1. 引言
在传统机器学习的分类问题中,总是利用样本的单一视角特征来建立机器学习模型,进而对未知的样本进行预测,该模型也可以称为单视角学习 [1] (Single-View Learning, SVL)。但在现实中和大数据环境下,数据的收集和存储能力得到了极大的提高,在多样化的信息获取技术的推动下,我们总是可以更容易和更便捷的从不同的途径或者不同的方法获得样本,其被称为多视角数据,呈现出多态性和多描述性等特点 [2]。如图1所示,左图含有图像特征和文本描述,文本特征是对图像的一种描述和解释,右图表示不同语种表示你好的多种表现形式。然而,我们可以在多视角数据上构建机器学习模型,这被称为多视角学习 [3] (Multi-View Learning, MVL)。
Figure 1. Schematic diagram of multi-view data
图1. 多视角数据示意图
多视角学习最初由De sa [4] 等人提出,表明模式之间的不同感觉方式可以被看作是多种视角的。这里的“视角”表示来自多个源或不同特征子集的数据。多视角学习的应用被扩展到半监督学习 [5]、监督学习 [6]、降维 [7] 和聚类 [8]。Farquhar等人 [6] 提出将内核典型相关分析和支持向量机链接到一个名为SVM-2K (KCCA followed by Support Vector Machine)的单一优化。Chen等人 [7] 提出了一种新的降维方法,称为半配对半监督广义相关分析,称为semi-paired and semi-supervised generalized correlation analysis (S2GCA),既能保持未标记数据的全局结构,又能找出标记数据的最大可分性。Bickel和Scheffer [8] 发现多视角聚类算法可以改进单视角聚类。尽管在多视角学习中取得了巨大的进步,但多视角学习可能会忽略一些具有内部连接以及不同视图之间存在差异的多视角数据的原始信息。在实践中,我们可能会遇到在训练阶段没有标签的数据,并且它们不同时属于正负类,这被称为Universum数据。Universum数据可以视为其他数据,以提高学习工具的泛化性能。
近年来,国内外研究者对Universum学习也逐渐广泛关注。Vapnik等人 [9] 首先提出了一个新的研究框架,这是一个替代大范围方法的能力概念,以便在学习过程中整合领域信息。Weston等人 [10] 在Vapnik研究的基础上,首先提出了Universum的概念,特别是在二元分类问题中,将一组有标记的样本和一组不属于任何兴趣类别的无标记样本作为输入信息,未标记的样本称为Universum样本。Liu等人 [11] 提出了一种半监督学习算法,利用增强型技术和Universum实例来提高文本分类性能,该算法获取分类函数的先验信息。Richhariya和Gupta [12] 提出了一种基于牛顿法的迭代Universum twin support vector machine (IUTWSVM),该方法利用Universum数据从人脸图像中对人脸情绪进行不同层次的分类。Wang等人 [13] 开发了半监督学习方法,将Universum数据与社交媒体信息相结合称为Semi-Supervised Feature Selection with Universum (U-SSLFS),将Universum样本相结合,使模型更具辨识性。
综上所述,为了解决多视角学习可能会忽略一些不同视角之间存在差异的多视角数据的原始信息,我们引入了Universum数据,提出了一种基于Universum数据的多视角学习方法。使得算法更加正则化,提高了多视角分类器的性能,此外,为每个视角引入正则化项意味着每个视角中都有先验知识。我们工作的主要贡献总结如下:
