1. 引言
近年来,我国的电子商务产业迅速发展,市场规模逐年扩大,以京东、阿里为代表的电商公司正在不断改变自身的运营及服务方式,单纯的线上模式已难以满足客户的体验以及速度要求 [1]。在此趋势下,各大电商积极向线上线下一体化的方向探索,尝试在需求地建立前置物流中心,以配合区域物流中心的调度策略,优化自身物流配送体系,降低物流成本并提高物流网络的运作效率。国内外学者围绕着选址问题进行了大量的研究,从简单的线性、单目标、确定解逐步转变为非线性、多目标、不确定解 [2]。Darani等 [3] 等将层次分析法(AHP)与理想解相似度排序(TOPSIS)进行耦合,以有效地进行停车场的选址;邱晗光等 [4] 提出了两层嵌套Logit选择模型,运用多目标粒子群优化算法对城市配送节点的路径进行优化;Bravo等 [5] 构建了加权目标规划模型对海上风电场进行选址。前置仓作为2017年提出的新型且具备储存配送功能的末端仓库,目前针对其选址问题还没有形成一套完善的理论,因此如何对前置仓进行有效地选址是电商公司关注的热点问题。
前置仓选址需要不同领域或部门人员共同参与,考虑物流成本、服务水平等多个冲突目标,属于一个多属性群决策问题。在群决策过程中,由于不同的社会背景、知识结构以及客观事物的复杂性和不确定性,不同决策者可能倾向于采用自己偏好的信息表达形式给出其对备选地点的评价值。同时,由于人类的知识、经验等相关能力的限制,决策者往往是有限理性的。在决策过程中,决策者不仅只关注当前所选方案的获得结果,还会将所选方案的结果与其它方案可能获得的结果进行比较,如果发现其它方案可能获得更好的结果时会感到后悔,反之,则感到欣喜。因此,决策者的后悔–欣喜心理都会不同程度地影响其实际决策行为,尽量规避选择使自己后悔的方案。针对前置仓选址问题中评价信息的异构性和决策者心理行为,本文基于后悔理论提出了面向异构信息的多属性群决策方法。首先,为了处理异构评价信息,提出了将梯形区间二型模糊数、影像模糊数和多粒度区间语言术语统一转化为区间二元语义的方法;然后,考虑到决策者的心理行为,利用后悔效用计算各前置仓备选地点与正负理想方案的距离;并以此为基础,利用TOPSIS法确定各前置仓备选地点与正理想方案的相对贴近度,以实现备选地点的排序及择优。最后,通过算例分析说明所提出方法的可行性。
2. 理论基础
2.1. 模糊集
经典集合理论中,元素的隶属度只能取0或1,是一种非此即彼的关系。基于对集合中元素隶属关系不确定性考量,Zadeh于上世纪六十年代提出了以隶属函数为理论基础的模糊集概念 [6],元素隶属度不再是{0, 1},而是拓展到了区间[0, 1]。隶属度的模糊化使模糊集具备了对不确定性概念的描述能力。
定义1 [6]:设U是一非空有限论域,则其上的模糊集F可表示为
, (1)
其中,
,
表示模糊集的隶属函数,取值范围为[0, 1],反映了论域U中的元素x隶属于集合F的程度。
与经典集合中的补、交、并等运算规则相应,Zadeh提出了模糊集的运算规则。
定义2 [6]:设U是一非空有限论域,F1和F2为论域上的两个模糊集,则有
1)
,
2)
,
3)
。
2.2. 梯形区间二型模糊数
Zadeh教授于1975年提出了二型模糊集(Type-2 Fuzzy Set)的概念 [7]。二型模糊集是对一型模糊集的拓展,其核心思想是将一型模糊集的隶属度模糊化,以此表示高阶不确定性。
定义3 [8]:设X为论域,则定义在论域X上的二型模糊集A可表示为
, (2)
其中,x是主要变量,
是x的主要隶属度函数,
是次要变量。式(2)可等价表示为
,(3)
其中,
是x的次隶属度函数,积分符号
表示遍历所有的x和u。
当二型模糊集A中变量x的次隶属度恒为1时,二型模糊集A成为区间二型模糊集
,其定义如下。
定义4 [8]:设X为论域,若论域上的二型模糊集A满足
,则称
为区间二型模糊集,其表达式如下所示:
,(4)
其中,x是主要变量,
是x的主隶属度函数。
定义5 [8]:区间二型模糊集
的全体主隶属函数围成的区域称为不确定迹,其表达式为
。 (5)
显然,区间二型模糊集的不确定迹是由上隶属度函数和下隶属度函数所围成的区域。
定义6 [9]:当区间二型模糊集的上下隶属度函数为梯形模糊数时,则称其为梯形区间二型模糊数,表示为
, (6)
其中,
是一型模糊集,
表示上隶属度函数的参数值,对应的隶属度值为
;
