1. 引言
学习分析(Learning Analytics, LA)用于描述技术增强学习(Technology Enhanced Learning, TEL)研究领域 [1],该领域的目标是开发用于检测教育系统中数据模式的方法,并使用这些方法来提高学习体验。学习分析所使用的机器学习算法大多依赖于数据良好的特征表示,而教育系统中的特征常基于专家知识进行人为设计,导致教育系统之间特征构造方法往往不同,难以复用,海量的在线教育数据无法得到充分利用。
目前,基于深度学习实现端对端的特征提取因其便捷性受到了广泛的关注。将文本转换为实数向量属于自然语言处理(Natural Language Processing, NLP)的研究领域,通常被称为文本嵌入方法。然而,课堂的简介通常篇幅较短并含有大量的专业性词汇,使用传统的文本嵌入方法来提取特征效果欠佳。
近期有研究者的工作 [2] 表明,使用图卷积神经网络可以高效地提取单词–单词和文本–单词特征用于文档分类,证明了结构信息对文本嵌入的增益。基于此,本文提出了基于LSTM [3] /GCN [4] 的在线学习文本特征提取方法,方法分为三个模块:数据预处理模块,语义嵌入提取模块和结构嵌入提取模块。通过利用文本–文本结构信息对文本的语义嵌入向量进行补充和增强来得到课堂的表示向量。其中结构嵌入被定义为包含当前文本与其上下文文本结构信息的嵌入向量。方法大致过程如下:利用文本嵌入提取模块将课堂描述文本转化为语义嵌入向量;再将语义向量输入到结构嵌入提取模块进行更新融合得到结构嵌入向量;最后将这两部分向量结合得到最终的课堂嵌入向量。
2. 相关研究
文本嵌入是自然语言处理中将文本映射到实值向量空间技术的统称。一种常见的做法是使用词嵌入模型得到所有单词的嵌入,再用平均或求和操作作为后处理得到文本嵌入。Siamese CBOW [5] 选择将平均操作纳入到训练过程中,通过预测当前句子邻近句子的嵌入得到了更鲁棒的方法。Arora [6] 使用平滑的反频率加权机制取代平均操作,并参考PCA/SVD对词嵌入的平均向量进行修改,结果表明词嵌入加权平均是一条简单但难以超越的基线。随着人工智能的发展,神经网络在各基准任务的突出表现,部分研究者将Word2vec [7] 和Doc2Vec [8] 的思想与神经网络优秀的特征提取能力相结合,获得了良好的效果。Sent2Vec [9] 扩展了Word2Vec的PV-CBOW结构,利用N-Gram进行句子表示的学习,并使用平均算子得出句子向量。Doc2VecC [10] 结合了Doc2Vec的PV-DM结构和词嵌入平均,添加了一些噪声以产生更健壮的文本嵌入。Vo [11] 在Doc2Vec的PV-CBOW架构中加入了句法成分,丰富了文本嵌入的情感信息。一些研究者通过使用更复杂的编码器以提取更丰富的信息。Quick-thought [12] 使用了两个编码器来增强提取能力,S-BERT [13] 则选择语言模型BERT进行微调作为编码器。
上述工作为将文本映射到实值向量空间提供了各种创新解决方案,并在基础任务的表现上有了显著的突破。然而这些模型对文本之间的关系的利用并不充分。如Doc2Vec使用了一个独热向量来表示模型当前关注并训练的文本向量,即在当前文本嵌入的更新阶段不涉及与其相关的文本。S-BERT通过对正负文本样本进行采样作为训练数据进而将文本之间的关系考虑在内,并使用了微调过后的BERT模型作为嵌入编码器。这种方法很好地利用了BERT提取语义信息的能力,但是只考虑二元关系可能是不充分的。“上下文无关的方法”常使得文本之间隐藏的信息没有得到充分的利用 [14],Angelova等通过改进松弛标记技术以充分探索数据的上下文关系;Liu [15] 通过在LSTM使用双注意力机制利用单词上下文信息提高分类精度;曾 [16] 通过在注意力层后增加填充层确保每个单词都具备上下文信息;Yao [2] 通过在单词–文档异构图上运用图卷积技术将文本分类任务转化为节点标注任务。以上的工作都利用了结构信息,Angelova利用了文本–文本之间的信息,但因为传统方法特征提取能力有限,算法过程仅对文本可能的类别进行预测,未形成其它任务可复用的文本嵌入。Liu [15]、曾 [16] 和Yao [2] 更进一步,使用目前更流行的BiLSTM和GCN对单词向量进行处理得到了文本嵌入,但只探讨了单词–单词和单词–文本之间的关系。
