1. 引言
近年来中国电影业发展迅速,但国产电影票房收入在总票房中占比不大,国产电影想要在国际电影市场占有一席之地仍需更大的努力,分析影响电影票房的因素,预测电影票房,提高电影质量势在必行。2014年杨威 [1] 使用新媒体微博数据作为研究对象,利用神经网络方法建立票房预测模型,并与支持向量机模型和线性回归模型进行预测精度对比,结果表明神经网络模型准确度高于其他模型。2017年张雪 [2] 使用多元线性回归、BP神经网络和卷积神经网络建立票房预测模型,结果表明 [2]:多元回归模型预测效果精确度较低,BP神经网络和卷积神经网络预测效果都比回归好。2018年郭萱 [3] 针对2014~2016年173部国产电影采用随机森林方法进行电影票房影响因素分析,兼顾数值预测方法与分类预测方法提供合理的电影票房预测方案。2019年鲁月 [4] 基于随机森林构建票房组合预测模型并与基于BP神经网络、k-均值 [4] 和局部BP神经网络的国产电影票房预测模型进行对比,结果表明基于随机森林因素筛选的国产电影票房组合模型在一定程度上提高了票房的预测精度。
随机森林方法提出至今,已经被广泛应用于机器学习、生物医学、生物信息学和数据挖掘等众多领域。该方法不仅可以进行分类和回归预测,同时可以给出变量重要性排序 [5]。相比于参数模型中假设较多,参数估计数值不稳定的问题,随机森林方法可以更好地解决噪声问题以及数据中的异常值问题、能更好地对大规模数据进行处理 [6]、具有良好的解释性及学习过程快速。本文采用随机森林方法对国产电影票房影响因素进行分析,并对2019年12部影片的票房进行预测。首先根据问题实际背景给出七个影响国产电影票房的因素,分别为:档期、是否有续集、首映日票房、点映票房、首周末票房、百度指数和豆瓣评分。基于2014~2018年225部影片的相关数据,采用随机森林方法建立回归模型,得到影响国产电影票房的主要因素并给出2019年12部影片电影票房的预测值和预测误差。同时采用电影票房领域应用较多的神经网络方法和线性回归方法对2019年12部影片进行预测。将随机森林预测结果与神经网络和线性回归模型预测结果进行对比分析。在变量选择方面随机森林具有一定的优势,在预测方面随机森林方法比其他两种方法更为精确。
2. 随机森林方法介绍
随机森林是机器学习算法之一,由多个决策树分类器组合而成。随机森林 [7] 的基本思想是每次随机选取一些特征,独立建立树,重复这个过程,保证每次建立树时变量选取的可能性一致,如此建立许多彼此独立的树,最终的分类结果由产生的这些树共同决定。将分类树替换成回归树,把类别替换为每个回归树预测值的加权平均,就可以将随机森林树转换成随机森林回归算法。随机森林流程图如图1所示。
2.1. 随机森林算法
随机森林算法为 [8]:
(1) 对于
(a) 通过bootstrap抽样方式产生b个样本子集。
(b) 对每个bootstrap样本建立随机森林树
,每个叶子节点递归地重复以下步骤,直到叶子节点包含的数据量为
为止。
① 从p个自变量中随机选择mtry个自变量。在使用随机森林做回归时mtry默认值为p/3,使用随机森林做分类时默认值为
,其中p为自变量个数。
② 在mtry个自变量中选择最好分裂变量和分裂点。
③ 将节点拆分为两个叶子节点。
(2) 输出集成树
(3) 预测
(a) 对于回归问题,待测样本x的预测为:
(b) 对于分类问题,设
是第b棵树的类预测。
majorityvote为多数票。
2.2. 变量重要性排序
随机森林可以给出变量重要性的排序,其具体过程如下 [9]:
(1) 对每个bootstrap抽取的样本建立一个回归树模型,同时使用该模型对相应的袋外数据OOB(out-of-bag)进行预测,得到B个袋外数据的残差均方,记为
。
(2) 变量
在B个OOB样本中随机置换,得到新的OOB样本,然后用已建立的随机森林模型预测新的OOB样本,得到随机置换后的OOB残差均方如下:
(3) 用
与如上矩阵对应的第i列向量相减,平均后再除以标准误则得到变量
的重要性排序,即
随机森林方法通过在OOB样本中随机地置换变量,计算预测精度下降程度来衡量变量的重要性,其数值越大说明变量越重要。
3. 中国电影票房影响因素及预测的实证分析
3.1. 中国电影票房影响因素指标的选取以及数据来源
本文根据实际问题背景以及数据获取难易程度选择影响中国电影票房的7个因素,分别为:档期、是否有续集、首映日票房、点映票房、首周末票房、百度指数和豆瓣评分。
