法进行连续变量离散化,分为6个区间:[0, 13.6],[13.6, 31.1],[31.1, 41.1],[41.1, 52],[41.1, 52],[52, 65],[65, 99],对应年龄_0到年龄_6,同时按照表3对区间独热(one-hot)编码化代替对数值变量的归一化 [6]。
Table 3. Binning and one-hot encoding of ages
表3. 年龄值分箱以及对应独热编码
采用独热编码,将一个很大权值管理一个特征,拆分成了许多小的权值管理这个特征多个表示,例如
表示原本的连续型特征(年龄),离散化后拆分为3个特征
,分别用权重参数
进行管理,见公式(1),使得参数管理的更加精细,降低了特征值扰动对模型为稳定性影响。
#(1)
2.2.3. 非数值变量处理
某些体检指标的分类变量是离散的,比如“阴离子间隙”这一个指标中,0代表正常,1代表偏低,2代表偏高,而数值大小和真实的数值大小无关,本质上属于非数字列值,同样需要对数据变量独热(one-hot)编码化处理。处理后的“阴离子间隙”这一列数据将扩充为3列,如表4所示分别是“阴离子间隙_正常”“阴离子间隙_低”“阴离子间隙_高”。
Table 4. One-hot encoding and expanded columns of taxonomic variable
表4 分类变量独热编码扩增列
经过独热编码化加工处理后,提取的二元逻辑变量为180个。
2.3. LASSO回归模型
LASSO (The Least Absolute Shrinkage and Selection Operator)回归是一种线性回归的缩减方法(也称正则化),将回归系数收缩在一定的区域内 [7]。LASSO回归的特点是在拟合广义估计方程的同时进行变量筛选和复杂度调整,从而有效解决变量共线性问题并最终获得精简的统计模型。 [8] Huang等 [9] 利用LASSO从150多个临床指标中筛选出24个关键指标并以此开发并验证了影像组学联合CT和临床危险因素列线图模型,用于预测结直肠癌术前淋巴结转移的风险。LASSO的主要思想是在残差平方和上添加惩罚函数来限制权重
,以此来压缩和简化模型,也就是特征筛选。因此我们在LASSO回归中损失函数上添加一个惩罚项
,m是样本个数,n是特征个数,那么损失函数
是:
#(2)
LASSO回归模型在大规模数据变量模型中具有良好的变量选择性质,当残差平方
很小的时候,一些自变量的系数会随着变为0,这样不仅可以筛选出线性回归模型中具有多重共线性的特征,还能通过量化的权重来直观地展示体检指标对健康的影响情况。
2.4. 健康指数模型
与金融风险控制领域的个人信用风险评分类似,体检健康领域同样需要评分模型的稳健性和可解释性。但是在输入数据上,体检分类指标数据和历史信用记录数据相比,具有离散化的特点,更加适合结合LASSO回归模型的信用评分卡。因此在个人信用风险评分模型 [10] 的基础上,将预测模型由梯度集成决策树改进为LASSO回归模型,增加评分卡的可解释性,同时结合体检的应用场景和输入数据,建立体检评分模型。评分卡的分值刻度将分值Score表示为比率对数的线性表达式:
#(3)
其中,A为补偿,B为刻度,都为常数。
#(4)
#(5)
其中
表示体检者各项检测指标,p由LASSO线性回归模型得到,取值范围[0, 1],表示非健康的概率。引入违约翻倍系数PDO,即当odds (非健康:健康比例)为两倍的时候,分数为Score + PDO:
#(6)
