1. 引言
在处理数据对象时,将数据按组分类成了最广泛的操作。在此过程中,可能会出现两种情况:一种是监督分类,即每个组(或类)由代表类名的标签标识 [1]。另一种则是在没有任何先验知识的情况下得到数据的分组,这样的无监督分类过程称为聚类。聚类的目的是组内对象的相似性最大,组间的相似性最小 [2]。
聚类分析被广泛用于数据挖掘中,因此,大量的聚类算法应运而生 [3]。聚类算法大致可分为基于层次的聚类算法 [4] [5],基于划分的聚类算法 [6],基于密度的聚类算法和基于网格的聚类算法 [7] [8],以及其他类型的聚类算法。其中,模糊c均值算法 [9] 是属于基于划分的聚类算法的一种典型算法,模糊c均值算法(Fuzzy C-Means,简称FCM)是根据隶属度来确定每个数据对象属于某个组别的程度的一种算法,以欧氏距离作为相似性度量,不断迭代更新隶属度矩阵和聚类中心,直至目标函数收敛得到最终的聚类结果。如果把k-means算法称为“硬聚类”算法,那么FCM则是与其对应的“软聚类”算法,其中每个数据样本可以属于多个集群。因其算法设计简单,易实现,且能够获得较优的聚类结果,被广泛应用在生活中的各个方面。
聚类结果的稳定性,成为了聚类质量所要参考的重要的衡量标准。在这种形式下,一些基于博弈论的聚类算法不断地被提出,这些算法提供了一种通过稳定性聚类的概念来解决聚类问题的新方法 [10] [11] [12],这种跨学科的新颖的方法日渐成为众多科研人员关心和研究的对象。基于博弈论的聚类算法可以分为基于合作博弈论 [13] 和非合作博弈论 [14] 的聚类算法。势博弈 [15] 属于非合作博弈的一种特殊形式,因其始终存在纯纳什均衡 [16],从而被广泛地应用到各个领域中。进一步,我们将势博弈的纯纳什均衡看作是一个稳定的聚类,那么,可以解决聚类结果的相关收敛性问题。
随机性选取初始中心可能使聚类结果陷入局部最优且易受到噪点的影响,进而使所得到的聚类结果并不是稳定的聚类。现在,越来越多的科学研究者致力于研究如何优化初始聚类中心的选择。与初始中心相同,本文所提出的算法首先要确定初始聚类的选择方法。该算法结合模糊c均值作为初始聚类,形成一种新颖的基于势博弈的聚类算法,将聚类问题转化为解决势博弈的纯纳什均衡问题。之后,我们给出一个基于最佳响应策略 [17] 的迭代算法来计算公式化势博弈的纯纳什均衡。本文以模糊c均值作为初始聚类,以迭代最佳响应算法快速地计算出势博弈的纯纳什均衡点。在该迭代过程中,我们考虑玩家偏离规则为顺序偏离 [18],由此得到的FS-IBRC算法在两个不同的数据集中测试并实现。
2. 预备知识
2.1. 博弈论
博弈论是现代数学的一个新的重要分支,其研究的主体(称为玩家)是理性的,博弈则是研究玩家之间的相互作用,这种相互作用可能从合作扩展到冲突。玩家的收益仅仅取决于自己所采取的行动策略,还取决于其他玩家所采取的策略。博弈可以用作建模和解决在多个应用领域中遇到的各种问题的框架,其中包括经济,交通,军事战略和生物学等。
现在,我们来定义一般形式的博弈,令P为参加博弈的所有玩家的集合,那么
。令
为第i个玩家的策略集,
为第i个玩家的效用函数,S称为局势,是所有玩家策略集的笛卡尔积。于是,我们有如下定义,
定义2.1 [18] 令G为一般形式的博弈
(1)
·
:表示参加博弈的所有玩家的集合;
·
:表示玩家i的策略集;
·
:表示玩家i所选择的策略;
·
:表示玩家i的对手所选择的策略的组合;
·
:表示玩家i的对手的局势的集合;
