1. 引言
作为一种影响巨大、变数多样的袭击活动,恐怖主义现象在国外管理科学界得到了高度关注,涌现了大量相关研究成果,研究范围包括理论研究、事例研究以及恐怖事件类型研究,其中跨学科介入恐怖主义研究的成果也比较多 [1]。关于恐怖主义的研究主要集中于三个方面,一是对恐怖主义定义及其内涵的研究,二是从不同学科视角对恐怖主义进行研究,再有就是对不同恐怖袭击方式以及恐怖主义发生区域的研究。
定性研究是国内外研究恐怖主义的主流方法,通常将恐怖主义与经济学、社会学、心理学或政治理论相结合,集中在文献分析法、历史研究法和比较研究法上。Ordu [2] 探讨伊斯兰博科圣地和尼日尔三角洲武装分子在尼日利亚的趋势和模式,分析社会结构和政治经济对恐怖袭击的影响。李丽华等 [3] 以2017年英国发生的暴恐事件为研究对象,从舆情传播主体、信息特征以及传播特征角度得出预防和控制的结论。刘乐 [4] 以伊斯兰国组织为代表的恐怖主义力量对于主流社会意义体系的侵蚀消解和冲击动摇为案例,给出国际社会重构反恐时代意义体系的根本战略。周秋君 [5] 追溯恐怖主义在当代欧洲的发展轨迹,对恐怖主义发展的新态势及其变化的原因展开分析。Oliveira等 [6] 采用内容分析方法研究巴塞罗那和坎布里尔斯的目的地营销组织对于恐怖袭击采取的行动。
风险评估和数学建模理论为恐怖主义量化分析或模型构建提供了方法,包括博弈论优化建模、复杂社会网络规划建模、可视化技术与计量建模等 [7]。付举磊等 [8] 使用社会网络理论构建“事件–时间–空间”关系网络模型,结合地理信息系统技术,分析东突恐怖活动的时空特征。王雷 [9] 等提出基于和声搜索算法优化的支持向量机的分级模型,对我国2008~2013年的突发暴恐事件进行分级研究。Estrada等 [10] 提出恐怖行动的三个阶段,引入风险指标估计可能影响区域经济绩效的潜在恐怖事件因素。郭璇等 [11] 提出基于事件树和概率风险分析的民航机场恐怖袭击风险评估模型,以降低民航机场恐怖袭击事件发生的概率和风险。Buscema等 [12] 使用基于拓扑的方法对受重大系统性恐怖主义活动影响并具有全球地缘政治影响的国家进行测试,预测恐怖袭击的空间模式。Lanouar等 [13] 使用马尔可夫机制转换模型研究恐怖袭击和政治暴力对突尼斯入境游客和过夜人数的影响。何晶等 [14] 提出一种基于多局域的恐怖组织网络择优增长演化模型以模拟恐怖组织网络的动态演化规律。宋艳等 [15] 研究了恐怖袭击事件下,政府和极端组织作为参与者基于现存设施布局的博弈选址问题。
以上工作的研究主要是特定场景下恐怖袭击事件的分析或风险评估,以及恐怖组织的行为分析和预测等问题。关于恐怖袭击风险问题,从研究背景来看,主要集中在事件信息的危害性评估和分级上,较少有基于面板数据框架的地区涉恐安全风险的研究。本文依据全球恐怖主义数据库(GTD),运用空间统计方法对全球恐怖袭击事件发生的分异特征进行分析。从恐怖袭击危害性的角度,选取恐怖袭击事件数、恐怖袭击死亡人数、恐怖袭击受伤人数和恐怖袭击财产损害程度等指标构建地区涉恐安全风险评估指标体系,提出基于密度敏感稳健模糊核主成分分析(DRF-KPCA)的多维面板数据的分级模型。结合主成分方法提取出来的风险水平因子,运用最大似然估计方法建立随机效应面板顺序Logit模型,考察宏观经济和社会发展因素对地区涉恐安全风险的影响,并对回归模型进行预测绩效评价。
本文余下部分的结构安排如下:第2节给出地区涉恐安全风险评估与影响因素研究的方法;第3节是地区概况;第4节的实证研究中给出基于DRF-KPCA技术提取的地区涉恐安全风险分级结果,并建立非线性面板数学模型进行影响因素研究;第5节是结论。