① 档期:中国电影目前主要有暑期档和贺岁档两大特殊档期,本文将档期分为三类 [10]:贺岁档为每年12、1、2月份;暑期档为每年6、7、8月份;其余月份为其他档期记为第一类。
② 续集:漫威系列电影的成功启示我们是否有续集可能会吸引特定的观众带来源源不断的票房。国内《人在囧途》、《叶问》、《战狼》等影片的成功预示着续集有可能成为影响电影票房的因素。
③ 首映日票房:首映日票房整体上可以反映观众对于一部电影的关注度,可以反映电影上映前电影的宣传效果。《美人鱼》上映当天票房达到2.72亿元,最终票房大卖。发行商可以根据首映日票房进一步明确影片定位,调整营销策略。
④ 点映票房:点映是电影上映前,制作团队在个别城市、个别影院对影片提前放映。点映在好莱坞有半个多世纪的历史,中国电影点映始于张艺谋导演的作品《英雄》 [11]。点映一方面可以满足观众的好奇心,为电影的正式上映积累大量的口碑,另一方面可以通过观众的反馈调整上映期间的场次,适当改变营销方案。
⑤ 首周末票房:电影上映一周的首周末票房可以检验这部电影是否被观众认可,可以为接下来一段时间的排片宣传提供一定的参考。
⑥ 百度指数:百度指数是当前互联网时代重要的统计分析平台之一,是众多企业营销决策的重要依据。百度指数里可以看到以电影名为关键词的搜索量规模大小,电影上映前百度指数是指以该电影为关键词的预告片以及宣传片的搜索量。本文统计了一部电影上映前四周的百度指数,由于搜索量波动较大,选择电影上映前四周的平均百度指数作为研究变量。
⑦ 豆瓣评分:豆瓣电影是中国最大最权威的电影分享与评论社区 [12],电影上映后,观众会通过自己的综合观感在豆瓣电影给出综合评分以及评论。豆瓣评分代表着电影口碑。一部电影的评分会随着上映期间观众的评价不断更新,无法动态收集,本文采用电影上映后的综合评分作为研究变量。
各影响因素指标具体如表1。
根据《艺恩数据》及《中国电影票房数据库》,得到我国2014~2018年上映的225部影片的观测数据,部分数据如表2所示。

Table 2. Some data of 225 films from 2014 to 2018
表2. 2014~2018年225部影片部分数据
进行数据分析前,为了消除量纲以及数据数量级大小的影响,对于数值型变量的观测数据进行标准化处理,即因变量票房,自变量首映日票房、点映票房、首周末票房、百度指数和豆瓣评分标准化处理z分数表示为公式(1):
(1)
表示本组数据的平均数,s表示本组数据的标准差。
3.2. 随机森林模型的建立
建立票房回归预测模型,随机森林模型中有两个参数mtry和ntree,其中mtry表示每一步分裂选择的自变量个数,ntree为随机森林中树的个数,R软件randomforest()函数默认
,p为自变量个数,默认树的个数
,Gareth James等 [13] 指出随机森林里参数取默认值也可以取得较稳健的效果。
模型建立过程:
(1) 对于
(a) 通过bootstrap抽样方式产生500个样本子集。
(b) 对每个bootstrap样本建立随机森林树
,每个叶子节点递归地重复以下步骤,直到叶子节点包含的数据量为5为止。
① 从7个自变量
中随机选择2个自变量。
② 在2个自变量中选择最好分裂变量和分裂点。
③ 将节点拆分为两个叶子节点。
(2) 输出集成树
(3) 预测
对于回归问题,待测样本x的预测为:
3.3. 变量重要性排序
使用上述建立的随机森林模型,可以采用R软件计算得出影响电影票房的变量重要性排序如表3所示。随机森林方法通过在OOB(out-of-bag)样本中随机地置换变量,计算变量重要性。该数值越大,变量越重要,对电影票房的影响越大。
Table 3. Order of importance of variables
表3. 变量重要性排序
通过计算得出的变量重要性排序可知,首周末票房、首映日票房、百度指数、豆瓣评分和点映票房为影响电影票房的重要因素,档期和续集对于电影票房的影响可以忽略不计。R软件中plot()函数可以给出变量重要性排序图,如图2所示。
3.4. 三种方法预测结果比较
除了随机森林模型外,神经网络在分类数据预测方面有较好的效果,线性回归模型是传统的预测模型,这两种方法在电影票房的预测方面都有提及,本文选取2019年12部影片使用三种模型进行电影票房的预测,预测误差定义如公式(2):
(2)

Figure 2. Order of importance of variables