表示下隶属度函数的参数值,对应的隶属度值分别为
。梯形区间二型模糊数的几何表示如图1所示。

Figure 1. Trapezoidal interval type-2 fuzzy number
图1. 梯形区间二型模糊数
定义7 [9] [10]:若
,对于任意三个梯形区间二型模糊数
,
,
,
其对应的运算规则如下:
1)
,
2)
,
3)
,
4)
。
定义8 [11]:对于梯形区间二型模糊数
,其期望值定义为:
。(7)
2.3. 影像模糊集
影像模糊集(Picture Fuzzy Set)是由Cuòng提出的新型模糊集 [12]。影像模糊集是对经典模糊集的拓展,它包含支持、反对、中立等三个方面的隶属度,可以更全面地刻画不确定性信息。
定义9 [12]:设集合X为一给定的论域,则其上的影像模糊集P可定义为:
, (8)
其中,
是
的支持隶属度,
是
的中立隶属度,
是
的反对隶属度,
满足约束条件
。同时,对于
,
是
的拒绝隶属度。当
时,影像模糊集退化为直觉模糊集。为表示简便,影像模糊数可表示为
,其中,
,
,
且
。影像模糊数中的支持度,反对度,中立度和拒绝度分别表示了决策者在评价过程中支持、反对、中立和拒绝的不同态度。
定义10 [13]:对于影像模糊数
,其得分函数与准确函数可分别定义为:
, (9)
。 (10)
定义11 [13]:设
和
为任意两个影像模糊数,则依据影像模糊数的得分函数与精确函数可对影像模糊数
和
进行排序:
1) 若
,则
。
2) 若
,则
。
3) 若
,则
a) 若
,则
,
b) 若
,则
,
c) 若
,则
。
2.4. 区间二元语义
定义12 [7]:
为语言术语集,其中,
为语言术语,
,g为偶数,g+1为语言术语集的粒度。通常,语言术语集应满足以下性质:
1) 有序性:若
,则
。
2) 逆算子:
,则
。
3) 极大化和极小化运算:若
,则
,
。
在决策过程中,直接以对语言评价信息进行集成运算会造成评价信息的丢失,从而导致决策结果失真。为解决这一问题,Herrera和Martínez基于符号平移提出了二元语义的概念 [14],采用一个二元组
表示语言评价信息。
定义13 [14]:设
为语言术语集,则
对应的二元语义可由如下函数获得
,
(11)
其中,si是语言术语集中的语言术语,
是符号转移值,满足
,round为取整算子,g + 1为语言术语集的粒度。
定义14 [14]:设
为语言术语集,
为二元语义,
,
,则
对应的实数可由如下函数求得:
,
。 (12)
定义15 [14]:设
为语言术语集,
可称为区间二元语义,
为语言术语,
,其中
(当
时,
),则区间数
(
且
)可通过函数
转换为相应的区间二元语义:
,
,其中
(13)
相反,区间二元语义
也可以通过函数
转换为相应的区间数
:
。 (14)
在实际决策过程中,不同决策者往往会倾向于选择不同的语言评价粒度。因此,在对语言评价信息进行集成前,需要首先将不同粒度语言评价信息进行一致化,即将不同粒度的语言评价信息转化为同一个语言术语集中的语言评价信息 [15],该语言术语集称为基础语言术语集。
2.5. 后悔理论
后悔理论是行为决策中得到广泛应用的研究成果 [16] [17]。后悔理论认为决策者在决策过程中不仅只关注当前所选方案的获得结果,还会将所选方案的结果与其它方案可能获得的结果进行比较,如果发现其它方案可能获得更好的结果时会感到后悔,反之,则感到欣喜。因此,决策者的后悔–欣喜心理都会不同程度地影响到决策者的实际决策行为,决策者在决策过程中会尽量规避选择使自己后悔的方案。后悔理论的决策过程分为两个阶段:前期编辑阶段和后期评价阶段。编辑阶段主要是感知效用函数的构建过程,通过构建效用函数和后悔–欣喜函数,将不确定属性信息转化为感知效用;评价阶段是对综合感知效用的评估和选择,基于效用函数和后悔–欣喜函数共同确定方案综合感知效用,并依据综合感知效用值进行决策。因此,后悔理论中,决策者的感知效用函数由所选方案效用函数和后悔–欣喜函数两部分组成。设x1和x2分别表示方案A1和A2的预期结果,则决策者对方案A1的感知效用为
, (15)
其中,
和
分别表示方案A1和A2的效用函数,
表示后悔–欣喜函数。因此,在后悔理论中,效用函数和后悔–欣喜函数是研究的关键。在后悔理论中,效用函数反映了决策者对当前方案的各项指标进行综合评价后所形成的主观结果感受效用。在实际决策中,由于决策者往往是风险规避的,效用函数