2. 研究方法
2.1. 密度敏感稳健模糊核主成分分析算法
密度敏感稳健模糊核主成分分析(DRF-KPCA)算法扩展自RKF-PCA算法,通过引入相对密度获取初始隶属度,以及优化重构误差算法自适应地对样本进行隶属度加权,同时利用核方法对数据中非线性信息提取的优势,得到更有效率、更稳健地特征提取 [16]。
设样本集
,核函数通过变换
将样本
映射到特征空间中的
,赋予隶属度
后可得空间中的协方差矩阵
为
(1)
其中p是模糊度系数,
,
。
令
是
属于特征值
的特征向量,即有
(2)
通常情况
难以直接通过计算获取,可定义一个
的矩阵
,如式(3)所示
(3)
其中
,
。综合式(1)和(2)得
(4)
(5)
这里
,
,
。
解式(3)、(4)和(5)就能得到特征值和特征向量,测试样本在特征空间中的投影为
(6)
在重构误差意义上,DRF-KPCA可以表示为以下模型
(7)
其中
为由前q个最大特征值对应的特征向量构成的投影矩阵,
为单位矩阵,
为正则化控制参数。
通过优化理论中的拉格朗日方程,隶属度
有式(8)的解析形式
(8)
分析式(7)和(8)可以发现,对重构误差较大的样本,其隶属度随着重构误差增大而取值越小,而重构误差较小的样本其隶属度取值较大。
为解决PCA算法对初始值敏感的问题,文献 [16] 引入相对密度获取样本初始隶属度,训练样本
的相对密度
定义如下
(9)
其中
,
,
为权重,s是Parzen-window的平滑参数。
2.2. 基于DRF-KPCA的多维面板数据的聚类分级
为保证重构空间准确地描述系统状态的演化轨迹,通常会选择多维面板数据为研究对象。当多个指标变量所代表的状态间相关性较强时,需要先对面板数据进行降维后才能进行聚类分析 [17]。
假定有m个研究对象组成聚类集合
,其中矩阵
,这里
表示第i个研究对象在第t个时间内的第j个指标数值(
,
,
)。通常,不同指标数值之间差异明显,于是令
(10)
其中
,
。即用标准化数据代替原始尺度,以消除
各指标间量纲的影响,则第t个时间内研究对象的指标矩阵为
(11)
通过运行DRF-KPCA算法获得
在低维上的映射
(12)
这里对每个截面矩阵取z个指标主成分,使得累计方差贡献率达到85%以上。根据多维面板数据的聚类思想,计算各个时间截面的样本综合评价函数,如下所示
(13)
其中
为第i个研究对象在第t个时间内的综合评价函数,指标主成分贡献率为
(14)
这里
为协方差矩阵的特征值,并且将其排列,即
。
最后构建综合评价函数序列矩阵
(15)
选择欧式距离
来表示第i个对象与第j个对象之间的差异,从而对
面板数据进行层次聚类,基于DRF-KPCA的多维面板数据的聚类算法流程见表1。

Table 1. Algorithm flow of “DRF-KPCA + Hierarchical Clustering”
表1. “DRF-KPCA + 层次聚类”算法流程
2.3. 基于DRF-KPCA的面板顺序Logit模型
由基于DRF-KPCA的多维面板数据的聚类分级,我们得到关于研究对象的定性分类结果,如果我们还关心影响分类结果的因素贡献,可以引入离散变量构建面板多值选择模型。Logit回归是一种分类模型,采用Sigmoid函数作为后验概率分布函数对数据集进行分类。面板Logit模型由于同时使用截面数据和时间序列数据,既可以控制个体异质性,也可以对风险进行预警,从模型中分析影响风险的因素 [18]。
假设风险状态被设定为一个不可观测的潜在变量
,而
为可观察到的风险的分类状态,
为每一风险状态下的阈值。因此,分类状态