3. 基于LSTM/GCN的文本特征提取方法
在学习网站中,学习者浏览的每一节课堂都是一门课程的一部分,课程之间存在复杂的先修关系,每门课程又可能同时属于多个教育计划。这就导致了课堂之间存在复杂的结构信息。利用这些结构信息对语义信息进行补充,可以更好地服务于学习网站的学习分析。本节描述了构建课堂嵌入的流程,图1展示了将原始文本数据转换为嵌入数据的流程,其中
符号表示将两个流程得到的向量连接在一起。
数据预处理模块将从在线学习平台获得的原始文本数据进行清洗、分词和标注等操作,数据预处理模块之后通过语义嵌入提取模块将文本数据转化为实数向量。随后是本方法的核心模块:结构嵌入提取(SEE)模块,如流程图所示,SEE模块有两种架构,每种架构对应一种课程内课堂可能的结构,分别为时序式和图式。提取器输出的内容作为该课堂的结构嵌入,为课堂嵌入提供更丰富的特征。最后,课堂嵌入的计算公式为
(1)
其中,特定课堂i的课堂嵌入
是一个实数向量,它由连接文本嵌入
和结构嵌入
得到。函数
的作用是将传递给它的两个向量连接在一起。
和
的值分别由文本嵌入模块和SEE模块获得。

Figure 1. LSTM/GCN-based text feature extraction process for online learning
图1. 基于LSTM/GCN的在线学习文本特征提取流程
3.1. 数据预处理模块
数据预处理模块主要分为以下步骤:在英文书写的过程中,为了强调或风格区分,文本中同一个单词因为大小写可能有多种形式,但往往它们表示的是同一个意思。为了消除冗余,将文本归一化至全小写;数据清洗阶段将噪音数据进行消除,例如本文实验中,消除内容为“exam”的课堂,因为它不存在有效的文本信息;分词阶段将文本分成无法再分拆的有意义的符号,对于英文文本进行分词往往指的是将每个句子分割成一系列的单词的过程;词性标注阶段给单词标上词类标签,比如名词、动词、形容词等,因为了解单词在句子中的用途有助于模型更好理解句子内容;去除停用词阶段从文本内删去“the”、“is”和“at”等对文本特征没有贡献作用的字词。
3.2. 语义嵌入提取模块
语义嵌入提取模块采用的是Doc2Vec的PV-DBOW架构。Doc2vec受Word2vec的启发,目标是将可变长度的文本映射为固定长度的向量表示形式,是一种无监督方法,PV-DBOW与Word2vec的Skip-Gram架构相似,它以段落ID和段落内句子的抽样作为输入,通过预测采样句子中的单词进行训练。训练结束后使用段落矩阵作为查找表来获取段落表示,本文提出的方法采用python的自然语言处理库gensim中对Doc2Vec的实现。
3.3. 结构嵌入提取模块
LSTM常用于时序数据的特征提取,而图神经网络(Graph Neural Networks, GNNs)常用于基于拓扑信息的特征提取。基于此,结构嵌入提取模块将两者作为基础组件,针对在线学习数据可能具备的结构特征设计了两种结构嵌入提取器,分别是上下文序列提取器和上下文图提取器。
3.3.1. 上下文序列提取器
学习者对一门课程的学习记录通常可以看成一段关于课堂的时序数据。基于此,上下文序列提取器(Context Sequence Extractor, CSE)将Doc2Vec得到的课堂的文本嵌入作为输入用于提供课堂之间的差异,并使用堆叠的Bi-LSTM层来捕捉课堂间的顺序信息。CSE的训练目标是将一个课堂序列准确地分类到其对应的课程中,此时中间层的输出融合了语义和结构信息,将其作为对应课堂的结构嵌入。
LSTM单元中根据上一个隐藏状态
计算当前隐藏状态
的步骤可以描述为以下公式:
(2)
(3)
(4)
(5)
(6)
(7)
其中
、
、
和
分别表示遗忘门、输入门、输出门和LSTM单元的参数矩阵。
是时间t和
单元状态的加权和,sigmoid激活函数
将两者权重映射到0和1之间。再经由激活函数
得到加权系数
,最终得到隐藏状态