1) 我们首次提出了一种新颖的算法模型,基于Universum数据的多视角学习算法,以提高多视角学习的分类性能。对于Universum数据,我们首先在每个视角上有相应的特征,考虑原始数据和Universum数据的特征构建超平面,并让Universum数据分布在正类和负类之间,从而得到一个准确的预测分类器。
2) 构造拉格朗日函数讲算法模型转化为对偶问题,求解相应的优化问题。
3) 我们进行了大量的实验来评估我们提出的算法的性能。统计结果表明,提出的算法比现有的方法更能提高分类精度。
2. 基于Universum数据的多视角学习算法
2.1. 目标函数
假设给定相同数据的两个视角,一个视角可以通过相应的内核函数
的特征投影
表示,另一个通过具有相应的内核函数
的特征投影
表示。对于分类任务,每个数据项还应该包含标签 [6]。然后,通过一组给定的配对数据集:
(1)
通过引入Universum数据,我们将多视角学习和Universum数据相结合。假设除了多视角训练数据外,我们还获得了另一组数据,称为Universum数据,该数据是一组不属于任何感兴趣类别的未标记样本,被用作输入信息,一个Universum数据可以表示为
,
,每一个多视角数据都包含一个Universum数据。所以训练数据可以被表示为:
(2)
对于使用Universum数据进行多视角学习的问题,我们首次提出了以下学习模型。我们将有标签的多视角数据与另一组没有标签的Universum样本结合起来,该算法模型可以表示为:
(3)
约束条件:
对于上述提出的算法,我们给出如下详细解释。
和
分别是视角A和视角B的正则化项,用于防治过拟合。参数
是惩罚参数。参数
是非负松弛变量,用于控制两个分类器之间的间隙,希望两个视角的预测相似。
和
是视角A和视角B的非负松弛变量。
和
是Universum样本的非负松弛变量。参数
是用户定义的参数,代表Universum样本的不敏感损失。约束
和
表示的是Universum数据定义了不敏感损耗区域,Universum数据位于支持超平面之间的不敏感区域。
2.2. 对偶问题
为了解决公式(3)的优化问题,首先构造拉格朗日函数,对于公式(3)中的每个不等式约束,通过引入拉格朗日乘子
。拉格朗日函数被定义为:
(4)
根据朗格朗日的对偶性,原始问题的对偶性是极大极小问题,因此,为了解决对偶问题,我们首先对拉格朗日函数
对
进行求偏导并设置等式为0,拉格朗日函数的微分如下:
(5)
将公式(5)代入公式(4)中,得到对偶问题:
(6)
约束条件:
基于上述具有Universum数据的多视角学习模型,我们提出了该算法的完整过程,具体的算法实现步骤如表1所示。

Table 1. Algorithm implementation steps
表1. 算法实现步骤
2.3. 时间复杂度分析
我们将讨论该算法的时间复杂度并给出一个估计。该算法可以归结为凸二次规划问题(Convex quadratic programming problem),所以该算法的时间复杂度为
(l为训练样本个数,m为Universum样本个数)。
3. 实验与分析
3.1. 实验数据
我们已经试验了多个数据集,这些数据集广泛应用于多视角学习中。数据集包括Pascal Visual Object Classes、NUS-WIDE-OBJECT、Handwritten Digit和Image Segmentation,其详细描述如下:
• Pascal Visual Object Classes (VOC2007):该数据集是图像数据集,其中包含9963个真实世界的图像,这些图像分为20类,例如人,鸟,自行车,椅子等。在本实验中,该数据集被划分为5011张训练图像和4952张测试图像。
• NUS-WIDE-OBJECT:该数据集包含30,000个对象图像,并被分为30类,例如玩具,花朵,山脉,旗帜等。在本实验中,该数据集被随机分为17,927个训练图像和12,073个测试图像。
• Handwritten Digit:该数据集由手写数字(‘0’-‘9’)组成,手写数字有2000个图像,共10个类别,每个类别有200个图像。每张图片均已用二进制图像进行数字表示。在此实验中,我们从每个数字中随机选择50%的图像进行训练。其余图像是测试图像。
