1. 引言
随因特网和移动设备的普及,微博逐渐成为人们获取和表达信息的主要平台。它给人们生活带来便利的同时,也带来了谣言泛滥的问题。中文社会科学院发布的《新媒体蓝皮书》显示,中国有59%的网络谣言来自新浪微博 [1]。谣言传播恐惧和偏见,它可能会造成(个人、品牌、政府等)被诽谤 [2],甚至导致出现社会信任危机。所以,微博谣言检测是一项十分有必要的研究工作。
在研究早期,谣言检测主要是以特征工程为基础的机器学习方法,例如Ma等人 [3] 用到支持向量机(Support Vector Machine, SVM)。随算力快速提升,以深度学习为基础的方法成为机器学习主流,各类深度学习方法在谣言检测领域取得了长足的进步。Ma等人 [4] 和Wang等人 [5] 用到循环神经网络(Recurrent Neural Network, RNN),Yu等人 [6] 用到卷积神经网络(Convolutional Neural Networks, CNN),Bian等人 [7] 用到图卷积网络(Graph Convolutional Network, GCN),尹鹏博等人 [1] 和Geng等人 [8] 用到以深度学习为基础的集成学习(Ensemble Learning, EL)。
尽管当前以深度学习为基础的方法取得了不错的效果,但它们没有充分利用预训练语言模型或用户特征。以BERT(Bidirectional Encoder Representations from Transformers) [9] 为代表的预训练语言模型已经在诸多自然语言处理领域取得了领先的效果。其以Tansformer [10] 为基础,经过大规模文本预训练,学到了丰富的语言知识,可将知识迁移至任意下游任务。另外,用户特征已被证明能有效促进谣言检测 [11],通常越是权威的用户发布的消息越真实可靠,反之亦然。因此本文提出User-BERT模型,充分将文本特征和用户特征与BERT模型相结合,充分发挥BERT模型的性能优势。User-BERT模型将BERT模型作为文本编码器对原文和评论文本进行编码,然后将输出的文本表示向量和用户特征向量进行拼接组成新的综合表示向量,最后将综合表示向量输入至全连接层即深度分类器中进行解析并预测结果。实验结果表明,在Ma等人 [4] 提出的公开微博数据集上,User-BERT取得了当前最好的实验结果。
2. 相关工作
因社交平台的普及,谣言检测引起了更多重视,随机器学习的发展而进步。机器学习的早期主要以特征工程为基础的方法为主流,在谣言检测领域同样如此。Ma等人 [3] 从内容、用户、传播三方面共选取了27条特征表示数据,用SVM模型作为分类器。其它以特征工程为基础的方法大致相同,特征选取是这类方法的关键,发掘有效的特征能给模型带来显著的提升。近些年因深度学习的快速发展,以深度学习为基础的方法已经成为机器学习的主流。深度学习因其自动提取高级特征和更强的拟合数据的能力得到广泛应用,多种深度学习模型也被应用到谣言检测领域。Ma等人 [4] 用词频-逆文本频率指数(Term Frequency-Inverse Document Frequency, TF-IDF)表示原文或评论,然后逐步将特征表示输入到RNN模型中,用最后的输出向量预测结果。Wang等人 [5] 用word2vec对原文或评论作词嵌入,同时结合情感词典加入情感嵌入,分别输入到两个双层RNN模型中。Yu等人 [6] 用CNN模型作为特征提取器构建检测模型。Bian等人 [7] 则用到了近来流行的GCN模型 [12] 通过学习谣言的传播特征来判别真假。此外,还有联合多个深度学习模型为基础学习器的深度集成学习模型。尹鹏博等人 [1] 以CNN和RNN模型作为基分类器,选取随机森林作为元模型,合并基模型的输出为二次训练集,在元模型上进行二次训练。Geng等人 [8] 用三种RNN模型作为基分类器,最后以投票的方式整合基分类器的预测结果。
3. 先导
3.1. 问题描述
谣言检测任务可被定义为:设数据集定义为
,
表示一条数据元组,n表示数据集的大小。且
,其中
表示原文,
表示原文的字,m为原文的长度;
表示原文si对应的评论(回复)集,