可以看作潜在变量
和阈值r共同生成的离散变量,构建的顺序Logit模型如下
(16)
(17)
其中
,
,
,
是用来描述第i个研究对象在第t个时间内可观测特征的解释向量,
是回归系数。
为不随时间改变及不可观测且对潜在变量有影响的个体效应,用于刻画不同对象的个体异质性。
为随机干扰项,服从Logistic分布,其累积分布函数为
(18)
假设
的密度函数为
,第i个对象的条件分布为
(19)
其中
(20)
(21)
(22)
(23)
(24)
这里
,
,
。于是,
的概率密度
(25)
假设不同研究对象的观测值相互独立,则构建顺序Logit模型的对数似然函数为
(26)
施加概率和为1的约束
,最大化此似然函数,即得到对
的随机效应Logit估计量。上述积分没有解析解,可以使用Gauss-Hermite quadrature方法进行数值积分。
3. 地区概况
全球各地区1恐怖活动随时间变化趋势明显,呈现先起后伏状态,多在2014年出现峰值,如图1所示。南亚、中东和北非是恐怖袭击频发地区,发生数约占全球的70%。2004~2014年间,各地区恐怖袭击事件发生数差距开始逐渐拉大,撒哈拉以南的非洲年均涨幅为51%,中美洲和加勒比海区、中亚以及澳大利亚和大洋洲年均涨幅不足5%。近年来,随着各国提升对恐怖活动的应对能力与打击力度,恐怖活动及伤亡人数逐渐减少,2014~2018年中东和北非恐怖袭击事件发生数呈现逐年下降的趋势,年均降幅为19%,伤亡人数年均降幅为30%。
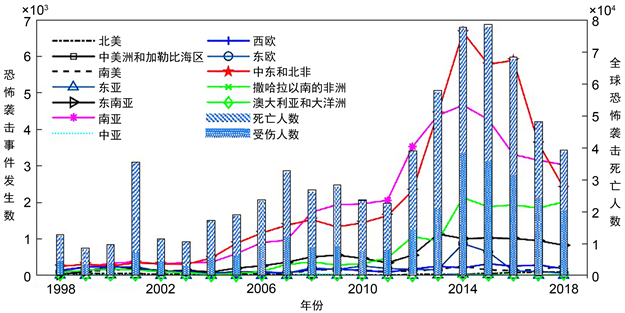
Figure 1. Statistics of terrorist attacks from 1998 to 2018
图1. 1998~2018年恐怖袭击事件统计
本文运用ArcGIS 10.5中的核密度分析工具,对1998~2007年和2008~2018年两个不同时期恐怖袭击事件发生的空间分布特征进行可视化处理,将核密度值按ArcGIS自然分级为低值区、较低值区、中值区、较高值区和高值区五类,值区代表颜色分别为白色、绿色、黄色、橙色和红色,见图2。
从核密度分布图看,全球恐怖袭击事件发生的总体空间分布格局没有明显变动的经历,主要分布在中东和北非、南亚和撒哈拉以南的非洲。1998~2007年较高值区和高值区集中在中东和北非、南亚,完全处于低值分布的地区有东亚、中亚以及澳大利亚和大洋洲,如图2(a)所示。2008~2018年核密度值出现不同幅度的上升,已没有完全处于低值分布的地区,处于低值和较低值分布的地区有中美洲和加勒比海区、东亚、中亚以及澳大利亚和大洋洲,中值、较高值和高值区数量增加,东南亚和东欧逐渐出现高值与较高值区域,见图2(b)。
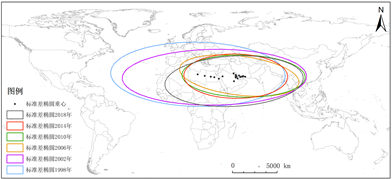
其次,基于ArcGIS10.5,利用标准差椭圆法定量分析1998~2018年恐怖袭击事件发生的总体轮廓和其所主导的方向,地图可视化结果见图3(a),参数结果见图3(b)。
1998~2006年标准差椭圆重心表现为东西方向扩张强度明显大于南北方向,总位移约为3417 km,其中向东移动约3439 km,向南移动约111 km。在这一阶段,椭圆方位角为向北偏西转移约6˚,长轴与短轴均减小,椭圆总体分布范围在缩小。2007~2018年标准差椭圆重心的空间移动范围较小,总位移约为665 km,表明恐怖袭击活动空间聚集性较强,椭圆方位角表现为向北偏东转移约10˚,长轴与短轴均增加,恐怖袭击空间分布存在逐渐增大的趋势。
