1. 引言
贫困是世界性的发展难题,特别是发展中国家的贫困治理,常常出现各类疑难杂症。自新中国成立,脱贫致富成为我国发展的首要任务。中国不断发挥自身的政治领导优势和强大的群众建设力量,在扶贫的道路上总结了大量实践经验和治理理论,取得了引人注目的成果。80年代中期,以县级单位作为扶贫起始点,到千禧年时,扶贫工作已深入到15万个村级区域 [1]。2013年之后,中国的扶贫事业在精准扶贫理念的指导下进入了新时期,全面打响了脱贫攻坚战。我国的贫困治理由面到点,由浅入深,在经济勃发的助力下,七年累计减贫幅度高达94.4% [2],最终在2020年这一关键时点,消除了绝对贫困,取得了扶贫工作的巨大胜利。
绝对贫困的消除意味着贫困治理需要从物质层面转向发展层面,即脱贫攻坚的重心将转向相对贫困 [3],但精准扶贫的痛点依旧阻碍着相对贫困的治理进程。在经济高速增长的大背景下,居民收入分配差距大、城乡二元经济结构等问题日益凸显,处于收入底层的贫困人群越来越难以享受到经济增长带来的红利,以区域瞄准为特征的农村扶贫也愈加乏力。在精准扶贫方面,困难在于贫困户的精准识别和精准帮扶。现有制度下,由于贫困识别仅以人均纯收入为标准线,再加上贫困人群基数大,基层政府往往难以承担高成本、高工作强度的农户收入精确统计;贫困识别的困难导致贫困户的建档立卡信息缺失,为解决这一问题而设立的基层民主评议,其评估的扶贫名额也出现了近半的高错误率 [4]。这些问题都说明,我国要实现可持续性脱贫,依旧任重而道远。
因此,研究如何利用和改进现有政策提高扶贫效率和质量,进而实现可持续脱贫目标具有社会现实意义。新型农村社会养老保险(以下简称“新农保”)作为社会养老保障体系的重要组成部分,旨在为农村人的老年生活提供社会基础保障,实现城乡基础服务均等化,缩小城乡差距和有效促进农村减贫。新农保政策因为联结了城乡问题和贫困治理两大难题,其政策效应和扶贫效用一直备受社会关注。
国内对新农保政策的研究主要集中在农村群体消费、储蓄、收入、养老模式等方面的变化。朱诗娥等学者研究发现新农保政策对居民消费的提升产生了显著的影响,保费缴纳额度每翻一倍,农户消费支出约提高5.9%,提高了农户对未来的收入预期。另有学者认为新农保养老金显著提升了农村老年人的收入水平、提高了其主观福利 [5],在一定程度上促进了家庭消费和减少了老年人劳动供给,且家庭生活越是贫困,新农保产生的边际效用就越大 [6]。再者,程令国等学者 [7] 从养老模式角度分析,发现新农保政策减少了参保老人对子女代际支持的依赖,增强了经济独立性,是传统养老模式向社会养老新型模式迈出的试探性一步 [6]。由于新农保普惠式、全覆盖的特点,在一定程度上降低了识别贫困对象的难度,从而提高了农村老年人的平均收入和消费水平。
基层政府缺乏资本和技术的支持,往往难以根据收入标准识别所有贫困人口 [4]。大多学者表明,多维度贫困指标的介入是解决这一问题的有效措施之一。基于当下国情,以单一的收入标准作为精准扶贫的识别已难以适应时代的需求。我国的可持续脱贫工作应当关注贫困人群收入、消费、健康、教育、心理等多个维度的贫困状况,社会保障体系在下一阶段也应更加侧重于精准扶贫,顺应国际扶贫的趋势,辅助建立缓解相对贫困、实现可持续性脱贫的长效机制。
综合国内研究,发现尽管大多学者都认可了新农保的积极作用,但少有对受影响群体进行细化分类,多维度多层次地精准狙击贫困治理的痛点。基于这一现实情况,本文利用CHARLS 2018年截面数据,从多个维度探讨了新农保政策的精准扶贫效用,有助于相关机构在新农保政策的基础上有方向性地开展精准扶贫工作,提高扶贫效率。
