1. 引言
FCM算法是一种经典的聚类方法,由Dunn [1] 在1973年提出。由于其简单易实现,并能获得较好的结果而广泛应用于数据挖掘、模式识别、信号处理、图像分割等领域中 [2] [3] [4]。但FCM算法仍然存在依赖初始聚类中心、对噪声敏感度、容易陷入局部最优等缺陷。近些年来,许多改进的FCM算法 [5] [6] [7] 和聚类有效性指标被提出以提高聚类的效果。如Ayan Seal等人 [8] 提出一种基于Jeffreys散度为相似度度量的改进FCM算法(JDFCM),大大提高了聚类性能。Niteesh Kumar等人 [9] 给出两种不同的距离度量方法来适应噪声环境,提出了AMFCM算法和EMFCM算法。同时,FCM聚类算法与其他优化算法的结合也大大提高了算法的性能。例如,文献 [10] 讨论了一种基于FCM和FPSO的混合聚类算法(FCMPSO)用来提高聚类效果。因为在噪声和样本分布不均衡的环境下,聚类结果不理想,文献 [11] 考虑到每个样本的重要性,提出了具有样本自适应权的FCM算法(AFCM)。
众所周知,聚类中心在聚类过程中起着重要的作用,对聚类结果有着重要的影响。事实上,每个聚类中心都有自己的重要性,应该区别对待。例如,在对中国城市群的研究中,北京、上海这样的中心城市,由于其巨大的经济辐射能力,应该比西安、成都等西部中心城市更受到关注。为此,本文提出一种基于PSO-TVAC的中心自适应权的FCM聚类算法(CWAFCM)。新算法将中心权重向量ψ和自适应指数q引入目标函数,用以区分每个聚类中心的不同重要性;指数q和模糊因子m由粒子群优化算法(PSO-TVAC)优化所确定以降低陷入局部最优的可能性;为恰当刻画类内的紧致性和类间分离程度,新提出一种聚类评价标准ACVI,并作为PSO-TVAC算法的适应度函数以提高聚类准确率。其次,针对传统的聚类算法分类时会倾向于多数类的缺点,本文将新提出的CWAFCM算法与过采样技术(SMOTE)相结合以适应于对不平衡数据聚类。通过对六个数据集(四个平衡数据集,两个不平衡数据集)进行仿真实验,结果表明CWFCM算法能够有效地优化聚类效果,且能提高不平衡数据集的聚类准确率。
2. 传统的FCM算法与SMOTE技术
2.1. 模糊c均值算法(FCM)
FCM算法主要通过迭代方式最小化其目标函数以获得样本集的模糊划分,它将靠近聚类中心的样本点赋予较高的隶属度,而远离聚类中心的样本点赋予较低的隶属度。设
是数据集,n是样本数,c是已知的类别数。传统的FCM算法以欧氏距离作为相似度度量,其目标函数为:
(1)
其中
表示第i个样本点,
表示第j个聚类中心,
代表欧氏距离,m为模糊因子,用来控制聚类结果的模糊程度和函数的凸性,一般取值为2,
代表第i个样本点属于第j个聚类中心的隶属度,满足约束条件
(2)
令
表示模糊隶属度矩阵,
是所有聚类中心的集合。FCM算法通过迭代更新隶属度矩阵与聚类中心以实现聚类的目的,其迭代公式为
(3)
(4)
由式(1),FCM算法的目标函数可以改写为
(5)
即每个样本点和它的类中心之间的模糊距离系数为1,这说明传统FCM算法中每个样本点对目标函数的贡献是同等重要的,即使该样本点是噪声或离群点,显然这与实际情况不符。考虑到每个样本点的不同重要性,文献 [11] 提出了一种改进的AFCM算法,通过引入了一个权重向量
,来刻画每个样本点的重要性。其目标函数为
(6)
这里每一个
,
为样本
的自适应权重,
,
,满足约束条件:
(7)
参数p表示自适应指数,用来控制自适应权值。AFCM算法的聚类中心和权重向量的迭代公式为式(8)和式(9),隶属度更新公式与式(3)相同,
(8)
(9)
AFCM算法有效减少了噪声点的干扰,也适应于样本分布不均衡的情况。