• Image Segmentation:是从7个户外图像的数据库中随机抽取的图像数据集,该数据库由2310个随机选择的对象组成,这些对象分为7个类,即砖墙,天空,树叶,水泥,窗户,路径和草。数据集包含19个连续属性,可以自然分为多个视角数据。
对于Universum数据而言,有几种方法可以收集Universum样本 [10] [14]。在本文中,我们使用的是
方法来生成Universum样本,并通过Universum样本的先验知识来提高该算法的性能。
方法表示分类任务中不包括的其他数据。例如,如果分类任务是对数字0和1进行分类,并且有其他数字(从2到9)的图像,这些图像可以用作Universum示例。总体而言,实验中使用的实验组和如表2所示。
Table 2. Experimental data combination
表2. 实验数据组合
3.2. 实验设置
为了验证所提算法的有效性,在实验设置阶段我们采用与其他四种多视角学习算法进行对比,对比算法如下:
• SVM-2K [6]:该方法结合了标准SVM和KCCA算法,通过利用两视图数据之间的关系来提高分类器性能。
• USVM [10]:它将具有先验知识的Universum数据与标准SVM算法结合使用,以在模式识别问题上获得更好的性能。
• MvTSVMs [15]:它引入了两个一维投影之间的相似性约束,并结合了多视角学习和双支持向量机方法。
• MvNPSVM [16]:该方法结合了非平行支持向量机(Nonparallel support vector machine, NPSVM)算法和多视角学习的优点,并将NPSVM扩展到多视角学习领域,带来了新的见解。
在实验中,我们对所有实验在两个视角上使用高斯RBF核,并且将RBF核参数
设置为
。在提出的方法中,我们设置惩罚参数
和D为
和
,参数
在
集合中调整。
对于四个对比算法,我们设置与他们的研究相似的参数,并且实验中算法的配置如下。在USVM算法中,惩罚参数C和D分别设置为
和
。在SVM-2K算法中,在
集合中均等设置惩罚参数
和
,参数D和
分别在
和
上调整。对于MvTSVM和MvNPSVM算法,我们将惩罚参数
和
分别从
和
集合中选择。参数
和
的取值范围为
。对于所有方法,为了避免实验中的采样偏差,我们使用五次交叉验证,选择四层作为训练集,另一层被视为每一轮的测试集。另外,五次交叉验证用于确定实验中的适当参数。例如,对于提出的方法,我们在表2中填写适当的参数,该参数在五次训练和测试集中处于最高性能。
3.3. 实验结果分析
3.3.1. 性能比较
在本节中,我们将比较提出的方法和四个对比方法的性能。表3汇总了四个数据集中不同方法的分类准确性以及标准差。
Table 3. Classification accuracy and standard deviation result statistics
表3. 分类准确度和标准差结果统计
我们可以观察到,提出的方法始终可以比其他方法表现更好。例如,对于数据集1,SVM-2K,USVM,MvTSVMs和MVNPSVM方法分别获得“82.60”,“83.50”,“81.65”,“86.50”的精度;但是,提出的方法可以达到“90.45”的精度,优于其他方法。发生这种情况的原因是,这是因为提出的方法将Universum数据考虑到多视角学习中,从而可以修改多视角学习的决策边界。但是,在构造分类器时,SVM-2K,MvTSVMs和MVNPSVM方法不会考虑Universum数据。因此,提出的方法可以比其他方法执行得更好。对于USVM方法和提出的方法,它们都考虑了Universum数据。但是,提出的方法仍然比USVM具有更好的性能。发生这种情况是因为所提出的方法将多视角数据合并到学习中,可以提供更好的特征表示,因此,所提出的方法比USVM方法更好。对于标准偏差比较,我们可以进一步观察到,对于大多数数据集,所提出的方法可以提供比其他方法更少的标准偏差。例如,对于数据集1,所提出的方法的标准偏差为1.01,而其他方法则大于1.01。这表明,提出的方法可以提供相对稳定的性能。