。CSE架构基于Bi-LSTM单元,如图2所示。

Figure 2. Contextual sequence extractor CSE Architecture
图2. 上下文序列提取器CSE架构
其中
表示从Doc2Vec模型得到的第i个文本嵌入。在Bi-LSTM单元中,将课堂的文本嵌入序列从左到右输入LSTM_L得到
,使用相反的顺序输入LSTM_R得到
,通过将两者连接得到
。CSE以固定窗口大小的文本嵌入序列作为输入,通过两层Bi-LSTM及全连接层后将其分类为不同的课程。在分类目标的引导下,CSE的输出逐渐向类别的独热向量靠拢,而隐藏层则保留了课程之间的序列结构信息。因而将CSE的第一层输出的隐藏状态序列作为结构嵌入。由于滑动窗口之间有重叠,大部分课堂根据其在滑动窗口中的不同位置有多个隐藏状态,这里采用平均运算作为后处理来得到课堂i的唯一嵌入。如公式(8)中所述。
(8)
其中j表示课堂i在滑动窗口中的位置,n表示滑动窗口的大小。将课堂i状态向量的平均与其文本嵌入相连接,得到课堂i的嵌入向量。
受到Word2Vec [7] 的启发,其中CBOW架构将锚词i周围的词作为输入,并将i作为预测目标。基于此本文提出了上下文序列回归提取器(Context Sequence Regression Extractor, CSRE)。CSRE将粒度从单词扩展到文本,并将预测目标从中心改为右侧。
网络整体结构与图2相同,但用回归层代替了分类层。其目标是根据前几节课堂的文本嵌入来拟合下一个课堂的文本嵌入。公式(9)显示了它的计算方式。
(9)
其符号约定与CSE的公式一致。略有不同的是,每门课程最后一节课堂的结构嵌入无法通过模型的隐藏层获得,本文使用同一门课程中其他课堂的结构嵌入的平均值作为最后一节课堂的结构嵌入。
3.3.2. 上下文图提取器
当课堂i-1和i-2是课堂i的预备知识,但预备知识之间没有关联时,形成课堂i-1和i-2有一条指向i的弧的“V”型结构。为了利用这类隐藏的结构信息对课堂嵌入进行补充,本文引入了可以在非欧几里得空间进行卷积的GCN [4],并基于此提出上下文图提取器(Context Graph-like Extractor, CGE)来获得课堂的结构嵌入。GCN层间的更新公式 [4] 如下所示。
(10)
其中
表示输入图的重归一化邻接矩阵,重归一化指的是图中的每个节点加上了一条指向自己的弧。
表示
的度矩阵。也可以将GCN的更新公式(10)改写成公式(11),其中
是输入图第i个节点的表示向量,
是节点i邻居表示向量的集合。
(11)
公式(11)形式化地描述了更新的两个步骤:首先对每个节点i使用平均算子聚合其邻居节点线性变化后的特征,然后使用非线性激活函数
得到下一层该节点的输入
。基于GCN层,CGE_N架构如图3所示。
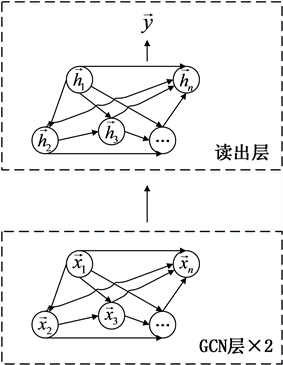
Figure 3. Context Graph Extractor CGE_N Architecture
图3. 上下文图提取器CGE_N架构
CGE_N架构中图的构造基于当前课堂只和滑动窗口内先修于它的课堂相关,在图3中表示为滑动窗口内当前课堂之前的所有课堂都有一条指向当前课堂的弧线。CGE_N架构使用课堂的文本嵌入作为节点特征,在图中用
表示。CGE_N将上述图和节点特征作为输入,在训练过程中,图中的节点通过弧线进行通信,使节点的文本嵌入进行融合。读出层合并了所有节点的隐藏表示,以获得图级表示进行分类任务。CGE_N架构使用第二层GCN层的输出
作为结构嵌入,并使用平均运算对因为滑动窗口重叠而带来的多份结构嵌入进行后处理,如式(12)所示。
(12)
在CGE_N架构中,权重在同一GCN层之间是共享的,即课堂图中节点对待每个邻居的方式是一样的。考虑滑动窗口中的最后一个课堂节点,所有节点都有一条指向它的弧线,使用相同的权重将距离不同的节点特征进行聚合是不自然的。Veličković [17] 提出的GAT层通过将注意力机制引入图卷积层来获取一定的灵活性。
通过将GCN网络层替换为GAT网络层,提出了基于GAT的CGE_T架构,在GAT层中课堂节点通过注意力机制获得对各个邻居权重值用于更新自身的隐藏表示。公式(13)用于构建课堂嵌入,其中