表示一条评论,其中每条评论又由若干字组成,o表示评论个数;ui表示发布者的用户画像,用户画像由若干个属性组成;li表示该条数据的标签,具体为{0, 1},0表示为真,1表示为假。总之,对于数据集D,给定{s, C, u},需要预测其标签l。
3.2. Tansformer
BERT模型以Transformer编码器为基础构建,其结构如图1所示。Transformer最早由Vaswani等人 [10] 提出,分为编码器和解码器。BERT用编码器作为模型的基本单元,Base版本堆叠12层Tansformer编码器,Large版本则堆叠24层Transformer编码器。Transformer作为强特征提取器,其成功主要归功于全局的多头自注意力机制,该机制的公式化描述为:

Figure 1. Structure of Transformer encoder
图1. Transformer编码器结构图
(1)
(2)
Q代表Query矩阵,K代表Key矩阵,V代表Value矩阵,它们从相同的表示矩阵经过线性变换而来,即自注意力机制。dk表示向量的维度。公式(1)得到经过自注意力机制计算后的表示矩阵,公式(2)意为将多头注意力表示矩阵做拼接即得到最终表示矩阵。
4. User-BERT模型
4.1. 整体架构
图2展示了User-BERT模型的整体架构。架构大致可以分为两部分,本文编码器和深度分类器。文本编码器即为BERT模型,其将谣言原文和评论的文本编码成文本表示向量。输出的文本表示向量和用户属性向量进行拼接,形成综合表示向量。深度分类器为全连接层网络(Fully Conneted Network, FCN),对综合表示向量进行解析并输出最后预测结果。
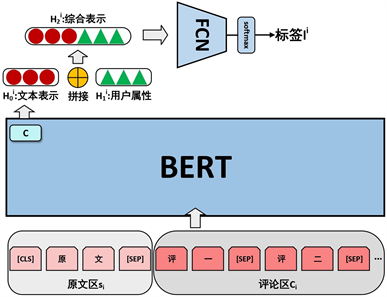
Figure 2. Overall structure of User-BERT
图2. User-BERT整体架构
4.2. 文本编码
文本将BERT文本编码器的输入分成原文区和评论区两部分,原文区长度限制为128,评论区长度限制为384。(BERT长度限制为512)原文和评论及评论和评论之间用[SEP]表示符进行分隔。评论按照时间先后顺序排列。本文取BERT最后一层的[CLS]表示符对应的表示向量作为整体文本的表示向量。该过程可公式化为:
(3)
si表示原文,Ci表示评论集,
表示数据i的文本表示向量。文本表示向量不仅包含了原文的特征,还包含了丰富的评论特征。
4.3. 用户特征
本文对用户属性分布进行了详细分析,最终选出六个分布差异明显的用户特征,详见附录。即ui = {verified, verified_type, verified_reason_length, followers_count, bi_followers_count, statuses_count}。verified表示用户是否得到官方认证,verified_type表示认证类型,verified_reason_length表示认证原因的文本长度,followers_count表示粉丝数量,bi_followers_count表示双向关注用户数量,statuses_count表示用户的微博数量。将文本表示向量
和用户属性向量
做拼接,得到综合表示向量
:
(4)
4.4. 深度分类器
深度分类器采用FCN模型,对输入的综合表示向量
进行解析得到中间结果向量hi:
(5)
最后通过softmax [13] 激活函数对hi进行归一化处理即可得到数据di对应标签li的概率分布:
(6)
5. 实验与分析
5.1. 数据集
本文采用的数据集是Ma等人 [4] 提出的新浪微博数据集Ma-Weibo。数据集从微博社区管理中心1收集而来,其中的谣言数据由人工验证且公开,是来自现实中的真实数据。数据集总共包含4664条数据,谣言2313条,非谣言2351条。公开的数据集2带有微博原文、评论、用户属性等信息。
5.2. 实验设置