图2. 变量重要性排序
采用三种方法对影片预测数值如表4,影片预测对比折线图如图3,影片预测误差如表5。
Table 4. Box office estimates for 12 films in 2019
表4. 2019年12部影片票房预测结果
表中可以看出,随机森林回归模型显示出良好的预测精度。影片的预测误差多在20%左右。神经网络和线性回归模型对于部分影片的预测误差较小,但其预测误差范围较大,对某些影片的预测误差太大。12部影片中,随机森林对电影《银河补习班》的预测误差达到0.81%,对电影《熊出没原始时代》的预测误差为2.54%。说明随机森林选择出的影响电影票房的重要因素,首周末票房度、首映日票房、百度指数、豆瓣评分和点映票房是决定这两部影片总票房收入的重要因素。
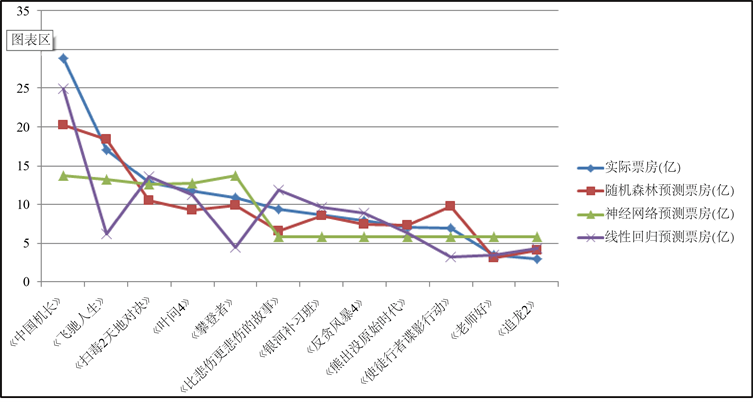
Figure 3. Line chart of box office predictions for 12 films in 2019
图3. 2019年12部影片票房预测结果折线图
Table 5. Box office error for 12 films in 2019
表5. 2019年12部影片票房预测误差
电影《银河补习班》2019年7月18日上映,总票房8.78亿元,首周末票房2.70亿元,首映日票房0.65亿元,上映前四周平均百度指数52717.5,豆瓣评分6.3分,点映票房0.99亿元。电影《熊出没原始时代》2019年2月5日上映,总票房7.18亿元,首周末票房1.90亿元,首映日票房0.74亿元,上映前四周平均百度指数1303.75,豆瓣评分6.7分,点映票房0.40亿元。
两部影片的数据对比表明,首周末票房和首映日票房都取得极大成功的基础上,在2019年同档次总票房收入的影片中,这两部影片有一个共同的特点即点映票房较高。《银河补习班》在上映前多地超前点映,观众的反响和点映现场的效果反馈其不仅在故事发展上吸引观众眼球,人员演技及影片质量同样好评如潮,使得该片的首映日票房和首周末票房取得不错的成绩。但是因为点映效果良好,提高了观众对这部影片的期待,使得其后续豆瓣评分成绩一般。《熊出没之原始时代》有别于《银河补习班》,其不仅是依靠点映票房取得总票房的好成绩,这部影片有续集,连续多年积累了一定的口碑,传播较为广泛,使得其在上映之后取得不错的票房。
故首周末票房、首映日票房、百度指数、豆瓣评分和点映票房对电影票房总收入影响较大,制片方、营销方和院线可以根据影片的实际市场情况,采取合适的营销方式来提高票房收入。
4. 结论
本文依据2014~2018年225部国产电影票房数据,运用随机森林方法对影响国产电影票房的因素进行分析,最终得出影响电影票房的主要因素有首周末票房、首映日票房、百度指数、豆瓣评分和点映票房五个因素,档期以及是否有续集这两个因素对电影票房的影响可以忽略不计。
首周末票房可以检验一部电影的口碑,反映电影的火爆程度以及在后续电影放映中的竞争态势,发行方可根据首周末票房来调整营销策略。首映日票房是电影本身类型、导演、演员类型以及上映前电影宣传情况的一个综合体现,提高首映日票房需要提高电影本身的制作,需要加强电影的宣传。百度指数可以洞察电影上映前观众对影片的兴趣、监测舆情动向、定位受众的特征。提高百度指数多在电影制作拍摄包括电影制作完成后要实时宣传,引起观众兴趣。豆瓣评分会动态影响电影票房,豆瓣评分较高的电影会吸引一部分观众,豆瓣评分较低会让一部分本来要去看电影的观众选择放弃观看。电影点映属于电影宣传环节,点映过程中可以收集观众对影片的初步评价,如果电影有所不足可以调整营销策略弥补电影本身的不足。
在分析影响电影票房因素的基础上,本文采用随机森林模型、神经网络模型和线性回归模型对2019年12部影片进行了预测。预测结果表明,随机森林对于《银河补习班》、《熊出没原始时代》、《反贪风暴4》这三部影片的预测误差在5%左右取得较好的效果,部分影片预测误差较大,但整体来讲随机森林预测票房较为稳健。神经网络和线性回归模型对于部分影片的预测效果良好,针对大部分影片其预测误差波动较大,就本文的研究而言,针对票房数据建立的三种预测模型,随机森林取得良好的效果。
电影票房影响因素分析及预测中,演员阵容、导演、发行商和新浪微博的宣传力度等是否会影响电影票房的收入,如何将这些变量量化纳入模型本文没有提及,有待继续探索研究。