代表第二个GAT层的输出。
(13)
4. 实验与分析
4.1. 数据集
实验所用数据收集于Open Yale Courses (https://oyc.yale.edu/courses)平台,它提供了由耶鲁大学杰出教师和学者教授的入门课程。Open Yale Course目前包含了来自22个领域的40门课程,每门课程都有一套学习材料,如视频片段、课程描述和音频等。数据集Yale Open Course Ware Corpus由南特大学DUKe实验室提供,其收集了Open Yale Courses网站的课程信息,并以CSV格式保存数据。数据集中有22个院系,每个院系的课程数量从1门到7门不等。40门课程总共由1058节课堂组成,每门课程的课堂节数从16节到41节不等。
4.2. 评价指标
因课堂与课程之间的映射关系是已知信息而且对学习分析任务的帮助不大,使用常规的文本分类作为评价指标不够充分。基于特征丰富的嵌入应能保留同一课程内课堂的一致连贯性,相邻的课堂应在嵌入空间有着较小的距离,本文提出投影–检索评估算法计算MeanRank以评估各方法所得课堂嵌入的质量。
算法1步骤9中以
对投影模型的输入进行构造,其中
为当前处理的课堂嵌入,
为基于当前课堂采样得到的课堂嵌入,每一对
和
的类别由课程中两者的相对位置得到。“0”代表课堂j是课堂i的下一节课;“1”代表j课堂与i课堂的距离在sn以内;“2”代表i和j两节课堂距离较远,负样本由步骤6中函数
采样得到。在对输入进行线性变换后,采用三路softmax对两者的相对关系进行分类。投影模型可形式化表述为式(14)。
(14)
其中W为投影模型参数,在步骤15处进行更新。Reimers [13] 的实验表明这种输入的构造方式可以更好地捕捉到两个向量之间的差异。在检索阶段,
课堂嵌入和所有课堂嵌入的组合作为投影模型的输入。MeanRank指标着重评估嵌入方法是否捕捉到相邻课堂之间的关系。步骤20使用投影模型model将两个课堂嵌入向量关系分类为“0”概率的倒数作为两个嵌入之间的距离。如式(15)所示。
(15)
其中
和
可以是方法所得SEs中课堂嵌入的任意组合,式中分母部分衡量了课程j紧随课程i之后的概率大小。检索结果根据距离公式所得进行升序排序,其中类别为“0”的课堂嵌入的序号
作为这次检索的表现。将所有课堂作为i课堂进行检索,步骤22取所有检索表现的平均值MeanRank作为当前嵌入模型的表现。
4.3. 实验
为了方便对加入SEE模块前后的表现进行比较,实验中对Doc2Vec得到的嵌入进行了评估。在实验设置中,文本嵌入和结构嵌入的维度分别为78和40。即增加SEE模块后,课堂嵌入的维度会发生改变,因此增加了维度为118的Doc2Vec的试验。图4展示了各嵌入方法的投影–检索评估结果。

Figure 4. MeanRank of each method in the 10-fold cross-validation training in projection model
图4. 十折交叉验证训练投影模型各方法所得MeanRank
由于维度为78的Doc2Vec嵌入包含了大部分信息,Doc2Vec78和Doc2Vec118的表现几乎趋于同一点。根据MeanRank的计算方式,它代表了课堂嵌入检索结果中类别“0”样本的平均序号。其值越小,说明该嵌入模型得到的课堂嵌入在投影–检索评估中表现越好。图4显示,表现最好的是CSRE,最差的是Doc2Vec118。表1显示了各嵌入方法MeanRank收敛到的确切值。
本实验统一使用Doc2Vec作为文档嵌入模块。表1的前两行显示的是没有SEE模块的结果,其后是选择SEE模块的不同架构得到的结果。CSE和CSRE得到了最好的结果,与Doc2Vec118相比,CSRE的表现提高了十倍左右。CSE和CSRE在获取结构嵌入时都考虑了课堂的局部顺序,在获取结构嵌入的过程中把课程中的课堂当作序列来处理。CSRE的效果要好于CSE。可能是因为CSE在训练过程通过文本嵌入序列预测课程类别,关注的是序列与整体之间的关系;而CSRE通过前面的课堂嵌入对下一节课堂的嵌入进行拟合,关注的是一节课堂与其之前的课堂之间的关系。此外,当只考虑到文本嵌入而不是与课程信息混合时,结构性信息可能会占据更大的比例。

