摘要:
命名实体识别(Named Entity Recognition, NER)的定义是从自由文本中识别出属于预定义类别的文本片段(如人名、地理位置名、机构组织名等)。命名实体识别一直是许多自然语言应用的基础,例如问题回答、提取文本摘要和知识库建立。早期的NER系统在实现良好性能方面取得了巨大的成功,其代价是人类工程在设计特定领域的特征和规则方面付出的代价。近年来,非线性处理的连续实值向量表示和语义组合使得深度学习在命名实体识别系统中发挥了很好的作用。在本文中,我们提供了一种基于深度学习的命名实体识别算法。首先我们随机初始化训练集中的每个字特征,并在获取该字典句子中每个字的特征之后,利用周期卷积来得到其固定长度的特征,以此作为句子特征;随后训练数据自动编码器,通过栈式自动编码器得到高层句子的特征;最后通过高层句特征与字特征的组合训练字的标注网络模型来得到未知字的标注值,再进行实体扩展(分类,属性,副标题),最后利用马尔科夫逻辑网络优化整体识别效果。
Abstract:
Named entity recognition is the task of identifying rigid indicators from text belonging to predefined semantic types (such as person, location, organizations, and so on). NER has been the basis for many natural language applications, such as question answering, text summarization and machine translation. Early NER systems had great success in achieving good performance at the cost of human engineering in designing domain-specific features and rules. In recent years, deep learning has been used in NER systems through continuous real-valued vector representations and semantic combinations of nonlinear processing, resulting in the most advanced performance. In this article, we provide an entity recognition technique based on deep learning. Firstly, each word feature in the training set is randomly initialized, and the feature of each word in the sentence is obtained based on the dictionary. Then, the fixed-length feature is obtained by periodic convolution of different length of sentence features, which are used as sentence features. Then the data autoencoder is trained to get the features of high-level sentences through the stack autoencoder. Finally, the combination of high level sentence features and word features is used to train the annotation network model of words, and the annotation value of unknown words is obtained based on the annotation model, and then the entity expansion (classification, attribute, subtitle) is carried out. Finally, the overall recognition effect is optimized by using Markov logic network.
1. 引言
命名实体识别(Named Entity Recognition, NER)定义是从自由文本中识别出属于预定义类别的文本片段,如人名、地理位置名、机构组织名等 [1]。NER不仅是信息抽取的独立工具,而且在各种自然语言处理(NLP)的分支中充当着重要角色,如文本分析、信息抽取,文本摘要生成,问答系统,建立知识图谱等。近年来,深度学习(DL,也称为深度神经网络)被各个领域广泛应用,并取得成功。从Collobert等人开始 [2] [3] [4],基于DL的NER系统,其具有最少的特征工程,正在迅猛的发展。在过去的几年中,NER慢慢引入深度学习,并得到了很好的效果 [5] [6] [7] [8] [9]。这一现象鼓舞我们深入研究NER中的深度学习技术。Nadeau和Sekine [3] 可以说是最成熟的技术,发表于2007年。该论文讲述了从手工制定的规则到机器学习的技术发展趋势。2013年,Patawar和Potey [10] 在2015年进行了简短回顾。最近的两项研究分别涉及新领域 [11] 和复杂的实体提及 [12]。总之,现有的研究主要包括基于特征的机器学习模型,与这项工作更为紧密的是最近的两次调查。在2018年,Goyal等 [13] 调查了NER的发展和进步。但是,它们不包括深度学习技术的最新进展。Yadav和Bethard [12] 根据句子中的单词表示,对NER的最新进展进行了研究。这项研究主要技术是输入的分布式表示形式(例如,字符级和单词级嵌入),而不是采用查看上下文编码器和标签解码器。在本文中,首先我们随机初始化训练集中的每个字特征,并在获取该字典句子中每个字的特征之后,利用周期卷积来得到其固定长度的特征,以此作为句特征;随后训练数据自动编码器,通过栈式自动编码器得到高层句子的特征;最后通过高层句特征与字特征的组合训练字的标注网络模型来得到未知字的标注值,再进行实体扩展(分类,属性),最后利用马尔科夫逻辑网络优化整体识别效果。
