1. 引言
证券市场在现代社会中发挥着重要作用,并且影响着国家的经济发展 [1]。一直以来,对证券市场收益预测的研究是金融统计研究领域的热点问题,寻找影响证券投资收益的因素并分析这些因素的作用对提高证券投资效率与防范市场风险具有十分重要的理论与实际意义。特别是,近十年来,相关研究得到金融工程和统计领域的广泛关注 [2]。
分析和预测证券市场行为的两种常用方法是基础分析和技术分析。这两种方法的主要目标都是依据已有的证券市场信息预测其未来走向及数值。前一种分析是依据影响市场走势的经济因素,如公司经营数据等,它较适合于长期的预测。而技术分析主要依据证券市场的交易数据去分析预测市场未来的变化 [3],一般依据多个技术指标,对某只股票或市场指数的历史数据进行整理和分析,从而预测该金融资产的未来价值。
近来,人工智能(AI)在各个领域获得了极大成功 [4],其被认为是解决许多金融问题的有力工具,如利用人工神经网络 [5] [6] [7]、决策树(DT) [8] [9] [10] [11]、深层神经网络 [12]、梯度树(GBDT)、随机森林(RF) [13] 和CART树 [14] 等,对股票进行分类或预测,取得了不错的预测效果。尽管中国股市已经发展了几十年,但与股票回报相关的特征研究仍显不足。因此,借助于机器学习来说明证券收益及其潜在影响因素之间的关系是很有价值的。为了对股票进行预测,本文通过使用CART分类回归树和多因子模型,通过基本分析面和技术分析相结合研究证券市场的预测及其应用。首先依据Fama和French因子分析方法选取了8大类指标给出了因子得分,其次利用因子分析法提取了五个重要因子,并分析其市场意义,最后根据提取的市场特征及其市场技术指标建立了预测市场季收益率的CART分类回归树模型,并进行了仿真模拟投资。
论文组织如下:第二部分是数据及其处理方法,第三部分是数据建模,第四部分是预测结果及其分析,第五部分给出了模拟投资结果,最后是结论。
2. 数据预处理
2.1. 数据来源
本文选用的数据来自锐思数据库,选择上海交易所从2002年12月31号到2019年12月31号的200家公司季度财务数据和交易数据。文章选取了32个变量,其中31个候选因子,选取股票的市场投资的季收益率作为目标变量,即预测变量。所选的候选因子包括8类指标,有每股指标,盈利能力,偿债能力,成长能力指标,营运能力指标,现金流量指标,资本结构指标和价值指标。具体候选因子见表1:
2.2. 数据处理
在获取数据中存在空缺值,数据量纲不统一等问题,为此对其进行预处理,以便模型的预测。数据预处理的方法包括缺失值处理和归一化处理。缺失值处理是用前后两个值的平均值进行填充。归一化处理的公式如下:
其中
是第i行第j列的真实值,
分别是这一列的最小值和最大值。
2.3. 因子得分
由Fama和French的多因子模型,因子得分是根据因子收益率沿着一个或者多个因子的维度,将股票分成不同的部分,根据这些维度计算出整个市场不同部分的收益率,其差值即为因子得分。
2.3.1. 五因子得分
Fama和French五因子的因子得分计算过程如下(以市值因子SMBt为例):
根据Fama-French [2] 中所使用的2 × 3方法构建因子,沿着两个因子维度,将股票分为2 × 3 = 6个组合。其中一个因子固定为规模,按照中位数分为两层,另外一个为BP (账面市值比)、OP (营运利润率)或者INV (投资风格),按照30%、70%分位点分为3层。具体构建步骤如下:
1) 按股票市值的中位数把全体股票分成小市值(S)和大市值(B)两组。
2) 按账面市值比的30%和70%分位点把样本分成高(H)、中(N)、低(L)三组,将两个指标交叉,可把全体分成SH,SN,SL,BH,BN,BL共6个组合。
3) 用同样的方法,以营运利润率和投资风格代替账面市值比,用稳健(R)、集中(N)、较弱(W)来划分盈利能力、用保守(C)、居中(N)、激进(A)来划分投资风格,可把全体分为12个组合。SR,SN,SW,BR,BN,BW和SC,SN,SA,BC,BN,BA。
4) 计算上述各组合每一期的市值加权平均季收益率,接着计算因子得分,具体公式如表2。