·
:表示该博弈的所有局势的集合;
·
:表示该博弈的一个局势;
·
:玩家i的效用函数。
定义2.2 [18] (纳什均衡)局势
是博弈(1)的纳什均衡,如果
(2)
纳什均衡还可以定义为满足(3)式的一个局势
(3)
其中,
是玩家i的最佳响应策略集。
定义2.3 [18] (势博弈–势函数)博弈(1)是势博弈,如果存在一个全局函数
,对每个玩家i,每个
,对所有的
,我们有
(4)
那么,这个全局函数
就是有限博弈(1)的势函数。
性质2.1 [18] 势博弈存在以下性质:
· 势博弈至少有一个纯纳什均衡。
· 每一个最佳响应学习过程都趋于一个纯策略纳什均衡。
2.2. 聚类
考虑n个对象的集合
,其中,每个对象
具有r个属性,那么,
可进一步定义为
。令
是将n个参与者分为k个没有交集的群组的一个结果,即
,且
,在同一个子集里面的所有对象都是相似性准则
下的相似性最大。接下来,我们定义所有分组结果的集合Π,那么我们所研究的数据聚类问题可定义为:
(5)
其中,
是关于
的一个函数表达。
为了方便接下来关于聚类稳定性的证明,下面我们将给出稳定的聚类的定义。
定义2.4 [18] (稳定的聚类)一个聚类结果
,
是稳定的,如果
都是外部稳定和内部稳定的。
·
内部稳定:满足
·
外部稳定:满足
近年来,在聚类分析过程中已经提出众多聚类算法,最经典的就是属于基于划分的聚类算法 [6] 中的k均值算法和FCM,FCM算法在运行的精度上优于k均值算法,在计算速度上也比k均值要快,所以,本文讨论FCM算法与所提出的迭代最佳响应相结合,快速地得出势博弈的纯纳什均衡。
2.3. FCM算法
模糊 均值算法(Fuzzy C-Means,简称FCM)是根据隶属度来确定每个数据对象属于某个组别的程度的一种算法。FCM算法的基本思想是:建立基于隶属度矩阵的目标函数,通过对聚类中心以及隶属度矩阵的不断迭代优化,实现目标函数的收敛,从而实现对样本数据的聚类。
FCM算法的目标函数定义为
(6)
其中,
为隶属度矩阵U的元素,且
。
为聚类中心,且
。m为模糊加权指数,且
,m越大,聚类的模糊程度越高,本文默认m的取值为2。第j个样本数据到第i个聚类中心的欧氏距离为
。
根据拉格朗日乘数法,我们可由(6)式构造出n个限制条件,引入n个
因子,进而可得到
(7)
将(7)式分别对
求偏导,且令倒数为0,可得
(8)
(9)
由(8)式可得
(10)
由(9)式可得
(11)
FCM算法的基本步骤如下
1) 初始化参数:确定聚类的数C,最大迭代次数M,迭代次数
,模糊加权指数
,迭代终止阈值为
;
2) 初始化隶属度矩阵
,且令此时
;
3) 计算聚类中心
,
;
4) 计算并更新隶属度矩阵
,
;
5) 计算目标函数
,
;
6) 直到
,终止。否则,返回步骤(3)。
FCM算法是一种简单高效的聚类方法,已广泛应用于数据分析、图像分割、模式识别等领域。FCM算法相较于k均值算法对分割问题的描述更符合,有更强的灵活性。FCM将“硬聚类”扩展到“软聚类”,其中每个数据样本可以属于多个集群,这样可使数据点尽可能的分配到最佳的类别中,从而减少了后期对其收敛到最优聚类结果的时效,也降低了聚类结果收敛的复杂度。同时,也使得后续的迭代最佳响应算法实现最大的计算价值。这也是本文想要采用FCM算法所得聚类结果作为初始聚类的出发点之一。
3. 聚类是一个策略势博弈
因为一些聚类算法很难保证聚类结果的稳定性,所以,本节提出基于博弈论的聚类模型,并给出一个效用函数,用来证明势函数的存在性,因此保证了纳什均衡的存在,它是一个稳定的聚类。