需要计算参数A,B,解两个方程,得到:
#(7)
#(8)
odds0为基准坏/好比例,这里取非健康/健康比例,得到
。为了将大部分的分数限制在100分以内,
设置基准分
,
。代入公式(7) (8)得到
。
3. 结果
3.1. 训练结果
LASSO回归模型的训练需要调整正则化参数alpha。正则化参数越高,模型适应数据的复杂性能力越低,灵活程度越低,出现欠拟合的情况。当正则化参数越小时,模型过拟合。本文使用scikit模块的Lasso CV (Cross Validation),在10折交叉验证中找出最佳的alpha = 0.0003433。
训练后的最优模型选取了32个体检指标,我们定义该32个体检指标为健康指数影响因子,同时淘汰了150个权重较低的体检指标,图2展示了模型权重中10个最重要的非健康特征和10个最重要的健康特征。
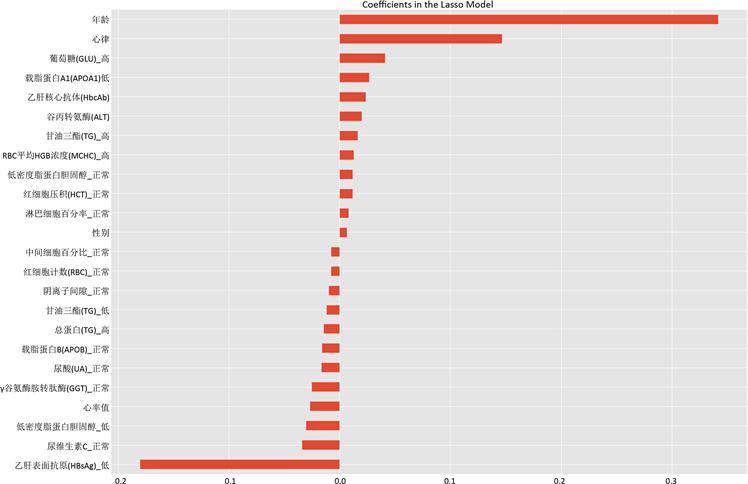
Figure 2. Coefficients histogram of Lasso model
图2. 体检指标权重直方图
图2中非健康特征中影响最大的是年龄的影响,年龄越高,评分越低。其它的非健康特征基本属于异常指标,比如“葡萄糖_高”“载脂蛋白A1_低”“谷丙转氨酶”和“甘油三酯”,这些指标和常见慢性病有关 [11]。表5中举3个用户的例子,为了简化表格,每组对比用户中未列出的体检项目指标变量相同。
Table 5. Physical examination item record and health score prediction of sample users
表5. 示例用户体检项目记录和健康分预测表
Table 6. Coefficients of three physical examination items
表6. 三个体检项目的指标权重
从表5中看出,年龄相近的体检用户之间,由于体检项目指标的差别,预测健康分在相邻的区间中,体现了模型的稳健性。表6是三个体检项目中不同指标的权重,正值代表非健康影响影响因素,负值代表健康影响因素,绝对值越大影响越大。通过量化的指标权重,揭示不同的体检指标对健康的正负面影响,具体来看,用户A的三项异常指标导致影响健康分较低,同时表7的疾病诊断结果为“脂肪肝”也印证了三项指标和健康之间的联系。
Table 7. Diagnostic results for the sample users
表7. 示例用户的诊断结果表
表8的中两个不同年龄段的用户体现评分模型的区分度,其中E用户处于中老年,同时如表9所示,该用户体检指标中的异常指标:“乙肝核心抗体(HbcAb)”“尿维生素C”和“阴离子间隙”属于权重绝对值较大指标,因此健康分低于该年龄区间的平均分数29.5分。同时D用户的异常指标:“低密度脂蛋白胆固醇”和“淋巴细胞百分率”在模型中的权重绝对值相对较小,因此健康分高于同一年龄段的平均健康分78.9。所以健康分模型不仅在同一个年龄段之间,在不同年龄段之间也可以客观地反映出用户的健康状况。
Table 8. Physical examination item record and health score prediction of sample users
表8. 示例用户体检指标及健康分
Table 9. Coefficients of physical examination items
表9. 指标权重
3.2. 模型评估和比较
3.2.1. 模型评估