估值因子HMLt、盈利因子RMWt和投资因子CMAt构建方法类似市值因子,公式如表2。

Table 2. Five-factor calculation method
表2. 五因子计算方法
2.3.2. 本文选取的31个因子得分
与Fama-French五因子得分计算原理相似,不同之处是五因子是从两个或两个以上维度来计算因子得分,而这31个因子的得分是从一个维度来计算的,下面以净资产收益率(ROE)为例说明因子得分的具体计算步骤:
1) 按净资产收益率的30%和70%分位点把样本分成高(H)、中(N)、低(L)三组,可把全体公司分成H, N, L共3个组合。
2) 计算上述各组合每一期的市值加权平均季收益率,高组的市值加权平均季收益率减去低组的市值加权平均季收益率,具体公式如下:
同样的步骤和方法计算每一季度的其他30个因子的得分。计算公式如下:
2.4. 筛选因子
为减轻模型的复杂度,根据Fama-French多因子分析方法 [15] [16],按照规模–估值,规模–盈利,规模–投资三种维度将所有股票分成3个5 × 5宫格的资产组合,每一个宫格内股票的季收益率都会形成一个时间序列,把它作为回归的因变量,由2.3.2计算出来的31个因子得分也是时间序列,以它们分别作为回归的自变量,做一元回归,利用回归的t,p值筛选因子。
1) 按照规模–估值筛选
我们构造了规模–估值的5 × 5宫格的资产组合,其时间序列作为因变量,构造的31个因子的得分时间序列作为自变量,对25个宫格的时间序列分别对每一个因子进行单因子回归,会得到p值和t值,如果25个宫格的时间序列和某个因子回归得到的p值大于0.05的宫格个数大于90%,则保留该因子,否则剔除该因子,按照规模–估值分组回归得到的t值和p值如表3:
Table 3. The t and p values of factor regression
表3. 因子回归的t,p值
由于因子比较多,表2仅列举了三个因子,根据因子筛选规则,第一个因子给与保留,第二个因子舍去,第三十一个因子也舍去。按照规模–估值筛选最终保留了每股净资产、资产报酬率、资产净利率等12个因子。
2) 按照规模–盈利筛选
同1) 按照规模–估值的筛选方法一样,按照规模–盈利筛选最终保留了营业利润/营业总收入、每股净资产、资产报酬率等13个因子。
3) 按照规模–投资筛选
同1) 按照规模–估值的筛选方法一样,按照规模–投资筛选最终保留了每股营业收入、营业利润/营业总收入、每股净资产、资产报酬率等14个因子。
综上,选取1) 2) 3) 中筛选之后的共同因子作为预测因变量。见表4:
2.5. 因子分析
为了进一步降低模型复杂度,这里选择因子分析继续降维.因子分析是通过减少因子之间的相关性,将高维变量变成低维变量,因子分析的具体步骤如表5:
根据筛选后的12个因子和Fama-French的五因子,对17个因子进行因子分析,得到五个因子,本文选取因子分析后的五个因子,再添加市场因子,一共六个因子对本篇文章进行分析说明。通过因子分析方法得到的五因子旋转矩阵如表6:
表3中做标记的是权重相对于较大的因子,绝对值都超过了0.8。对于第一个因子,每股净资产、资产报酬率、资产净利率、净利润/营业收入、营业利润/营业总收入、营业总成本/营业总收入、营业利润率、等对应的因子权重较大,由于这些因素跟盈利能力指标关联较大,因此可以称之为盈利能力因子,同样的道理可以称第二因子为价值指标因子,第三因子就称为估值因子,第四因子称为偿债能力因子,第五个因子就称为营运能力因子。由此得到五个新的市场特征(因子),它们和市场因子(指数)一起将作为预测模型的选择特征。
2.6. 模型评估
为了对模型的预测结果进行评估,本篇文章选用了MAPE和RMSE来评价模型的预测能力:
其中real是真实值,predict是预测值。
3. 模型
3.1. 多CART分类回归树
这里借鉴集成学习思想,提出多CART分类回归树模型,其基本思想是对不同的特征训练数据重复应用回归树算法,得到多个回归树,然后将这多个回归树预测值进行平均得到一个最终的预测值。结果表明此多CART分类回归树可以明显的提高回归树的预测准确性。