实验设备情况大致如下,操作系统为Ubuntu 18.04.4,CPU型号为Inter(R) Xeon Silver 4110,显卡型号为GeForce RTX 2080Ti。采用的BERT是谷歌官方3提供的中文Base版模型,实验环境为Python3.6、Tensorflow1.14。FCN模型为三层的全连接层网络,前两层神经元个数为128,第三层为2。训练时使用两段式分别训练User-BERT的文本编码器和深度分类器,第一阶段使用数据集对BERT模型进行调优,第二阶段冻结BERT模型参数,对FCN模型参数进行训练。此外,训练BERT的学习率为2e-5,epoch为8。
5.3. 对比方法
实验充分对比了各种机器学习方法,从特征工程到最新的深度学习方法。对比的方法如下:
· SVM-TS (Ma等人提出 [3] ):使用线性SVM分类器对人工提取特征进行分类。
· RNN (Ma等人提出 [4] ):将原文和评论的表示向量输入到RNN网络进行分类。
· CGRU (Wang等人提出 [5] ):除原文和评论,加入情感特征到RNN网络进行分类。
· CAMI (Yu等人提出 [6] ):使用CNN模型对谣言进行分类。
· Bi-GCN (Bain等人提出 [7] ):使用双向GCN网络学习谣言传播特征进行分类。
· RFS-BD (尹鹏博等人提出 [1] ):使用CNN和RNN作为基学习器,随机森林为元学习器的集成学习。
· GRU-Ensemble (Geng等人提出 [9] ):使用三种RNN模型作为基学习器,以投票方式进行分类。
5.4. 结果分析
表1展示了所有方法的实验结果,文本提出的User-BERT在每个指标都取得了最好的结果。本文取准确率、精确率、召回率及综合考虑精确率和召回率的F1值四个指标,充分展示各模型的表现结果。对比方法的结果取其论文和复现实验中最好的结果。通过观察可以得到以下结论:(1) SVM-TS的结果比其它深度学习方法都要差,说明深度学习方法比特征工程方法确实有明显的性能优势。(2) User-BERT的结果好于RNN和CGRU,显然是因为Tansformer比RNN单元有更强的特征提取能力,RNN单元随着序列长度增加会遗忘部分信息,而Transformer则能从全局注意力中学习。(3) User-BERT的结果明显好于CAMI,说明Tansorformer比卷积神经网络更适合用于处理文本信息。(4) User-BERT的结果好于Bi-GCN,说明即使不使用谣言的传播信息也可以达到更好的结果。(5) User-BERT比两个集成模型即RFS-BD和GRU-Ensemble的表现明显更加优异,展示了User-BERT单模型的强大性能。

Table 1. Comparison of experimental results
表1. 实验结果对比
5.5. 消融实验
为了更好理解User-BERT每个部分的作用,文本对User-BERT模型进行了消融实验,实验结果如表2所示。User-BERT/User表示只去除用户属性,User-BERT/Comment表示只去除评论信息,User-BERT/User/Comment表示去除用户属性和评论信息。可以看到,去除用户属性或评论信息都会造成性能下降,说明它们对谣言检测都有帮助。而从下降幅度来看,评论信息比用户属性更加重要,这可能是因为参与用户能有效反映原文的情感和观点 [14],给原文补充更多有效特征。
Table 2. Comparison of ablation experiment results
表2. 消融实验结果对比
6. 总结与展望
本文提出了User-BERT模型,充分利用预训练语言模型BERT和文本信息及用户属性相结合,并在公开微博数据集Ma-Weibo上取得了最好的结果。通过实验还证明了评论信息和用户属性对谣言检测的作用。未来将考虑把更多可能的特征融入到预训练语言模型中,比如知识被证明对谣言检测很有帮助 [15],传播路径也被证明有帮助 [7]。此外,还将会使用更多其它的预训练语言模型进行实验。
附录
NOTES
· 1https://service.account.weibo.com/
· 2https://www.dropbox.com/s/46r50ctrfa0ur1o/rumdect.zip?dl=0
· 3https://github.com/google-research/bert