1. 绪论
外汇储备的严重短缺是我国关注的重点。随着我国的外汇体制改变了之后,它的规模在逐渐地扩大,其成效显而易见。但外汇储备的过多会引起许多缺点。因此,合适的外汇储备规模就很有必要。
高嘉敏 [1] 对外汇年度数据建模,运用对中国1950~2008年的变动趋势分析,对未来做出预测。褚晓飞 [2] 对我国的1981年以来的外汇数据进行建模,提出了几条有效的建议。曾悦 [3] 阐述了国内使用外汇储备在外投资的风险,提出了一系列针对性的建议。韩继云 [4] 讲述了近几年中国外汇储备增长的原因,针对这种现状,他提出了几项管理措施。
本文从中国外汇储备当前状况开始,先讲述中国外汇储备的局面和其机制,讨论其存在的短板,然后运用时间序列分析对我国外汇储备进行建模、检验和预测,找出外汇储备的适度规模,并分析外汇储备的情况,最后总结模型的优缺点,更好地规划模型。
2. 数据采集、数据来源、统计方法
2.1. 数据采集与来源
本文收集数据来自于东方财富网,网址为:http://forex.eastmoney.com/。由于整篇论文是从中国的外汇储备来进行研究的,论文收集了2008年1月到2017年12月的数据,以亿美元为单位,收集每月的外汇储备数据。
2.2. 统计方法及思想
本论文是通过统计学软件R,采用应用时间序列的统计学方法(王燕 [5] )来对我国的外汇储备进行ARIMA建模、分析以及预测。
使用ARIMA模型对观察序列建模时一件比较简单的事情,它遵循如下操作流程:
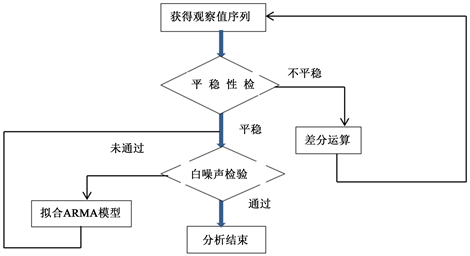
考虑到数据是月度数据,本文从简单季节模型、简单加法模型和季节乘法模型出发,对这三个模型从参数和模型的显著性进行检验,比较这三个模型的优缺点,选出合理的模型做预测。
3. 实证分析
3.1. 平稳性检验
ADF检验:Dickey-Fuller = −1.0173,Lag order = 4,p-value = 0.932。
从图1可以看出,外汇储备从2008年到2014年左右有明显的升高,2014年之后便处于下降趋势。再从ADF检验结果可以看出此序列为非平稳序列,因此需要做适当的处理。由于看出明显的趋势性以及周期性,数据为月度数据,所以可做差分来使其变成平稳序列。
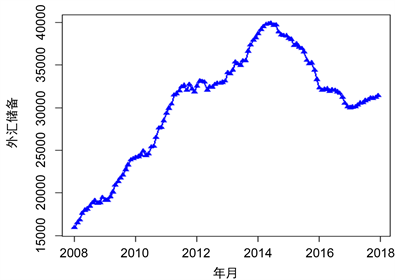
Figure 1. Timing chart of foreign exchange reserves
图1. 外汇储备时序图
3.2. 差分运算
从图2,图3两个图可看出,一阶差分后数据依然呈现波动趋势,而二阶差分后数据就基本接近于平稳了。所以本文采取二阶差分的结果来进行建模和分析。
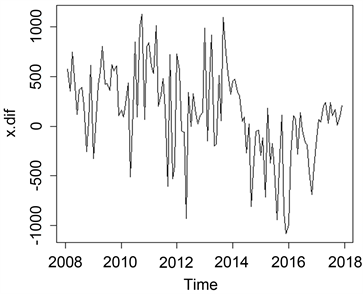
Figure 2. Time sequence diagram of 1 order difference
图2. 一阶差分时序图
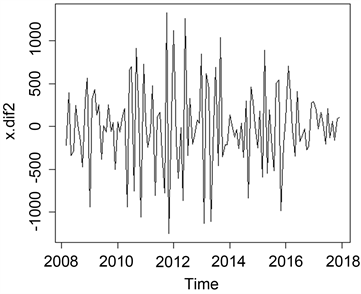
Figure 3. Time sequence diagram of 2 class difference
图3. 二阶差分时序图
3.3. ADF检验
ADF检验是对平稳性的一种检验:
Dickey-Fuller = −11.626,Lag order = 4,p-value = 0.01。
由结果得出,p = 0.01 < 0.05,外汇储备的二阶差分是一个平稳的序列,并且它的均值是常数,该平稳序列2阶自相关,所以根据处理的数据来建立ARIMA模型。
3.4. 二阶差分后的自相关图和偏自相关图
由图4及图5可以得出结论:自相关系数图的一阶自相关系数超出2倍的标准差以外,其余基本上都控制在2倍标准差以内,从偏自相关图很容易看出它基本上为2阶截尾。所以,对这种情况仍然采取自动定阶的方法,得到初定模型为
模型。
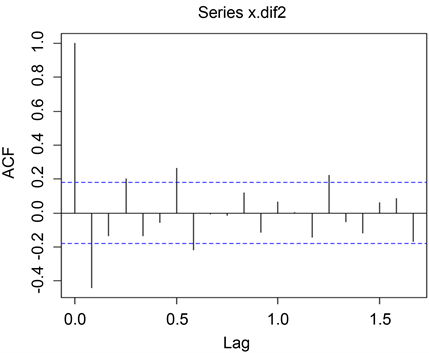
Figure 4. ACF diagrams of 2 order difference
图4. 二阶差分自相关图

Figure 5. PACF diagrams of 2 order difference
图5. 二阶差分偏自相关图
3.5. ARIMA模型
3.5.1. 模型的拟合结果
对差分后的数据进行分析,结果为:
Call:
arima(x = x, order = c(0, 2, 1))
Coefficients:
ma1
-0.7458
s.e. 0.0702
sigma2 estimatedas162165:loglikelihood = −875.63, aic = 1755.25
提取的信息 为0.7458,其中 的值为1755.25,方差的平方为162165。
3.5.2. 模型的显著性检验