首先来回顾一下回归树的基本概念。回归树是数据挖掘和机器学习领域应用最广的算法之一,它在拟合数据时,先将预测变量X的联合空间划分成互不重叠的J个小区域Rj,称作树的终端节点(或叶子);然后为每一个小区域拟合一个常数
作为这个小区域内响应变量Y的预测值:
因此一个回归树可以表示为:
回归树的两组基本参数是小区域Rj以及小区域上相应的常数
,将其统一记做
,参数估计的标准是:
其中
是损失函数。在回归树中,最常用的损失函数是平方损失函数,
,回归树的参数是使训练样本残差平方和最小的那一组。
为了防止数据的过拟合,回归树应该进行剪枝处理,通过剪枝处理可以提高模型的泛化能力。CART分类回归树的剪枝算法就是从完全决策树的底端减去一些子树,从而使模型变的简单。
本文将建立6棵CART分类回归树,每棵树的分类特征是前面得到的五个因子和市场因子,比如第一棵树是根据第一个因子前两季度的因子得分来预测当季度的收益率,其值也就是
,同样的计算方法用其他五个因子预测当季的 收益率,即
,于是得到最终的预测值T,T的计算方法如下:
3.2. 模型的实现
本文使用因子分析和多CART分类回归树算法来建立预测模。首先利用一元回归对多个财务因子进行分析筛选,得到筛选后的因子之后,并和Famma五因子合并一起进行因子分析,得到新的五因子,加上市场因子共六个因子,由它们作为分类特征,接着根据CART分类回归树算法对季收益率进行预测,然后给出相应的投资策略,对公司进行模拟投资。本文的算法基本思路如图1所示:
4. 实证分析
4.1. 模型评价
根据CART分类回归树模型和因子的构造,最后得到市场及公司的每个季度数据,分别用六个因子中每个因子前两天的数据对季收益率进行预测,接着求平均,得到此因子的预测结果。根据2002年12月31号到2019年12月31号的数据,是随机选取20家公司,分别对每家公司2002年12月31号到2015年12月31号的数据进行训练,剩下的数据进行测试,模型的训练结果由MAPE和RMSE进行评估,得到表7如下结果:
由表2可知,通过基于因子分析与回归树的模型预测得出的结果,RMSE最大值是0.1323,最小值是0.0436;MAPE最大值是0.0830,最小值是0.0411,与以往结果比较,预测模型表现良好。
4.2. 模拟投资
为了更好地说明本文因子构造的合理性,对数据进行预测之后再进行模拟投资。投资过程是:如果投资者有一元人民币,当预测结果(未来投资收益率)大于0,就进行买入;否则,就卖出股票。以下是对20家公司进行的模拟投资,用累计收益和夏普比率对收益和风险进行评价,其中累积收益计算过程如下:
其中
是t时间的季收益率。
夏普比率计算公式如下:
其中
是投资组合的期望收益率,
是无风险利率,
是投资组合的标准差。
20家公司四年的累计收益和夏普比率如表8:
Table 8. Simulation investment evaluation table
表8. 模拟投资评价表
从表5可以看出来,随机挑选的20家股票都能获得相应的收益,四年收益最高达到了7.7510倍,最低也达到了2.9357倍。正如下面几家公司的累积收益和市场收益图展示,如图2,相比于市场收益,本文提出的方法获得的收益要比市场收益高很多,说明本文的方法是可行的。再来看夏普比率,最大值是1.6251,最小值是0.5524,说明相同的风险可以获得较高的收益。
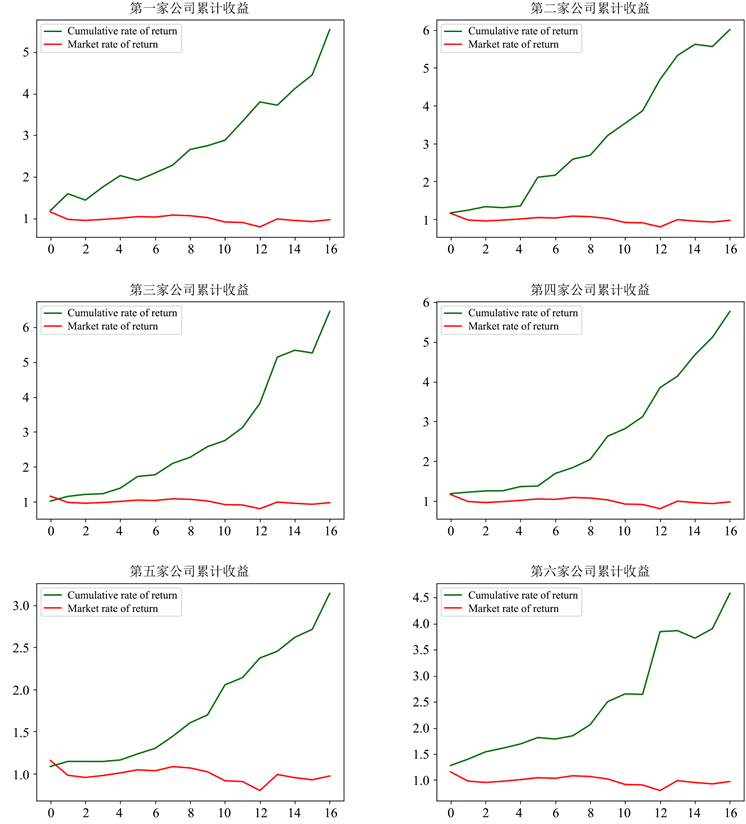
Figure 2. Investment income comparison chart
图2. 投资收益对比图
5. 结论
本文提出了基于多因子得分的CART分类回归树预测模型。首先利用财务数据对市场的影响效果对财务因子进行筛选,得到五个综合反映公司运营状况的五大特征,此五大特征揭示出证券市场不同的波动状态,接着根据市场特征和证券交易的前期收益率建立了多CART分类回归树预测模型,并依据预测结果构造出趋势投资策略,对20家公司进行模拟投资,预测和模拟投资结果都说明本文选用的算法对市场投资有良好的指导作用。