2.2. SMOTE技术
现实生活中,常常会产生不平衡的数据集,如广告点击、信用卡欺诈等信息数据,而经典的聚类算法倾向于将样本划分到多数类,这将导致聚类结果不可靠。对于不平衡数据的处理有两个方向:一是数据层面的,通过改变数据分布使类别更为平衡;二是算法层面的,通过改进聚类算法使模型更看重少数类,如在传统分类算法的基础上对不同类别采取不同的加权值。
合成少类过采样技术(SMOTE)是一种基于数据层面的处理不平衡数据的方法。其目的是针对少数类样本的特征进行分析,同时合成新样本加入少数类样本,从而平衡数据分布。SMOTE算法的流程如下:
1) 在少类样本中选取样本
,计算
到每个少类样本的欧氏距离,选取K个距离最小的样本作为K近邻。
2) 根据多类样本与少类样本之间的不平衡比率确定采样倍率N,对于少类中的每个样本
,从其K近邻中选取若干个样本,不妨设为
。
3) 对于每个随机选择出的
与原样本
,按照式(10),合成的新样本
。
(10)
3. 基于PSO-TVAC的中心自适应权的FCM算法
AFCM [11] 算法启示我们,在聚类过程中将每个样本区别以待可以减少噪声干扰,提高算法性能。同样,FCM算法中,聚类中心起着非常重要的作用,它决定了最终的聚类结果,但其结果依赖于初始中心的选取。为减少这种依赖性,本文将强调每个中心的重要性,提出一种基于PSO-TVAC的中心自适应权的FCM聚类算法(CWAFCM)。
3.1. 中心自适应权的FCM模型
由式(1),FCM算法的目标函数可以改写为
, (11)
即每个类中心和所有样本点之间的模糊距离系数为1,这说明传统的FCM算法中每个中心都被平等看待,这将最终影响聚类有效性。本文将通过中心引入权重的方法来提高算法的鲁棒性和聚类效果。CWAFCM算法的目标函数为
(12)
其中
表示第j个聚类中心的权重,
组成中心自适应权重向量
,q为中心权重的自适应指数。满足
,
。用拉格朗日插值法得到拉格朗日函数为
在
中对
求偏导并令其等于0有
因为有
,代入上式可以得到使式(12)达到最小的充要条件
(13)
(14)
式(13)和式(14)是隶属度和中心权重的更新迭代公式,聚类中心的更新公式则与式(4)一样。比较式(3)和(13),CWAFCM模型中的隶属度随权向量φ的改变而改变。
3.2. 聚类有效性指标
聚类有效性指标是一种用来度量聚类效果的评价函数。常用的有效性指标有Xie Beni指标(CVIXB) [12],标准互信息(NMI) [13],聚类准确率(Accuracy),召回率,F1值等。考虑到FCM聚类过程中不同中心的重要性不同,本文提出一种改进的Xie-Beni指标ACVI。令
(15)
ASPT为类间最小加权距离,反映类间分离程度,其值越大越好;ACOMP为类内平均模糊距离,反映类内紧致程度,其值越小越好。因此作为比值,ACVI的值越小表示聚类效果越好。
3.3. PSO-TVAC算法
CWAFCM算法中,模糊因子m和自适应指数q是影响聚类结果的关键参数。恰当取值不仅可以降低算法陷入局部最优的可能性,还能提高聚类准确度。带时变加速度的粒子群算法(PSO-TVAC) [14] 因其算法简单,搜索速度快,效率高等优点被广泛用于参数优化问题。本文采用PSO-TVAC来优化参数m和q,其适应度函数采用本文提出的聚类指标ACVI。PSO-TVAC算法的速度和位置更新公式如下:
(16)
(17)
其中
和
分别表示搜索空间中第t次迭代时的速度
和位置
,
为惯性权重,
为加速度系数,计算公式为
(18)
(19)
(20)
其中
,iter为迭代次数,
为最大迭代次数;
,
(
,
)表示
,
初值(终值),
,
。
为分量在(0, 1)之间的随机向量,