Table 1. MeanRank value of each embedding method
表1. 各嵌入方法MeanRank值
CGE试图挖掘课堂之间更复杂的关系,通过构造课堂图以及图中课堂节点之间特征的交流和融合,来使得节点获得特征更丰富的嵌入。然而,定义一个固定的图结构对局部课堂之间的关系进行建模似乎过于严格。其在投影–检索评估中的表现比没有SEE模块的Doc2Vec118提升了一倍,但比CSE的表现差。通过将GCN层改为一定程度上可以调节图结构的GAT层使得表现有所提升,也证实了CGE_N中人工定义的结构过于严格。可以预见,CGE_T架构在更大、更复杂的结构化数据集上可以有更好的表现。
为了验证SEE模块对分类精度的影响,补充了在Open Yale Course数据集上进行文本分类任务的实验,结果如表2所示。
Table 2. Text classification accuracy of each embedding method
表2. 各嵌入方法文本分类精度
实验选取了SEE模块中没有用到课程类别信息的CSRE架构进行验证,实验结果表明加入CSRE提供的结构信息后可以在传统的文本分类任务中有良好的表现。
4.4. 可视化
本文使用t-SNE (t-distributed stochastic neighbor embedding)降维可视化来探索结构嵌入对课堂嵌入的影响。根据下图5可以得到一些有趣的结论。
结果可按使用传统方法、SEE模块CSE架构和SEE模块CGE架构分为(a)(b)、(c)(d)和(e)(f)三组。子图(a)和(b)仅使用Doc2Vec模型,所得嵌入在降维后,课堂根据所属课程的不同形成了明显的聚簇,但课程内部课堂的分布稀疏散乱;子图(c)和(d)除了分离每门课程外,多处课堂之间连成了一条序列,即通过将文本嵌入和SEE模块CSE架构所得结构嵌入相连接,能为课堂嵌入提供序列结构信息。子图(e)和(f)中也形成了聚簇,但很难说它们遵循固定的结构。这可能是硬编码图结构和课堂间自然结构相冲突的结果。
 (a) Doc2Vec78 (b) Doc2Vec118
(a) Doc2Vec78 (b) Doc2Vec118  (c) Doc2Vec + CSE (d) Doc2Vec + CSRE
(c) Doc2Vec + CSE (d) Doc2Vec + CSRE  (e) Doc2Vec + CGE_N(f) Doc2Vec + CGE_T
(e) Doc2Vec + CGE_N(f) Doc2Vec + CGE_T
Figure 5. t-SNE dimensionality reduction visualization of embedding vectors of each method
图5. 各方法所得嵌入向量的t-SNE降维可视化
5. 实验与分析
本文的目的是通过考虑上下文结构信息以获得更好的在线学习文本的嵌入。本文基于LSTM/GCN提出结构嵌入提取(SEE)模块,通过将结构嵌入与传统方法获得的文本嵌入进行结合对文本特征进行强化。在获得结构嵌入向量后:可视化结果表明,在线学习文本嵌入在降维空间中形成的聚簇包含更有意义的结构信息;MeanRank指标显示在线学习文本之间相邻的关系得到更好地留存;在传统的文本分类任务中,分类精度有所提升。综上,本文提出的基于LSTM/GCN的文本特征提取方法在在线学习文本数据上表现优于传统方法,可以作为在线教育学习分析可信的特征来源。在后续研究中,将结合课堂多个方面的信息,如分别从视频、简介文本和音频进行特征提取并集成,从多维特征信息对课堂的特征进行补充和增强。
致谢
在本次论文的撰写中,我得到了曾安教授和潘丹高工的精心指导,并得到了国家自然科学基金项目和广州市科技计划项目的大力支持,在此表示衷心的感谢。
基金项目
国家自然科学基金项目(61772143, 61300107),广州市科技计划项目(201804010278)。
参考文献