1. 引言
随着互联网的发展和计算机技术的提高,光学字符识别(Optical Character Recognition, OCR)技术 [1] 也得到了有效的提高。通过OCR识别技术可以有效地从图片上面提取到所需要的文字信息。但是目前通用的OCR算法只针对于简单的运用场景,一旦场景掺杂过大的因素,识别效率和召回率都会急剧下降。OCR识别技术主要分文本检测和文本识别两部分 [2] [3]。文本检测作为文本识别的前提,在整个文本信息提取和理解过程中起着重要的作用。只有正确的定位到文本区域才能进行正确的文本识别。正确的文本区域检测对提高文本识别准确有着重要的作用,因此,如何提高文本检测是一个重要的课题。
国内外学者利用不同的方法解决了文本检测问题。Tian [4] 提出的一种新型的连接主义文本提议网络(CTPN),使用一种垂直锚定机制,共同预测每个固定宽度候选位置和文本/非文本的分数。通过最大分数确定文本行位置,这大大提高文字定位的准确度。但是CTPN只针对于水平文字检测有很高的效率。为此,Shi等人 [5] 提出一种定向文本检测方法SegLink,在CTPN的基础上进行改进。主要的思想是将文本分为两个本地可以检测的元素,通过端对端训练的完全卷积神经网络在多个尺度上密集检测这两个元素。最终检测时通过连接段的组合。CTPN检测法、SegLink检测法是通过先预测proposals (预选框)、segment (切片),然后再回归、合并等方式实现对文本的检测。由于CTPN模型过于冗余复杂,Xinyu Zhou [6] 等人提出EAST检测法,将中间过程缩减为只有FCN (全卷积网络)、NMS (非极大值抑制) [7] 两个阶段,而且输出结果支持文本行、单词的多个角度检测,既高效准确,又能适应多种自然应用场景。但是EAST算法仍然存在着感受野不够大,长文本检测效果不佳的问题。
因此,为了解决EAST算法的存在的问题,本文在EAST算法上进行改进,通过改进EAST算法的结构,利用ASPP网络替代EAST算法中的部分结构,引入BLSTM神经网络 [8],增加输出特征图之间的关联性,从而改善了EAST算法的文本检测效果,提高算法的性能。
2. 改进EAST算法
2.1. EAST算法介绍
大部分传统的文本检测算法都是由多个阶段组成,在准确性和效率上面表现不是很好。EAST算法提出端到端的文本定位方法,消除多个中间的stage,直接预测文本行。它只有两个阶段,第一个阶段基于全卷积网络(FCN)模型,直接产生文本框预测;第二个阶段对生成的文本框进行非极大值抑制(NMS)以产生最终结果。该模型放弃了不必要的中间步骤,进行端到端的训练和优化。
如图1所示,EAST算法网络结构分为三个部分:特征提取层,特征合并和输出层。
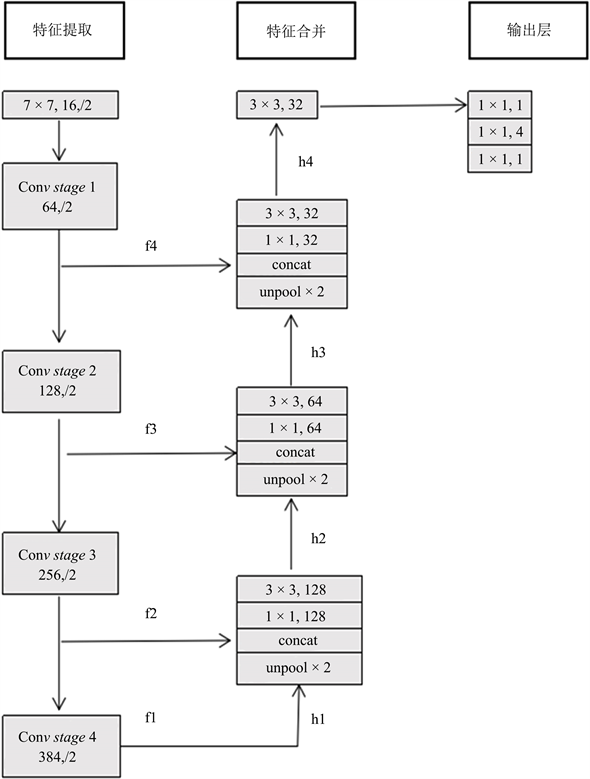
Figure 1. Architecture of EAST algorithm network
图1. EAST算法网络结构
特征提取层:利用在ImageNet数据集上预训练的卷积网络参数初始化。基于VGG16模型 [9] (或者ResNet-50模型 [10] )作为主干神经网络提取文本的浅层和深层的纹理特征。提取模型的最后四个级别的特征图,其大小分别为输入图像的1/4,1/8,1/16,1/32。通过提取出不同尺度的特征图,实现对不同尺度文本行的检测(大的特征图擅长检测小物体,小的特征图擅长检测大物体)。
特征合并:特征合并主要采取U-net思想,通过上采样,将上一级别的特征图和上采用的特征图进行合并,再通过1 × 1的卷积进行减少通道数量和计算量。接着通过3 × 3的卷积核运算得到新的特征图。