通常是单调递增的凹函数。此外,后悔–欣喜函数反映了决策者对当前方案所获的结果与其它方案获得的结果进行比较之后的心理感受程度,通常是单调递增的凹函数。
3. 异构群体信息下基于后悔理论的前置仓选址模型
针对异构决策信息环境下的前置仓备选地点选择问题,本节提出了基于后悔理论的前置仓选址模型。首先,给出了将梯形区间二型模糊数、影像模糊数和区间语言术语统一转化为区间二元语义的方法;然后,采用后悔效用距离和TOPSIS法确定各前置仓备选地点与正理想方案的相对贴近度,实现备选地点的排序及择优。
3.1. 异构信息的转化
对于异构评价信息环境下的前置仓选址问题,设
为m个前置仓备选地点集,
为评价指标集,
为指标集对应的权重向量,并满足
,
,且
。决策者组成的集合记为
。由于不同的知识背景和信息偏
好,决策者可能对备选地点给出不同形式的评价信息,这里考虑梯形区间二型模糊数、影像模糊数及多粒度区间语言术语三种评价信息表达形式。根据评价信息表达形式,决策者集合可分类为
,其中,
表示给出的评价信息为梯形区间二型模糊数的决策者,
表示给出的评价信息为影像模糊数的决策者,
表示给出的评价信息为多粒度区间语言术语的决策者。决策者
给出备选地点
在指标
下的评价值记为
,其中
表示梯形区间二型模糊数,
表示影像模糊数,
表示多粒度区间语言术语。
为处理异构评价信息,本文将梯形区间二型模糊数、影像模糊数和多粒度区间语言术语统一转化为区间二元语义
,其中,
、
为基础语言术语集
中的元素,
。本文采用基础语言术语集
,其中各语言术语对应的三角模糊数隶属度函数如图2所示。

Figure 2. Membership function of linguistic term set S
图2. 语言术语集S的隶属函数
1) 梯形区间二型模糊数转化为区间二元语义
假设备选地点
在指标
上评价值为梯形区间二型模糊数
,
为基础语言术语集。为了将梯形区间二型模糊数
转化为区间二元语义
,首先通过映射
将梯形区间二型模糊数
转化为区间二维语义集
:
,
, (16)
, (17)
, (18)
其中,
,
,
为梯形区间二型模糊数
和基础语言术语S的隶属函数,
。
然后,利用映射
和区间二元语义逆算子将梯形区间二型模糊数
对应的区间二维语义集
转化为区间二元语义
:
,
, (19)
, (20)
其中,式(20)可以由定义15确定。
例1. 若梯形区间二型模糊数
,基础语言术语集
及其各语言术语对应的隶属度函数见图2,
与S之间的关系如图3所示。

Figure 3. Relationship between trapezoidal interval type-2 fuzzy number
and linguistic term set S
图3. 梯形区间二型模糊数
与语言术语集S之间的关系
首先,利用式(16)~(18)将梯形区间二型模糊数
转化为区间二维语义集:
然后,利用式(19)和(20)将区间二维语义集
转化为区间二元语义:
由定义15可知,
,则梯形区间二型模糊数
对应的区间二元语义为
。
2) 影像模糊数转化为区间二元语义
假设备选地点
在指标
上的评价值为影像模糊数
,
为基础语言术语集。影像模糊数反映了决策者支持、中立和反对等方面的态度。依照支持及不反对程度,影像模糊数
可以对应于
和
两个区间,根据这两个区间可以将其转化为相应的区间二元语义。为了将影像模糊数
转化为区间二元语义
,首先通过映射
将影像模糊数
转化为区间二维语义集
:
,
, (21)
, (22)
, (23)
其中,
,
,
为影像模糊数
和基础语言术语集S的隶属函数。
然后,利用式(19)和(20)将影像模糊数
对应的区间二维语义集
转化为区间二元语义
。
例2. 若影像模糊数
,基础语言术语集
及其各语言术语对应的隶属度函数见图2,
与S之间的关系如图4所示。
首先,利用式(21)~(23)将影像模糊数
转化为区间二维语义集:
然后,利用式(19)和(20)将区间二维语义集
转化为区间二元语义:
由定义15可知,
,则影像模糊数
对应的区间二元语义为
。

Figure 4. Relationship between picture fuzzy number
and linguistic term set S
图4. 影像模糊数