2. 命名实体识别研究历史
对英文文本的实体识别的研究领先于中文文本命名实体识别的研究,早在1991年,Rau在第七届IEEE人工智能应用会议上,发布了一个实体识别系统,该系统可以抽取出文本中的公司名称 [14],在当时引起了轰动。从此命名实体识别就开始被引入MUC-6 [15],MUC-7的MET-2 [16] 等一系列会议中。在20世纪90年代初期,孙茂松等 [17] 开始研究中文命名实体识别,最开始研究的范围比较窄,仅仅是对文本中的人名进行识别。而后张小衡等 [18] 开始扩大实体识别的范围,建立了高校名数据集,并采用人工规则进行了实验,完成了对文本中的组织机构名称的抽取。2000年,ZHANG, ZHOU等 [19] 在ACL会议上发表了一个抽取命名实体及它们之间关系的系统。在算法方面,命名实体识别最早期的方法是基于规则,基于字典。后来发展成传统机器学习的方法,比如CRF。经过专家们的不断努力,实体识别引入了深度学习的方法,比如RNN-CRF, CNN-CRF等模型 [20] [21] [22] [23] [24]。
3. 关键技术
3.1. 字词结合向量
3.1.1. 字特征向量
基于字特征向量的模型缺点是单独输入字符,并没有考虑到相邻字符,句子,段落之间所存在的语义关系。其模型结构如图1所示,在最开始的时候字向量公式为
将字符序列
,输入Lstm-CRF模型中。每个字符
用第一个公式表示,
表示字符嵌入查找表,即计算字向量的操作。一个双向LSTM应用于
,可以得到双向lstm的两个方向隐含层的输出,即分别在从左到右和从右到左的方向上的两组不同的参数。根据第二个公式将其参数进行合并,得到的就是第j个字符的输出,再将其输入CRF中。2017年,CHEN [25] 等人改进了该模型
如公式三所示
在计算输入向量的时候把这个字的向量和下一个字符的向量进行了合并,以此来加强字符间的语义关系。

Figure 1. Character feature vector model structure
图1. 字特征向量模型结构
3.1.2. 词特征向量
词特征向量类似字特征,它需要词嵌入来表示每个词,其模型结构如图2所示,公式如下:
该模型用了两层LSTM,第一层是公式七中计算每个词所有字向量的输出。第二层双向Lstm用来学习隐藏状态
,len(i)表示wi中的字符数。公式中
表示第i个词最后一个字的正向的隐含层h;
则表示第i个词第一个字的反向的隐含层h [26]。
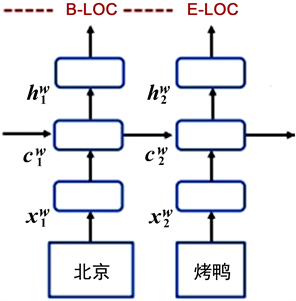
Figure 2. Word feature vector model structure
图2. 词特征向量模型结构
3.1.3. 字词结合特征
单词–字符格模型可以看作是基于字符的模型的扩展,集成了基于单词的单元和用于控制信息流的其他门。其模型结构如图3所示,模型的输入是字符序列
以及与词典D中的单词匹配的所有字符子序列。该模型涉及四种类型的向量,即输入向量,输出隐藏向量,单元向量和门向量。作为基本组成部分,字符输入向量用于表示每个字符
,该模型的基本递归结构是使用字符单元向量
和一个隐藏元素构造的每个
上的向量
,其中
用于记录从句子开头到
的循环信息流,
用于进行CRF序列标记 [27]。该模型公式如下:
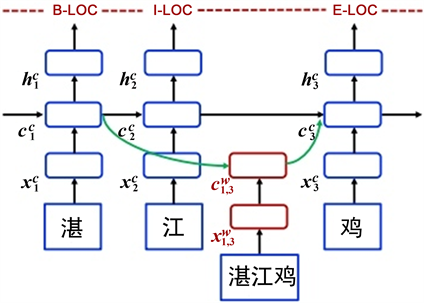
Figure 3. Lattice feature vector model structure
图3. 单词–字符格模型结构
3.2. 实体扩展
本文制作了中国地理特产数据集,实体扩展是指针对某一实体类别比如梨,给出了香梨,鸭梨等种子实体,输出是梨这个类别里其他未知实体,比如雪花梨,水晶梨等。本文采用的是实体扩展方法是基于模板的实体抽取,我们的目标实体(雪花梨,水晶梨)与种子实体(香梨,鸭梨)同属于梨这个语义类,首先我们预定义好指示上下文关系的语义模板,再分析种子实体(香梨,鸭梨)所处的上下文得到模板,然后基于Booststrapping策略,反复迭代,得到更多的种子模板,以模板为特征,计算候选实体的置信度。
3.3. 马尔科夫逻辑网络(MLN)优化整体识别效果
马尔科夫逻辑网络是一种统计关系学习模型,之所以引入该网络,是因为我们的模型针对我们的实体,从分类属性方面进行了扩展,但是这两个方面的扩展是相互独立的,所以我们在扩展之后,引入了马尔科夫逻辑网络来提高我们实体识别的精确度。我们将模型得到的规则转化为子句的集合,将每一个子句看成一个节点,而每个集合中子句的关系即为连边,至此我们就构成了马尔科夫逻辑网。其概率计算的公式如下:
这个公式中,
是某一个规则
的取值为真的时候所对应闭规则的个数。如果我们的规则权重越大,那么必然
就会越大,也就说明我们所取的x在
下越可信。然后我们把当前取值x在所有规则下的可信度相乘,再除以归一化因子,就得到了当前取值的概率 [28] [29]。
4. 实验结果分析
4.1. 实验数据
本文人工构建了一个中国地理特产介绍的命名实体识别数据集,我们的中国地理特产数据集包括训练集,开发集,测试集,训练集里有34906个字,开发集里有4396个字,测试集里有4768个字。
4.2. 实验环境
本研究中的实验环境为ubuntu16.04操作系统,Python3.6,深度学习框架为Pytorch1.4.0。
4.3. 实验设计与结果
本文模型主要识别中国地理特产网数据集中的特产名,地理位置名以及组织机构名,为了验证本文模型的性能,我们设计了三个实验,主要模型为Lattice LSTM-CNN-CRF,而对比实验模型我们用了LSTM-CNN-CRF模型和BiLSTM-CNN-CRF模型,本文实验结果是从准确率、召回率和F1值三个方面来进行。见下表1。
5. 结束语
在本文中,首先我们随机初始化训练集中的每个字特征,并在获取该字典句子中每个字的特征之后,利用周期卷积来得到其固定长度的特征,以此作为句特征;随后训练数据自动编码器,通过栈式自动编码器得到高层句子的特征;最后通过高层句特征与字特征的组合训练字的标注网络模型来得到未知字的标注值,再进行实体扩展(分类,属性),最后利用马尔科夫逻辑网络优化整体识别效果。
基金项目
《工业过程数据实时获取与知识自动化》,国家自然科学基金委员会资助项目,项目编号:U17012621006336。