输出层:输出的特征图进行不同的卷积操作,最后得到分数特征图和多通道几何图形特征图。
EAST算法的损失函数主要由两个部分组成,分类损失函数
和几何损失函数
:
(1)
上式中,
代表该像素是否存在文字的损失,
代表IOU和角度的损失,
代表两个损失之间的重要性。原文的实验中将
设置为1 [11]。
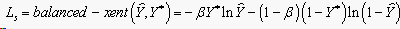 (2)
(2)
上式中,
代表分数图的预测,
代表标注值。
代表正负样本之间的平衡因子。
几何损失分为IOU损失和旋转角度的损失。公式如下:
(3)
(4)
上式中,
是对旋转角度的预测,
表示标注值。总体的损失为:
(5)
2.2. 加入ASPP网络
传统的卷积神经网络模型中,下采样过程是为了扩大感受野,使得每个卷积输出都包含较大范围的信息,对于提取抽象化信息有很大帮助,但在这个过程中,图像的分辨率不断下降,包含的信息越来越抽象,而图像的局部信息与细节信息会逐渐丢失,虽然现在也有通过线性插值上采样来恢复分辨率的手段存在,但在这个过程,还是不可避免的会造成信息的损失。而EAST算法采用的主干网络无论是VGG16还是resnet50都存在利用下采样用来增大感受野,但都不可避免的导致分辨率下降。而空洞卷积的出现解决了下采用带来的分辨率下降的问题。利用空洞卷积可以实现网络不进行下采样,同样能启到扩大感受野的目的。
本文利用空洞空间卷积池化金字塔ASPP (Atrous Spatial Pyramid Pooling)网络来替代EAST算法的主干网络VGG16 (或者resnet50)的stage 4模块。ASPP对所给定的输入以不同采样率的空洞卷积并行采样,相当于以多个比例捕捉图像的上下文。
如图2所示,本文EAST算法的主干网络采用的是resnet50,利用ASPP网络替代EAST算法的主干网络的stage 4模块,ASPP网络包括5个模块,通过将stage 3的输出特征图进行5种不同的操作,第一个模块是进行平均池化,1 × 1的卷积层进行通道数变换,最后通过双线性插值恢复分辨率。第二个到第5个模型都是空洞卷积,但每个的卷积核的扩展率不同,分别取了1,6,12,18;之后将这五个模块的输出拼接到一起,通过一个1 × 1的卷积层,降低通道数到需要的数值,作为下一步操作的输入。
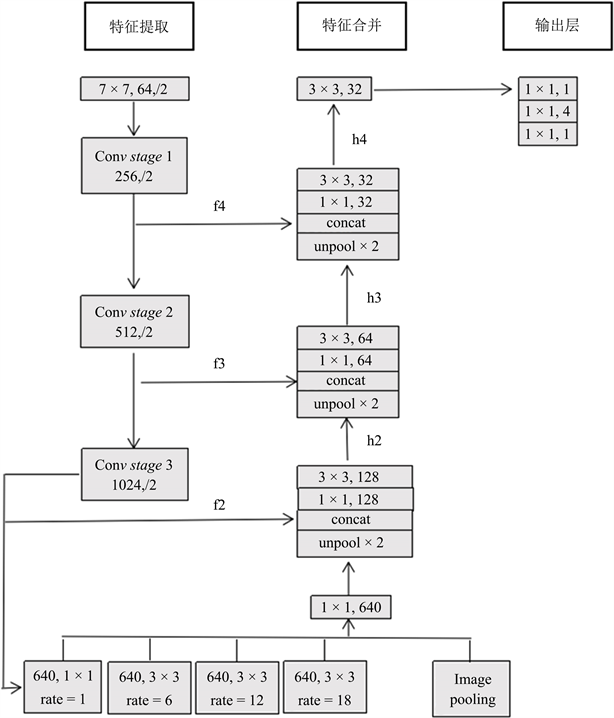
Figure 2. Add ASPP network structure
图2. 加入ASPP网络结构
2.3. 增加BLSTM网络
文本检测不只是检测某个位置是否是单个文字,同样检测文字之间是否存在连续性。文字存在特征信息,同时邻近的文字存在关联关系。CNN学习的是感受野内的空间信息,LSTM学习的是序列特征。对于文本序列检测,显然既需要CNN抽象空间特征,也需要序列特征。
本文在EAST网络的特征合并和输出层之间加入BLSTM网络。BLSTM是一种特殊的循环长短期记忆神经网络,由双向LSTM神经网络组成。
如图3所示,本文在EAST算法特征合并层和输出层之间插入BLSTM网络,BLSTM网络结构如图4所示。BLSTM网络能将每个特征的前后序列呈现为两个单独的隐藏状态,以分别捕获序列过去和未来的信息,然后再将两个隐藏的特征序列连接起来形成一个新的特征样本进行最终输出 [12]。本文通过EAST算法特征合并后输出的特征图进行序列化关联,使得得到的序列样本更加合理均匀具有连续性。
Figure 3. Adding the network structure of BLSTM
图3. 加入BLSTM网络结构
3. 实验结果