Box-Pierce test
data: x.fit1$residual
X-squared = 6.2103, df = 6, p-value = 0.4001
data: x.fit1$residual
X-squared = 13.879, df = 12, p-value = 0.3085
可得延迟期数为6阶时p = 0.4001,延迟期数为12阶时p = 0.3085。两个延迟阶数的p大于0.05,可以说明残差是白噪声序列,所以这个模型是显著的。对于前面原始数据的时序图,发现数据有明显的趋势,于是将考虑是否与周期性有关,将数据进行2阶4步差分。
3.5.3. 2阶4步差分的自相关图和偏自相关图
图6,图7可看出自相关图和偏自相关都是拖尾的,因此我们可以依旧运用模型自动定阶的方法,结果将模型定阶为一个ARIMA关于季节的模型
。

Figure 6. ACF diagrams of 4 order difference
图6. 4步差分后相关图
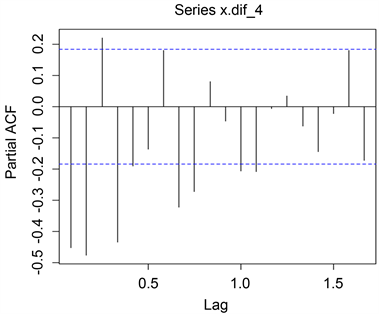
Figure 7. PACF diagrams of 4 order difference
图7. 4步差分后偏自相关图
3.6. 简单加法季节模型
3.6.1. 模型的拟合结果
对于周期性的模型,拟合简单加法季节模型的效果为:
Call:
arima(x = x, order = c(0, 2, 1), seasonal = list(order = c(0, 1, 0), period = 4))
Coefficients:
ma1
−0.9997
s.e. 0.0263
sigma2 estimatedas313925:loglikelihood= −889.47, aic = 1782.95
简单的加法季节模型拟合效果来看,2阶差分后4步差分的关于外汇储备的
模型的AIC = 1782.95,并且方差的平方为313,925。
3.6.2. 简单加法季节模型的显著性检验
简单加法季节模型的显著性检验得出结果为
Box-Pierce test
data: x.fit2$residual
X-squared = 28.454, df = 6, p-value = 7.716e−05
Box-Pierce test
data: x.fit2$residual
X-squared = 35.426, df = 12, p-value = 0.0004005
由结果看出,延迟6阶和12阶延迟期数的p都远远小于0.05,表明此模型不满足显著性检验,因而我们考虑了复杂模型乘法季节模型。
3.7. 乘法季节模型
3.7.1. 模型的拟合
在简单加法季节模型的基础之上,由于自相关图在6阶自相关系数不为0,在12阶基本在2倍标准差范围,偏自相关图的系数都显著非0,可认为相关系数截尾,偏自相关系数拖尾,所以可以进行拟合乘法季节模型
,拟合得出的结果为:
Call:
arima(x = x, order = c(0, 2, 1), seasonal = list(order = c(0, 1, 1), period = 4))
Coefficients: ma1 sma1
−0.7319−0.9983
s.e. 0.0726 0.0561
sigma2 estimatedas165682:loglikelihood = −858.03 ,aic = 1722.06
从上面的拟合结果中得出
,
,方差的平方为165,682,AIC的值为1722.06。
3.7.2. 乘法季节模型的显著性检验
结果为:
Box-Pierce test
data: x.fit3$residual
X-squared = 7.0255, df = 6, p-value = 0.3185
data: x.fit3$residual
X-squared = 13.402, df = 12, p-value = 0.3405
由6阶和12阶的p值分别为0.3185和0.3405,明显均大于0.05,所以,拟合的乘法季节模型
是显著的。
3.8. 模型参数的显著性检验
3.8.1. 简单模型
模型
由它的参数结果为
Coefficients:
ma1
−0.7458
s.e. 0.0702
检验的结果表示为:
,由
知,系数是显著性的。
3.8.2. 简单加法季节模型
由它的参数估计为:
Coefficients:
ma1
−0.9997
s.e. 0.0263
系数显著性检验的结果为:
,
知系数的显著性检验的结果可知简单季节加法模型的系数是通过显著性检验的。
3.8.3. 乘法季节模型
参数结果为:
Coefficients:
ma1 ma1
−0.7319−0.9983
s.e. 0.0726 0.0561
检验结果表示为
和
其中
和
,由二者的p值明显小于0.05,该系数是显著的,即乘法模型的显著性检验通过。