表示在t时刻的第i个粒子的历史最佳位置,
表示t时刻的全局最佳位置。
3.4. CWAFCM算法的流程
这里我们给出CWAFCM算法的流程:首先用PSO-TVAC算法优化参数m, q,采用适应度函数ACVI;其次以式(12)为目标函数进行聚类。具体步骤为:
输入:数据集和聚类中心数c;聚类最大迭代次数Itermax;PSO算法最大迭代次数Itermax。
输出:聚类结果
1) 初始化关于m, q的粒子种群X;初始化隶属度矩阵U,中心权重向量φ;计算聚类中心向量V;设置相关参数,收敛阈值eps;
2) 随机初始化每个粒子的速度Vi和位置Xi;
3) 根据式(13)、(14)、(4)更新U, φ, V;
4) 用式(15)计算每个粒子的适应度值ACVI(Xi(t)),并得到Pi和Pg;
5) 根据公式(18)、(19)和(20)计算
;用式(16)和(17)更新粒子的速度Vi和位置Xi;
6) 当达到最大迭代次数Itermax或者
时,回到第三步,直到达到Itermax;
7) 得到全局最优粒子
;
8) 初始化隶属度函数U和中心权重向量φ,通过式(4)计算聚类中心V;
9) 通过式(4)、(13)、(14)更新聚类中心,隶属度和中心权重;
10) 当整个算法收敛时则得到最终聚类中心和每个粒子的隶属度。
4. 仿真实验与结果分析
4.1. 数据集与对比算法
为了验证新提出的算法的性能,本文选用了四个平衡数据和两个不平衡的数据集进行实验,见表1。对于不平衡数据,事先用SMOTE技术改变数据分布使类别平衡。为说明改进的算法有较好的聚类能力,传统的FCM算法 [15],改进的AFCM算法 [11],最近的JDFCM算法 [8] 用来作对比实验。

Table 1. Distribution characteristics of six datasets
表1. 六个数据集的分布特征
4.2. 实验参数的设置
文本提出改进的FCM算法的仿真过程分为两部分,首先是利用PSO-TVAC算法对模糊因子m、自适应参数q进行优化,得到最优的全局最优粒子
,然后基于最优的m, q值通过CAFCM算法得到最终聚类结果。在实验过程中,每个样本隶属度初始值是[0, 1]之间的随机数,中心权重向量
初始值为全1向量;聚类过程中的最大迭代次数Itermax为200,收敛阈值eps为10−5。在PSO算法的过程中,最大迭代次数Itermax设置为20,种群大小为20,粒子在二维搜索空间中移动。由于算法的结果与随机产生的初始值有关,本文中的所有实验都是独立重复30 次,以消除随机性的影响,然后给出平均值。在每个数据集上,通过PSO-TVAC算法优化得到的m, q的值列在表2中。
Table 2. m, q values by PSO_TVAC algorithm
表2. 由PSO-TVAC算法确定的m, q值
4.3. 实验结果分析
为了实验对比的公平性,本文选取常见聚类有效性指标:Xie Beni指标(CVIXB)、聚类准确率(Accuracy)、标准互信息(NMI)。CVIXB值越小、Accuracy和NMI越大说明聚类效果越好。而对不平衡数据,增加精确率,召回率和F1值三个指标以说明新算法可以降低对多数类的倾向性。实验结果由表3~8和图1给出。在数据集IRIS上,新算法CWAFCM在指标CVIXB和NMI都优于另外几种算法,但Accuracy上略差于JDFCM而与AFCM相同;在SONAR上,CWAFCM在Accuracy和NMI指标上都明显优于另外三种算法,CVIXB值在四种算法中排第二;在GLASS中,CWAFCM的Accuracy和NMI都排名第一;在WEKA中,CWAFCM有较为优异的Accuracy值,NMI略逊于AFCM算法。对于不平衡数据集,在Twomoons上,CWAFCM仅有CVIXB和Precision略逊于AFCM。在Spiral上,CWAFCM仅有Precision低于AFCM。为进一步说明实验结果的有效性,图1给出了不同的算法在四个不同数据集上的收敛曲线,曲线表明每种算法都有较快的收敛速度。综上所述,新算法CWAFCM在六个数据上相对于三种对比算法有较好的聚类效果。