1998~2018年全球恐怖袭击事件空间格局可概括为先向北偏西转移,后向北偏东转移,整体呈现向北偏东移动的格局,且恐怖袭击事件发生的空间分布呈现先缩小后逐渐扩大趋势,中东和北非以及南亚的大部分国家一直处在椭圆内部。
 (a)
(a)  (b)
(b)
Figure 2. Nuclear density distribution of terrorist attacks from 1998 to 2018. (a) 1998~2007 year; (b) 2008~2018 year
图2. 1998~2018年恐怖袭击事件的核密度分布。(a) 1998~2007年;(b) 2008~2018年
 (a)
(a) 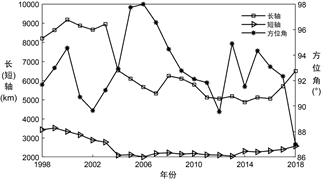 (b)
(b)
Figure 3. Standard deviation ellipse spatial distribution of terrorist attacks from 1998 to 2018. (a) Standard deviation ellipse and center of gravity shift; (b) Long and short axis and azimuth change
图3. 1998~2018年恐怖袭击事件的标准差椭圆空间分布。(a) 标准差椭圆和重心转移;(b) 长短轴和方位角变化
4. 地区涉恐安全风险评估与影响因素研究
4.1. 地区涉恐安全风险评估
地区涉恐安全风险水平的确定主要依赖对恐怖袭击事件破坏后果的统计,在参考先前的研究 [1] [9] [19] [20] [21] [22] [23],考虑人员死亡和经济损失等与恐怖袭击危害性紧密相关的主要变量后,构建地区涉恐安全风险评估指标体系。体系分为二层,目标层为地区涉恐安全风险评估,指标层包含恐怖袭击事件发生数、恐怖袭击死亡人数、恐怖袭击受伤人数、财产损害程度2、凶手数量、凶手死亡人数、凶手受伤人数、人质/绑架受害者人数和亡人事件百分比3。
本文聚类采用GTD中1998~2018年12个地区的恐怖袭击事件样本数据,剔除变量数据不完善的事件后,共有样本事件118,084条。通过对数据进行标准化处理后,获得统一形式的数据表示,随后对数据采用DRF-KPCA算法进行降维处理,获得关键特征。
为了比较DRF-KPCA与其他主成分算法 [24] [25] 提取数据特征的能力,给出2018年相同数目的主成分所能解释的累计方差百分比,如表2所示。从表2中可以看出数目相同的非线性主成分比线性主成分能够获取更多的累计方差百分比,即能获取更多数据信息的同时,抑制离群点所带来的干扰。
Table 2. The cumulative percentage variance explained by the same number of principal components (2018)
表2. 相同数目的主成分所能解释的累计方差百分比(2018年)4
表3为1998~2018年12个地区涉恐安全风险水平的排序结果,地区排序号越大,即地区涉恐安全风险水平越高,意味着恐怖主义对地区安全的影响越大,地区安全态势越动荡;反之地区排序号越小,恐怖主义对地区安全的影响较小,则地区处于相对安全的态势水平。1998~2018年澳大利亚和大洋洲、西欧、北美以及中美洲和加勒比海区排序位置靠前,南亚、中东和北非以及撒哈拉以南的非洲排序位置在后,东南亚、南亚、中东和北非以及撒哈拉以南的非洲排序结果总体上比较稳定,东亚、东欧以及中美洲和加勒比海区排序结果的变化相对明显。
Table 3. Regional ranking results of terrorism-related safety risk level