根据图1我们发现年龄分布不符合正态分布,显然年龄也不符合正态分布,我们对其余30个健康指数影响因子逐个作图分析发现他们基本上符合正态分布。为解决多随机因素作用的问题,法国数学家棣莫弗和拉普拉斯首先提出了中心极限定理并给出了证明 [12] [13] [14],该定理表明所研究的随机变量如果是有大量独立的而且均匀的随机变量相加而成,那么它的分布将近似于正态分布。下图展示健康指数模型输出的用户评分分布直方图。线性回归模型中的假设前提是因变量p服从正态分布,而在图3中,分数特别低(低于30)和特别高(高于100)的人占比都较少,大多数健康分数中等(75左右),整体上基本符合正态分布,符合线性回归模型的先验假设。
表10显示健康分数分值越高,非健康率越低,体现了体检者可以通过分数的高低进行健康状况的评估。
3.2.2 模型比较
对比运用PCA (主成分分析) [15] 的统计方法,因获得的主成分公共因子是实际自变量因子的线性组合,所以其难以与分析健康因子的实际问题相对应。特征变量较少的样本适合使用PCA进行降维,因其对公共因子有更好的解释性,本文的体检指标数量较多(182个),不适合使用PCA分析。
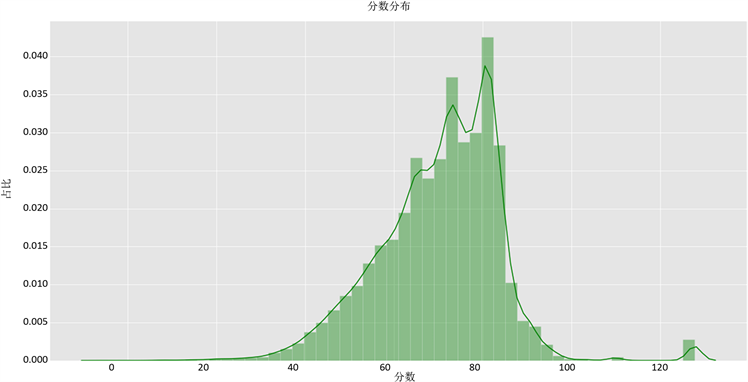
Figure 3. Histogram of score distribution
图3. 分数分布直方图
Table 10. Interval statistics of health scores
表10. 健康分区间统计表
对比应用XGBoost中的回归模型,模型评价指标为预测值的均方误差(MSE),其中
为样本的个数,
是真实数据,
是预测值。MSE越小,说明预测模型描述实验数据具有更好的精确度。
#(9)
经过10折交叉验证,最后得到不同机器学习模型使用均方误差的评分如表11所示。
Table 11. Scores for different machine learning models
表11. 不同机器学习模型评分
其中LASSO回归模型在数据集中的准确率略优于其他模型,与之相近的梯度提升决策树只能对变量进行重要性排序 [16],并不能输出非健康概率的最终计算权重系数,而LASSO回归中模型的实际系数即代表健康/非健康权重,可解释性更好。
4. 结论
本文基于体检数据,在个人信用评分卡模型基础上提出了一种基于LASSO回归的健康指数模型。通过模型的对比,本文使用的LASSO模型的变量压缩效果可以很好地筛选自变量,兼具变量子集选择和岭回归的优点,因此可以兼顾解释性和预测准确率,在个人信用评分中已经得到广泛应用。在和随机森林 [17] 等更加复杂的机器学习模型的对比中,LASSO回归模型的预测精确率在体检大数据集上表现的更好,同时该模型可以更好地解释体检指标特征对健康评分的影响。实验结果表明该健康指数模型大体上呈现正态分布,符合线性回归模型的先验假设。通过该健康指数,体检用户可以从宏观整体上直观感知个人身体健康状况水平,为长期健康管理提供一个可以参考的量化指标,降低体检用户同医生的沟通成本,督促用户更加关注身体整体健康状况水平。
本文提出的健康评分指数建模中体现了区分度和稳健性,但是本文仍存在几方面问题:一是先验假设中的体检健康标准科学性问题,是否可以由疾病诊断分类中得到更加权威的体检健康标准来改进二值化设定;二是健康影响因子中各因子独立性问题,需要进一步分析加以筛选。如何更加深入地将数据科学和体检健康科学结合起来优化评分模型,是下一步研究的重点。
基金项目
国家级大创项目基金支持,编号202010384213.