与语言术语集S之间的关系
3) 多粒度区间语言术语转化为区间二元语义
假设备选地点
在指标
上的评价值为区间语言术语
。当区间语言术语
所属的语言术语集与基础语言术语集S的粒度相同时,可直接根据定义14进行转换。当两者的粒度不同时,可以利用下面方法将不同语言粒度的语言评价信息转化为相同粒度。假设
是给定的基础语言术语集,其粒度为g+1,
是区间语言术语
所属的语言术语集,其粒度为k+1,则通过映射TF可以将区间语言术语
转为基于粒度为g+1的区间语言术语:
.
, (24)
, (25)
其中,
和
是语言术语与语言术语下标值的转化与逆向转化函数。
3.2. 区间二元语义后悔效用的确定
在决策问题中,决策者会将所选方案的结果与其它备选方案的结果进行比较,若选择其它方案会带来更好的结果,则决策者会感到后悔,反之则感到欣喜。效用函数是衡量各个方案结果的常见度量,常为非减实值函数,即较大的评价值会得到较大的效用值。本文采用HARA效用函数 [18] 定义区间二元语义信息的效用值,并以此对各个方案进行选择。
定义16:若
为一个区间二元语义,则其HARA效用值可定义为
, (26)
其中,
,
是二元语义对应的实数值,可通过定义15确定;
,
,
为HARA效用函数的参数值 [18]。
在区间二元语义效用值基础上,为确定区间二元语义的后悔效用,首先要构造后悔–欣喜函数
。由于决策者对于后悔和欣喜都是风险规避的,函数
是单调递增的凹函数,根据文献 [19] 中的后悔–欣喜函数,区间二元语义的后悔效用定义如下。
定义17:对于任意两个区间二元语义
和
,则
相对于
的区间二元语义后悔效用可定义为:
, (27)
其中,
为区间二元语义的HARA效用值,
为两个区间二元语义的效用值偏差,
为决策者的后悔规避函数,
为后悔规避系数,且
越大,决策者的后悔规避程度越大 [16] [20]。
基于后悔效用,两个区间二元语义之间的后悔效用距离定义如下。
定义18:对于任意两个区间二元语义
和
,则它们之间的后悔效用距离为
, (28)
其中,
,
分别为
相对于
和
相对于
的后悔感知效用,可利用式(27)求得。当两者的后悔规避系数
和
相同时,
为两个区间二元语义
和 的HARA效用差值。
的HARA效用差值。
3.3. 异构群体信息下基于后悔理论的前置仓备选地点选择
针对梯形区间二型模糊数、影像模糊数、多粒度区间语言术语等形式的评价信息,基于后悔理论的前置仓备选地点选择方法的步骤如下:
步骤1. 构建异构决策矩阵。假设各个决策者以梯形区间二型模糊数、影像模糊数和区间语言术语给
出评价信息,构建异构决策矩阵 。
。
步骤2. 将异构决策矩阵转化为区间二元语义决策矩阵。利用3.1小节的异构信息转化方法将各个决
策者给出的异构决策矩阵 统一转化为区间二元语义决策矩阵
统一转化为区间二元语义决策矩阵 ,其中
,其中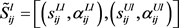 为区间二元语义。
为区间二元语义。
步骤3. 确定群体区间二元语义决策矩阵。利用式(29)的区间二元语义加权集成算子,将区间二元语
义决策矩阵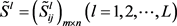 集结为群体区间二元语义决策矩阵
集结为群体区间二元语义决策矩阵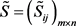 。
。
 , (29)
, (29)
其中,L为决策者的数量。
步骤4. 根据式(30)和(31)确定群体区间二元语义决策矩阵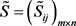 的正理想方案
的正理想方案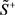 和负理想方案
和负理想方案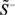 。
。
 , (30)
, (30)
 , (31)
, (31)
其中,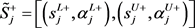 ,
,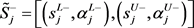 ,
, 。
。
步骤5. 利用式(28)分别计算在指标 下各备选地点
下各备选地点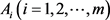 相对于正理想方案