表3. 涉恐安全风险水平地区排序结果
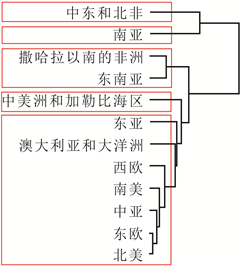
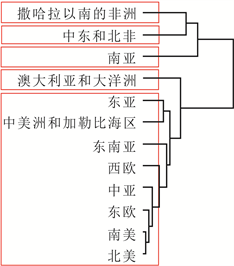
为验证本文构建的“DRF-KPCA + 层次聚类”集成方法对于处理地区涉恐安全风险数据的聚类问题的有效性和合理性,本文将直接使用层次聚类和先使用传统PCA降维再进行聚类(记为“PCA + 层次聚类”)两种方法作为对照,分析聚类结果5。为了更好地表示分级结果,本文将数据集分为1998-2004年、2005~2011年和2012~2018年三段,得到地区涉恐安全风险的五个等级,分别为低风险、较低风险、中风险、较高风险和高风险,具体见图4、图5和图6。
从这些图可以看出,相较于层次聚类和“PCA + 层次聚类”方法,使用“DRF-KPCA + 层次聚类”方法得到的聚类结果具有明显的层次性和差异性,且与实际情况比较符合,一定程度上说明本文构建的
 (a)
(a) 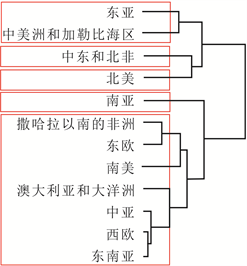 (b)
(b)  (c)
(c)
Figure 4. Comparison of three clustering structures from 1998 to 2004. (a) Hierarchical clustering; (b) PCA + hierarchical clustering; (c) DRF-KPCA + hierarchical clustering
图4. 1998~2004年三种聚类结构对比。(a) 层次聚类;(b) PCA + 层次聚类;(c) DRF-KPCA + 层次聚类
 (a)
(a) 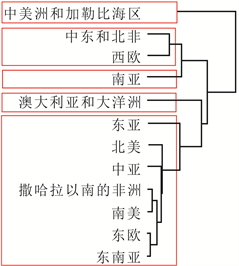 (b)
(b) 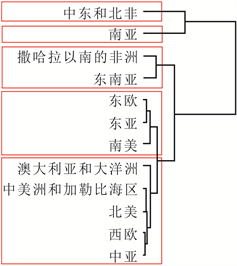 (c)
(c)
Figure 5. Comparison of three clustering structures from 2005 to 2011. (a) Hierarchical clustering; (b) PCA + hierarchical clustering; (c) DRF-KPCA + hierarchical clustering
图5. 2005~2011年三种聚类结构对比。(a) 层次聚类;(b) PCA + 层次聚类;(c) DRF-KPCA + 层次聚类
 (a)
(a) 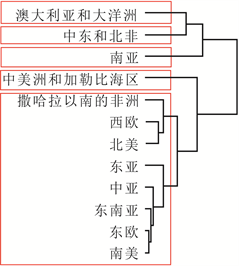 (b)
(b) 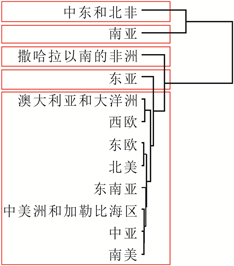 (c)
(c)
Figure 6. Comparison of three clustering structures from 2012 to 2018. (a) Hierarchical clustering; (b) PCA + hierarchical clustering; (c) DRF-KPCA + hierarchical clustering
图6. 2012~2018年三种聚类结构对比。(a) 层次聚类;(b) PCA + 层次聚类;(c) DRF-KPCA + 层次聚类
Table 4. Regional terrorism-related safety risk classification results under “DRF-KPCA + hierarchical clustering”