3.1. 基于博弈论的聚类模型
首先,我们给出一个数据集
,每个对象
具有r个属性,那么,
可进一步定义为
。我们的目的是将这些数据分成提前定义的k个分组,即
,令
对应这k个分组的质心。
我们将
看作是博弈中的第i个玩家。令
是n个玩家的集合,P中每个玩家都有选择继续留在该群组或者迁移到其余群组的权利,由此可知,玩家i的所有策略的集合就是所有群组的集合,即
,
。
局势
,我们定义玩家i的效用函数为 [18]:
(6)
·
为
的质心。
· d是测量玩家之间相似性的距离函数,这里我们用欧式距离来度量。
3.2. 聚类是势博弈
我们将聚类公式化为非合作博弈G(1)所示,G是n个玩家进行的非合作策略形式的博弈,它的解叫做纳什均衡。
定理3.1 [18] 基于非合作博弈模型(1)的聚类是势博弈。
证要证效用函数
满足
(7)
为势函数。即证对任意
,使得
成立。令
,为不失一般性,我们任意给出其中两个群组
和
,且
。令
分别为
的质心,A为X的玩家,但通过效用函数(6),玩家A会从X迁徙到Y,进而群组将更新为
,质心更新为
。由此,
其中,
,
。
计算得,
因此,在效用函数为(6)式的前提下,
为势函数。
性质3.1 [18] 势博弈G的每个纯纳什均衡
,对应于稳定的聚类结果。
4. 关于博弈(1)的纳什均衡
本节讨论聚类算法中初始聚类在整体算法过程中有不可忽视的重要性,并给出博弈(1)的求解过程,提出迭代最佳响应聚类算法,将FCM与文献 [18] 提出的顺序迭代最佳响应聚类算法(Sequential iterative best-response clustering,简称S-IBRC)相结合,得出FS-IBRC算法,将其与S-IBRC算法在两个不同的数据集上实验并比较。
4.1. 初始聚类的重要性
在众多传统聚类算法中,随机性选取初始中心可能使聚类结果陷入局部最优,且所得到的聚类结果并不是稳定的聚类。例如传统的k-means算法,所得的聚类结果缺乏稳定性。现在,越来越多的科学研究者致力于研究如何优化初始聚类中心的选择。与初始中心相同,本文所提出的算法首先要确定初始聚类的选择方法。结合文献 [18] 中将一般初始化和k-means算法分别作为初始聚类,进而比较各自的聚类结果和运行时间的思想。那么,在本文中,将给出一种将FCM作为初始聚类的基于势博弈的算法(算法4.1),并与一般初始化作为初始聚类的基于势博弈的聚类算法(算法4.2)的运行时间相比较,从而证明FCM算法作为初始聚类在时效上的优越性。
4.2. 基于一般初始化的S-IBRC算法
基于一般初始化的S-IBRC算法可以分为以下几步:
算法4.1
第一步一般初始化
输入包含n个对象的数据集
,
,输入k,k为将O分为k个群组,然后从O中随机选择k个对象作为质心
,若
,则
属于
。接着,根据
(8)
更新质心
。最后输出初始聚类
和质心
。
第二步初始聚类
对应局势s
输入包含n个对象的数据集
,
,输入k,k为将O分为k个群组,然后输入初始聚类
和第一次更新质心
。在博弈(1)中,
,令
是博弈(1)的一个局势,对应于初始聚类
。
第三步顺序迭代最佳响应聚类
重复以下过程:
初始化状态为false,即假设没有玩家i会迁移到别的群组。从玩家
开始到
结束过程:
若
,则从
中随机选择一个策略
,
,随后更新局势为
,
,接着根据关系式(8)更新质心
和
。且状态更新为true,即代表有玩家发生迁移。