相对于正理想方案 和负理想方案
和负理想方案 的后悔效用距离,构建后悔效用距离矩阵
的后悔效用距离,构建后悔效用距离矩阵 和
和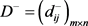 。
。
步骤6. 利用式(32)和(33)分别对各备选地点 在所有指标下相对于正、负理想方案的后悔效用距离进行集结。
在所有指标下相对于正、负理想方案的后悔效用距离进行集结。
 , (32)
, (32)
 , (33)
, (33)
其中,wj为指标Cj的权重,并满足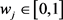 ,
, ,且
,且 。
。
步骤7. 利用式(34)计算各备选地点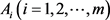 相对于正理想方案的相对贴近系数。
相对于正理想方案的相对贴近系数。
 。 (34)
。 (34)
步骤8. 按照相对贴近系数Ri由大到小的顺序对所有备选地点 进行排序,从而选择出最佳的前置仓备选地点。
进行排序,从而选择出最佳的前置仓备选地点。
4. 算例分析
为了及时有效地将生鲜产品配送到顾客手中,提高物流服务水平,某电商公司拟在某顾客密集区域建立一个前置仓。管理部门邀请10位决策者 采用服务水平(C1)、周边交通情况(C2)、政策优惠(C3)3个评价指标对4个备选地点
采用服务水平(C1)、周边交通情况(C2)、政策优惠(C3)3个评价指标对4个备选地点 进行评价,
进行评价,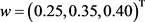 为指标
为指标 的权重向量。决策者
的权重向量。决策者 给出备选地点
给出备选地点 在指标
在指标 上的评价值为
上的评价值为 ,其中决策者
,其中决策者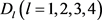 给出的评价值为梯形区间二型模糊数、决策者
给出的评价值为梯形区间二型模糊数、决策者 给出的评价值为影像模糊数,决策者D9和D10分别使用7粒度语言术语集和5粒度语言术语集给出区间语言术语评价信息。本文选择7粒度语言术语集作为基础语言术语集(见图2)。下面采用上面给出的异构群体信息下基于后悔理论的前置仓选址模型对备选地点进行选择。
给出的评价值为影像模糊数,决策者D9和D10分别使用7粒度语言术语集和5粒度语言术语集给出区间语言术语评价信息。本文选择7粒度语言术语集作为基础语言术语集(见图2)。下面采用上面给出的异构群体信息下基于后悔理论的前置仓选址模型对备选地点进行选择。
步骤1. 各个决策者分别依据自身偏好的信息表达形式给出其评价信息,构成异构决策矩阵
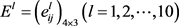 。以备选地点A1在不同指标下的异构评价信息为例,各决策者给出的评价信息如表1~3所示。
。以备选地点A1在不同指标下的异构评价信息为例,各决策者给出的评价信息如表1~3所示。

Table 1. Trapezoidal interval type-2 fuzzy evaluations of feasible location A1 provided by decision maker
表1. 决策者 给出的备选地点A1梯形区间二型模糊评价信息
给出的备选地点A1梯形区间二型模糊评价信息
Table 2. Picture fuzzy evaluations of feasible location A1 provided by decision maker
表2. 决策者 给出的备选地点A1影像模糊评价信息
给出的备选地点A1影像模糊评价信息
Table 3. Interval-valued linguistic term evaluations of feasible location A1 provided by decision maker
表3. 决策者 给出的备选地点A1区间语言术语评价信息
给出的备选地点A1区间语言术语评价信息
步骤2. 利用3.1小节的异构信息转化方法将各个决策者给出的异构决策矩阵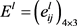 转化为区间二元语义决策矩阵
转化为区间二元语义决策矩阵 。备选地点A1的区间二元语义评价信息如表4~6所示。
。备选地点A1的区间二元语义评价信息如表4~6所示。