本实验在tensorflow深度学习框架上进行。采用GTX2080Ti的显卡进行改进的EAST算法实验。实验使用resnet-50网络模型作为EAST算法的主干网络进行预训练模型。使用的数据集是ICDAR2013和ICDAR2015的训练数据集。ICDAR2013训练集具有229张标注训练集,ICDAR2015训练集具有1000张标注训练集。以ICDAR2015测试集作为测试,ICDAR2015测试集有500张图片。这些数据集是由谷歌公司制作,数据集均是在自然场景下采集的,图中的文本是任意方向和位置的。
实验过程主要将图片送入resnet-50网络模型,经过4次下采用,将获取到特征图送入ASPP网络,ASPP网络在不损失图片分辨率的情况下,提高感受野。再通过3次上采用并且每次和原有对应的下采用特征图进行融合,最终获取特征图。特征图经过不同的卷积获取出来的数据和标注的数据集进行对比,通过ADAM优化器训练网络模型,获取较优的模型参数。本实验的优化器采用ADAM优化器,每个batch size等于8,ADAM的学习率从1E−3开始,每10,000批次衰减十分之一,训练到34万次获取到最优解。
将文中算法与其他算法 [13] [14] [15] 在ICDAR2015数据集上进行比较,结果如表1所示。

Table 1. Comparison of different text detection algorithms
表1. 不同文本检测算法比较
其中本算法在ICDAR2015文本定位任务上的召回率(针对原样本而言的,它的含义是在实际为正的样本中被预测为正样本的概率)为77.84%,精准率(针对预测结果而言的,它的含义是在所有被预测为正的样本中实际为正的样本的概率)为86.24%,F-score为81.82%,优于经典EAST算法。
通过对比原有EAST算法以及改进EAST算法的检测效果,如图所示。
图5中包含两组自然场景文本图片,每组图片中的左侧为原始EAST算法的检测效果,右侧为改进EAST算法的检测效果。从图中可以看出原始EAST算法在检测长文本会遗漏部分文本,以及文本检测的边界过长导致部分没有联系的文本本框选,而本算法通过扩大感受野和增强文本之间的连续性,可以检测出跟多的文本,以及正确的框选文本的合理边界,更好地检测出自然场景文本区域,提高检测的准确率。
实验通过利用ASPP网络替代原来EAST算法的主干网络resnet-50的stage 4,再通过添加BLSTM网络增强特征图序列化关联。实验结果比经典的EAST算法具有更高的精确率和召回率,F-score到达81.82%。总体相对于经典的EAST算法有着一定的提高。

Figure 5. The detection effect of two EAST algorithms
图5. 两种EAST算法检测效果
4. 结论
本文在经典的EAST算法的基础上进行改进来实现文本检测。由于经典的EAST算法存在感受野不够大问题,通过利用ASPP网络来替代EAST算法的主干网络的stage 4模块,在不损失分辨率的情况下提高EAST算法的感受野。同时EAST算法也存在文本检测边框过长和过短的问题,通过添加BLSTM网络,增加文本特征图序列之间的关联,提高了文本检测分界线的效果。相比于经典的EAST算法,本文实现的算法在精确率和召回率上都提高了。同时本文仍存在不足,在后续的实验中可以通过调整参数和利用Dense ASPP网络来替代ASPP网络改进算法,进一步提高文本检测的效果。
基金项目
北京市自然科学基金项目(4202025),国家自然科学基金项目(61872333),北京教委科技计划项目(KM201911232003),北京未来芯片技术高精尖创新中心科研基金(KYJJ2018004)。
NOTES
*通讯作者。