直到初始状态false不会改变终止。
输出最终聚类结果C。
4.3. FS-IBRC算法
基于FCM算法作为初始聚类的FS-IBRC算法可以分为以下几步:
算法4.2
第一步初始化
输入包含n个对象的数据集
,
,输入k,k为将O分为k个群组,根据FCM算法得初始聚类
和质心
。
FCM算法的基本步骤如下
1) 初始化参数:确定聚类的数C,最大迭代次数M,迭代次数
,模糊加权指数
,迭代终止阈值为
;
2) 初始化隶属度矩阵
,且令此时
;
3) 计算聚类中心
,
;
4) 计算并更新隶属度矩阵
,
;
5) 计算目标函数
,
;
直到
,终止。否则,返回步骤(3)。
第二步初始聚类
对应局势s
输入包含n个对象的数据集
,
,输入k,k为将O分为k个群组,然后输入初始聚类
和质心
。在博弈(1)中,
,令
是博弈(1)的一个局势,对应于初始聚类
。
第三步顺序迭代最佳响应聚类
重复以下过程:
初始化状态为false,即假设没有玩家i会迁移到别的群组。从玩家
开始到
结束过程:
若
,则从
中随机选择一个策略
,
随后更新局势为
,
,接着根据关系式(8)更新质心
和
。且状态更新为true,即代表有玩家发生迁移。
直到初始状态false不会改变终止。
输出最终聚类结果C。
5. 实验评估
为进一步探讨S-IBRC和FS-IBRC算法的性能,本节将对两个不同的数据集上进行一系列的实验。并将这两个算法的实验运行时间进行比较。以上实验均以python语言实现,并在2.50 GHz Intel Core i5-7200U,4Go RAM上进行。
5.1. 数据集描述
在我们的实验中,所使用的数据集 [19] (Iris, Ecoli)表1将给出以上数据集关于数量n,属性个数r,划分组数k的描述。
5.2. 实验结果描述
为了检查提出的算法S-IBRC和FS-IBRC的相应计算时间,我们将算法均在相同的数据集和相同的计算机运行环境中进行。得出的实验结果通过表2和图1来反映,通过观察可知,算法FS-IBRC在数据集Iris上运行时间与算法S-IBRC几乎相同,而在数据集Ecoli上,FS-IBRC算法的运行时间比算法S-IBRC快很多,这可能与数据集的个数和维度相关。

Table 2. CPU time description (seconds)
表2. CPU时间描述(秒)
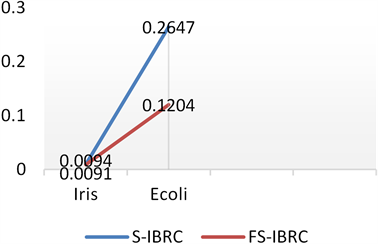
Figure 1. CPU time comparative results
图1. CPU时间比较结果
6. 结论
本文研究了基于势博弈的聚类算法,提出了一种新颖的以模糊c均值作为其初始聚类的基于势博弈的聚类算法,将聚类任务转化为寻找势博弈模型的纯纳什均衡,且证明其对应于稳定的聚类。进而给出了解决这种基于势博弈模型的聚类算法,即迭代的最佳响应算法。将所提算法在两个不同的人工数据集上实现和测试,将该算法的运行时间与一般初始化的算法相比较,实验证明了所提出算法的可行性。近年来研究基于博弈论的聚类算法的文章逐渐增多,除了本文研究的关于势博弈的聚类算法,认为聚类过程就是势博弈,进而求得相应的聚类之外,我们还可以考虑一般的基于非合作博弈的聚类和基于合作博弈的聚类,这些都是比较新颖的算法,通过研究博弈论的均衡性,求得相关的稳定的聚类。在未来的工作中,我们除了研究改进本文所提出的算法之外,还可以研究一些相关定理的推论及其证明,进而获得更多的比较有趣的算法,并在更多的数据集上实验。