表4. “DRF-KPCA + 层次聚类”下地区涉恐安全风险分级结果
“DRF-KPCA + 层次聚类”方法在处理地区涉恐安全风险多维面板数据的聚类分级上显示出更准确合理的性能,表4报告了这三个时间段的地区风险分级结果。1998~2018年涉恐安全风险等级没有变化的地区是中美洲和加勒比海区(低风险)、澳大利亚和大洋洲(低风险)以及撒哈拉以南的非洲(中风险)。在这一阶段,南美、东欧和东南亚安全风险等级显著下降,从中风险变为低风险,北美、中亚和西欧从较低风险变为低风险,南亚从高风险变为较高风险,这说明安全新秩序的建构和反恐的团结合作使得一些地区的涉恐安全风险程度下降。结合表4可知,1998~2018年不存在涉恐安全风险表现为显著增长的地区,东亚从低风险变为较低风险,中东和北非从较高风险变为高风险,这说明对地区安全构成威胁的因素依然可能是不稳定的政情、资源的争夺和局部武装冲突的不断。
4.2. 地区涉恐安全风险的影响因素分析
本文选取“DRF-KPCA + 层次聚类”分级结果作为被解释变量,关于地区涉恐安全风险水平的主要影响因素,结合《国际安全态势感知指数2017》报告和数据的可得性,确定人均国内生产总值、资产形成总额占比、军费支出占比、政府消费最终支出占比、航空运输货运量、人口增长率以及货物和服务出口占比作为地区涉恐安全风险的影响指标。这些变量的数据来源于世界银行的官方网站,回归模型样本时间区间是2009~2018年。
基于DRF-KPCA的多维面板数据分级模型,我们得到地区的涉恐安全风险水平(0 = 低风险、1 = 中风险、2 = 高风险)6。Mundlak [26] 指出,一般情况下都应该将个体效应视为随机的,试图区分随机效应、固定效应本身就是存在问题的。由于LR检验结果显示在5%显著性水平下拒绝原假设,且固定效应顺序Logit 模型的回归结果中解释变量都不显著,我们最终以随机效应顺序Logit模型对考察期内地区面板数据进行回归,如表5所示。根据模型数值积分稳健性检验结果显示变量前的系数估计值相对差距均没有超过10−4,说明数值积分结果是稳健的。
模型的回归结果中解释变量都不显著,我们最终以随机效应顺序Logit模型对考察期内地区面板数据进行回归,如表5所示。根据模型数值积分稳健性检验结果显示变量前的系数估计值相对差距均没有超过10−4,说明数值积分结果是稳健的。
由虚拟响应变量理论可以得出,Logit模型并非表示解释变量与响应变量之间的直接关系,而是间接地表明解释变量对地区涉恐安全风险发生概率的影响。人均国内生产总值、军费支出占比、政府消费最终支出占比和人口增长率这四项变量指标通过统计检验,表明这些指标对地区涉恐安全风险的发生有着明显影响。军费支出占比和人口增长率与地区涉恐安全风险的发生呈现显著的正相关关系,即军费支出占比和人口增长率的增加对地区涉恐安全风险的上升起到明显的推动作用,模型中军费支出占比对风险的影响大于其它指标。人均国内生产总值和政府消费最终支出占比与地区涉恐安全风险的发生呈现显著的负相关关系,即它们对地区涉恐安全风险的上升起到明显的抑制作用。资产形成总额占比、航空运输货运量与货物和服务出口占比则与地区涉恐安全风险之间的关系不明显。
军费支出占比的提高,一定程度上为地区扩大军购提供资金来源,落伍军备的更新和防务能力的提升成为地区间军备竞赛的重要驱动力,差别的存在可能导致社会的失序,损害地区的公共安全和社会稳定。人口增长速度的加快,对于一些政策失误或状况混乱的地区,很可能加剧既有的生存空间之争和社会矛盾,对社会治理带来潜在的负面影响。恐怖袭击事件频发区多数为经济发展落后的地区,人民生存物质条件的保证和生活条件的改善可以减少部分袭击事件的极端化。