3.9. 模型总结
对于上面的三个模型的系数显著性检验和模型的显著性检验我们得出的结论是见表1。
对于三个模型,根据模型显著性检验和AIC原则,由AIC越小的越好,从上述可以知道,从这三个模型中AIC原则上初次观察为三个AIC值几乎相差不大,精确的AIC值为:加法季节模型
简单模型
乘法季节模型
,再从模型的显著性来看,知道简单季节是没有通过显著性检验的,所以从AIC、模型显著性和系数显著性这三方面来看,比较合适的模型为简单模型
和乘法季节模型
。
3.10. 模型的方程表达式
3.10.1. 简单模型
其中
得出模型的表达式为:
3.10.2. 乘法季节模型
模型
由参数估计的结果为:
得到模型的表达式为:
3.11. 简单加法季节模型的修正
对于简单的加法季节模型,检验它的残差是否满足回归模型。
3.11.1. 对模型进行DW检验
检验的结果为:
,
,
,且
,这说明残差序列是高度正相关的。所以,残差序列进行信息进一步的提取。
3.11.2. 自相关图和偏自相关图
从图8看出自相关系数前面的3和4阶是超出2倍标准差以外的,所以便判定为残差序列的自相关图是4阶截尾的,图9的偏自相关图可以看出偏自相关系数基本上控制在2倍标准差以外,因此拟合MA(4)。
3.11.3. 拟合
模型
Call:
arima(x = x.fit2$residual, order = c(0, 0, 4), include.mean = F)
Coefficients:
ma1 ma2 ma3 ma4
0.25380.27450.3034−0.7173
s.e.0.07500.09940.08450.0881
sigma2 estimatedas160760:loglikelihood = −894.78, aic = 1799.55。
3.11.4.
模型的显著性检验
Box-Pierce test
data: r.fit$residual
X-squared = 5.5248, df = 6, p-value = 0.4785
data: r.fit$residual
X-squared = 12.233, df = 12, p-value = 0.4272。
3.11.5.
模型系数的显著性检验
MA(4)模型的显著性检验通过,所以我们对修改后的简单加法模型为:
3.12. 利用简单模型
和乘法模型
模型的预测与分析
运用上面得到的两个模型对今年2018年1月到5月的外汇储备进行预测,再与收集得到的真实值进行对比,得出的结果见表2和表3:

Table 3. Multiplication season prediction
表3. 乘法季节模型预测
两个模型的预测图为图10,图11:

Figure 11. The predictions of multiplication season
图11. 乘法季节模型预测图
从上面的两个模型的预测时序图可以看出,大体上看二者没有多大的区别,下面用精确值来分析判断哪个模型预测的更精准一些:
表4很容易得出两模型对2018年1月到5月年预测值,简单模型的预测值和乘法季节模型预测的对比来说,乘法季节模型的预测值要普遍的偏向真实值,而简单模型要比真实值略有偏高,从而我们可以认定乘法季节模型
比简单模型
更加适合来拟合外汇储备这个模型。从中可以看出简单模型不能提序列的复杂关系,而季节模型可以很好的提取这些信息。因此,对我国以后的外汇储备,我们可以采用乘法季节模型进行预测和分析。
4. 总结
4.1. 模型的优点
本论文从东方财富网站上收集得到的数据具有真实性与可行性,在文章中,我们对外汇储备的数据进行了在月度数据上的简单建模,以及从它的周期性上采用了加法和乘法季节模型对它进行再次的建模,从AIC最小原则以及模型和系数的显著性检验是否显著这两个条件上来选择了较好的两个模型,用选择的模型做出短期的预测和实际得到的数据进行对比选择出最好的模型是乘法季节模型,它对于我国未来的外汇储备增长和缩小具有比其他两个模型更好的精准性。
4.2. 模型的缺点
此课程设计也具有它的一定的不足之处,首先从本文中看我们对收集得到的原始数据具有明显的趋势效应,为了可以充分地提取原序列中的非平稳确定性因素,我们在文中采取了二阶差分,由于每次的加工都会避免不了使得信息得损失,所以二阶差分后的数学模型降低了估计的精确度。其次是从外界来看,单一的外汇储备模型还不足以预测我国未来的外汇储备增长情况,我们查询资料得知,许多的因素会直接影响到外汇储备。比如:我们国家每月的GDP数量、每月的外商直接投资数量、货币效应增长率以及居民消费价格指数。在本论文中没有考虑进去,从而也降低了未来预测估计值的精确度。最后,从2014年到2018年我国的外汇储备状态上来看,外汇储备的输出在减少,所以我们应该采取一些必要的措施来避免这种现象。
NOTES
*通讯作者。