3.3.2. 训练样本数量分析
本文在Pascal VOC2007,NUS-WIDE-OBJECT,Handwritten Digit和Image Segmentation的不同大小的训练集,实现了SVM-2K,USVM,MvTSVMs,MVNPSVM和所提出的方法。我们以上述四个数据集为例。对于NUS-WIDE-OBJECT数据集,训练大小从{6000, 8000, 10,000, 12,000, 14,000}集合变化。同样,我们改变Pascal VOC2007,Handwritten Digit和Image Segmentation训练样本大小,如图2的x轴所示,Universum样本的数量是恒定的。另外,图2显示了根据上述变化的训练量数据集的SVM-2K,USVM,MvTSVMs,MVNPSVM和所提出的方法的分类精度。我们可以发现,在几乎所有情况下,提出的方法显然都优于其他比较算法,并且随着训练样本数量的增加,所有已实现算法的分类精度都会提高。

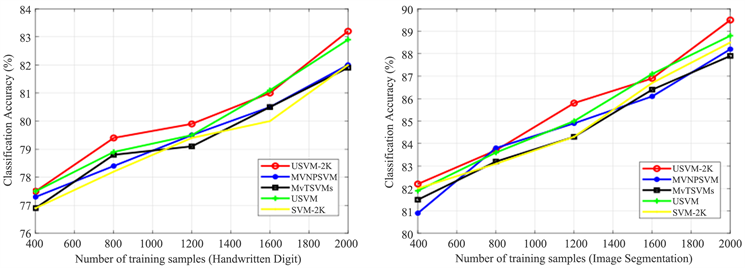
Figure 2. Classification accuracy under different number of training samples
图2. 不同训练样本数量下的分类准确率
3.3.3. Universum样本数量分析
研究结果表明,Universum样本的大小不同也会影响算法的性能 [14]。因此,我们在此讨论所提出的算法在Universum样本数量变化的情况。实验中,所有参数保持不变,即
。图3显示了所提出的方法和USVM方法在不同数量的Universum样本下的分类准确率。在图3中,水平轴表示Universum实例的大小,即NUS-WIDE-OBJECT的Universum大小在{500, 1000, 1500, 2000, 2500}的集合中变化。同样,我们改变Pascal VOC2007、Handwritten Digit和Image Segmentation数据集的Universum样本大小,如图3的x轴所示。纵轴表示对应的分类精度。从图中可以看出,不同数量的Universum数据对分类有一定的影响。例如,可以发现在NUS-WIDE-OBJECT的数据集中,当Universum的数据量较小时,分类准确率较低,然后性能曲线随着样本数量的增加而增加。而当Universum数据量达到1000时,分类准确率达到最高。当Universum数据量不断增加时,分类精度在总体上仍能保持相对稳定。类似地,其他数据集也显示出类似的效果。
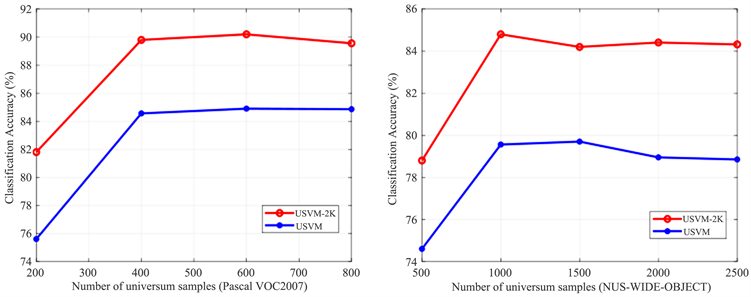

Figure 3. Classification accuracy under different number of universum samples
图3. 不同Universum样本数量下的分类准确率
4. 总结与展望
在本文中,我们提出了一种基于Universum数据的多视角学习算法。新提出的方法借助于不属于任何一类分类问题的Universum示例,既继承了先前的多视角学习的优势,而且可以获取更多的关于整个数据分布的先验知识。为了有效的求解该算法,我们推导了该算法的对偶形式,为了得到更有效的预测模型。为了验证所提出方法的有效性,我们在真实的数据集上进行了实验。在图像数据集的情况下,我们讨论了所有方法的分类准确率,并分析了不同训练规模下的分类性能。在未来,我们希望研究在数据流环境中的多视角学习和Universum数据的结合。
基金项目
本文得到国家自然科学基金资助项目(No.62076074)的资助。