Table 4. Interval 2-tuple linguistic transformed from trapezoidal interval type-2 fuzzy numbers
表4. 梯形区间二型模糊数转化后的区间二元语义
Table 5. Interval 2-tuple linguistic transformed from picture fuzzy numbers
表5. 影像模糊数转化后的区间二元语义
Table 6. Interval 2-tuple linguistic transformed from interval linguistic terms
表6. 区间语言术语转化后的区间二元语义
步骤3. 利用式(29)将各决策者给出区间二元语义决策矩阵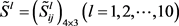 集结为群体区间二元语义决策矩阵
集结为群体区间二元语义决策矩阵 ,如表7所示。
,如表7所示。
Table 7. Group interval 2-tuple linguistic decision matrix
表7. 群体区间二元语义决策矩阵
步骤4. 根据式(30)和(31)确定群体区间二元语义决策矩阵 的正理想方案
的正理想方案 和负理想方案
和负理想方案 ,如下所示:
,如下所示:
 ,
,
 。
。
步骤5. 根据式(28)分别计算在指标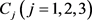 下各备选地点
下各备选地点 相对于正理想方案
相对于正理想方案 和负理想方案
和负理想方案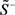 的后悔效用距离,如表8和表9所示。
的后悔效用距离,如表8和表9所示。
Table 8. Regret effect distance from positive ideal solution
表8. 与正理想方案间的后悔效用距离
Table 9. Regret effect distance from negative ideal solution
表9. 与负理想方案间的后悔效用距离
步骤6. 利用式(32)和(33)分别对各备选地点 在所有指标下相对于正、负理想方案的后悔效用距离进行集结,如表10所示。
在所有指标下相对于正、负理想方案的后悔效用距离进行集结,如表10所示。
Table 10. Weighted regret effect distance between each feasible location between positive (negative) ideal solution
表10. 各备选地点与正、负理想方案间的加权后悔效用距离
步骤7. 利用式(34)计算备选地点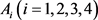 相对于正理想方案的相对贴近系数:
相对于正理想方案的相对贴近系数:
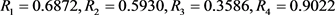
步骤8. 按照相对贴近系数Ri由大到小的顺序对所有备选地点 进行排序,排序结果为
进行排序,排序结果为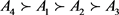 。由此可得,A4为最优的前置仓备选地点。
。由此可得,A4为最优的前置仓备选地点。
5. 结论
为了解决异构信息环境下的前置仓选址问题,本文基于后悔理论提出了面向异构数据的多属性群决策方法。首先,为了处理异构评价信息,提出了将梯形区间二型模糊数、影像模糊数和多粒度区间语言术语统一转化为区间二元语义的方法;然后,考虑到决策者的心理行为,利用后悔效用计算各前置仓备选地点与正负理想方案的距离;并以此为基础,利用TOPSIS法确定各前置仓备选地点与正理想方案的相对贴近度,以实现备选地点的排序及择优。通过算例分析说明所提出方法的可行性,为异构信息环境下的前置仓选址提供了一个新的思路。该方法也可推广到人员绩效评价、服务质量评估、物流供应商选择等领域,具有比较广阔的应用前景和实用价值。
基金项目
教育部人文社会科学研究青年基金(19YJC630107)、对外经济贸易大学中央高校基本科研业务费专项资金资助(20YQ04)、对外经济贸易大学中央高校基本科研业务费专项资金资助(17QN01)。