Table 5. Estimated results of panel order Logit model
表5. 面板顺序Logit模型估计结果
注:***表示在1%水平显著,*表示在10%水平显著。
本文以分类精确率(PR)、召回率(RE)以及F1值为评价指标,计算公式定义为 [27]
式中,k为聚类个数,ai为正确分到第i类的样本数,bi为误分到第i类的样本数,ci为应该分到第i类却没有分到的样本数,pi为第i类样本的比例。
对构建的Logit回归分类模型进行预测效果对比检验,结果见表6所示。可以发现,先用DRF-KPCA进行降维再层次聚类,然后用Logit回归分类的效果优于其他两个组合得到的分类效果。本文所采用的组合在样本内有较高的预测准确性,精确率、召回率和F1值均达到75%以上。
Table 6. Classification and comparison results of order Logit model
表6. 顺序Logit模型的分类对比结果
5. 结语
如何展开地区涉恐安全风险评估与影响因素研究已经成为在研判地区未来的反恐态势、配置反恐资源时考虑的重要问题。本文基于DRF-KPCA和非线性面板模型对地区涉恐安全风险进行量化评估和影响因素研究,具有较强的信息挖掘和确定风险控制措施的作用。
本文首先借助空间统计方法,分时段明确地区恐怖袭击事件发生态势,以可视化方式实现安全预警。接着提出一种适用于地区涉恐安全风险量化评估的多维面板数据统计算法,通过计算每个地区截面的主成分因子实现了对各时间节点上的量化评估,获得的特征向量集为后续的分类提供了基础。与其他的主成分聚类算法相比较,文中所提算法的合理性和准确度都有提升。结合主成分方法提取出来的安全风险级别因子,运用最大似然估计方法建立随机效应面板顺序Logit模型,考察宏观经济和社会发展因素对地区涉恐安全风险水平的影响,结果显示模型辨识了大部分的地区涉恐安全风险等级,同时给出因素在地区涉恐安全风险水平确定中的作用机理,可以适应反恐风险监测及预警技术的需要。
基金项目
上海市重点学科项目(T0502);沪江基金资助项目(B14005)。
NOTES
1本文采用的地区数据来自GTD全球恐怖主义数据库,涵盖了12类地区,1 = 北美,2 = 中美洲和加勒比海区,3 = 南美,4 = 东亚,5 = 东南亚,6 = 南亚,7 = 中亚,8 = 西欧,9 = 东欧,10 = 中东和北非,11 = 撒哈拉以南的非洲,12 = 澳大利亚和大洋洲。
2财产损害程度是分类变量,本文中地区财产损害程度的计算方法为:首先对财产损害程度变量取负号,作正向化处理,然后对每个损害程度类别,计算恐怖袭击事件发生数占地区恐怖袭击事件发生总数的百分比,最后在此基础上,以比值为权重计算地区财产损害程度。
3地区亡人事件百分比是以“存在死亡人员的恐怖袭击事件数/全部恐怖袭击事件数”的比值度量,是衡量恐怖袭击活动危害性的一个重要指标。
4文中给出2018年相同数目的主成分所能解释的累计方差百分比,实际上,对于其他年份也可以进行类似比较和解释。
5“KPCA+层次聚类”和“RKF-PCA + 层次聚类”有与“DRF-KPCA + 层次聚类”类似的结果,考虑到算法的运行效率和篇幅所限,本文不列出“KPCA + 层次聚类”和“RKF-PCA + 层次聚类”的结构图。
6本文在非线性面板模型构建中保留地区分析框架的同时,剔除地区中数据缺失的国家,这种情况使得基于DRF-KPCA的地区涉恐安全风险分为三级,分别用代码0、1和2表示。