Table 3. CVIXB, Accuracy, NMI on IRIS
表3. 在IRIS上的CVIXB Accuracy, NMI
Table 4. CVIXB, Accuracy, NMI on SONAR
表4. 在SONAR上的CVIXB Accuracy, NMI
Table 5. CVIXB, Accuracy, NMI on GLASS
表5. 在GLASS上的CVIXB Accuracy, NMI
Table 6. CVIXB, Accuracy, NMI on WEKA
表6. 在WEKA上的CVIXB Accuracy, NMI
Table 7. CVIXB, Accuracy, NMI, Recall, Precision and F1 value on Twomoons
表7. 在Twomoons数据集上的CVIXB, Accuracy, NMI, Recall, Precision和F1-value
Table 8. CVIXB, Accuracy, NMI, Recall, Precision and F1 value on Spiral
表8. 在Spiral数据集上的CVIXB, Accuracy, NMI, Recall, Precision和F1-value
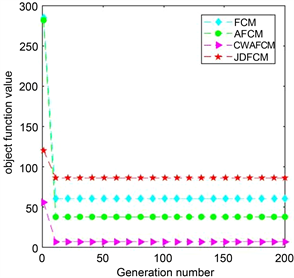 (a) 在IRIS数据集的收敛曲线
(a) 在IRIS数据集的收敛曲线 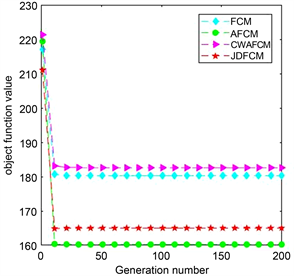 (b) 在SONAR数据集的收敛曲线
(b) 在SONAR数据集的收敛曲线 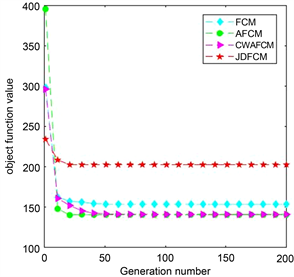 (c) 在GLASS数据集的收敛曲线
(c) 在GLASS数据集的收敛曲线 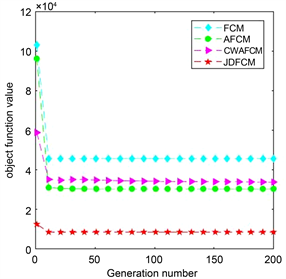 (d) 在WEKA数据集的收敛曲线
(d) 在WEKA数据集的收敛曲线
Figure 1. Convergence curves of each algorithm on different datasets
图1. 不同数据集下各算法的收敛曲线
5. 结论
传统的FCM算法表现出依赖于初始聚类中心、对噪声敏感、容易陷入局部最优、分类时会倾向于多数类等不足。考虑到每个聚类中心在聚类过程中不同的重要性,本文提出一种基于PSO-TVAC的中心自适应权的FCM聚类算法(CWAFCM)。每个聚类中心的不同重要性用权重向量
来刻画,自适应指数m, q来控制目标函数的凸性和聚类的模糊性,作为关键参数它们由PSO-TVAC算法所确定;为提高聚类准确度,一种新的聚类评价标准ACVI作为PSO-TVAC算法的适应度函数。对于不平衡数据,本文将CWAFCM与过采样技术(SMOTE)相结合,以实现对不平衡数据的聚类。通过在六个数据集上(四个平衡数据集,两个不平衡数据集)和三个对比算法的对比实验,结果表明CWAFCM算法能够有效地优化聚类效果,且能提高不平衡数据集的聚类准确率。这说明新算法能有效地降低对初始中心的依赖和噪声的干扰,减少陷入局部最优的可能。
基金项目
本项目由国家自然科学基金项目:61873169资助。