2. 研究方法与变量选取
2.1. 研究方法
本文通过对比不同组群的贫困指数,构建多维贫困指标测度体系,多维度多层次地识别贫困,以估计新农保政策的扶贫效用。在实际角度来看,由于农村老年人的参保行为是自我选择的结果,受到预期收入、消费偏好、思想观念等不可测因素影响,研究过程中可能存在“选择性偏误”等内生性问题,从而掩盖或夸大了指标对个体贫困程度的描述,使政策效应的估计产生偏差。除此之外,多维贫困指标无法解决估计政策效用时存在数据缺失问题,只能阐释样本个体处于某一种状态的贫困水平,无法分析个体处于另一状态的贫困水平,使得最终结论可能过于粗糙。
因此,准确预估新农保政策扶贫效果的关键是解决模型内生性问题。一般来说,增加变量可以缓解部分内生性问题,但是本文部分变量存在不可观测性和异质性,仍可能出现回归估计量非一致和模型“过低拟合”的问题。得分倾向匹配法(Propensity Score Matching,简称PSM)是解决内生性问题的常用方法,能够检验并解决样本中出现的选择性偏误问题,并且通过变量匹配,可以对项目进行效应评估,获得政策的平均处理效应。PSM法不要求既定的函数形式和随机误差分布,没有解释变量需严格外生的条件(王慧玲、孔荣,2019),在经济研究中广泛用于对公共政策效果的评估,估计结果的可信度和稳健性较高。
2.1.1. 多维贫困指标体系
本文参考Alkire和Foster提出的多维贫困测算方法,分析不同维度k下的相对贫困程度。主观选取四个维度九个指标建立体系的框架,各维度均分权重,并定义九个指标下的样本数据为一个剥夺矩阵 [8]。在剥夺矩阵的基础上,以“是否参与新农保”这一变量划分参保的处理组和未参保的控制组。在测算部分,计算处理组和控制组个体在单个维度以及多个维度下的贫困深度和被剥削程度,加总样本的贫困维度并分析比较贫困剥夺率和贫困发生率等指标,以此衡量新农保政策对农户相对贫困程度的影响效用。
国内外现有研究对多维贫困维度的选择以及各个维度被剥夺的临界值并无统一的标准,本文综合国内外研究和中国实际情况,选择如表1的维度、指标以及剥夺临界值。

Table 1. The election of multidimensional poverty index
表1. 多维贫困指标维度表
2.1.2. 新农保政策的效用方程
根据效用决策模型,以虚拟变量
表示个体 参与新农保政策的状态:
时,农户参加新农保;反之,则不参加新农保政策。
又被称为处理变量,表示个体i是否处于“处理”状态(Treatment)。定义
为个体i的贫困程度,
表示个体i参保时的贫困状态,则
表示个体i未参保时的贫困状态,以个体贫困维度数为表征。因此,为了探析
与
之间的因果关系,新农保政策的效用
就存在两种状态:
(1)
若
,这说明参与新农保政策的效用大于不参与的效用,那么基于理性经济人的假设,农户会选择参与,
;反之,则
。
2.1.3. 基于倾向得分匹配的鲁宾因果模型
为了进一步解决和控制不可测因素对模型的负面影响,Rubin (1974)基于倾向得分匹配法提出了鲁宾因果模型(Rubin Causal Model,简记RCM)。RCM模型能有效控制处理组和控制组分布的异质性,尽量控制样本的选择性偏误。针对多维贫困测度方法的缺陷,RCM模型能通过样本匹配估计参保个体的两种状态,即为处理组的每位个体i寻找控制组的相应匹配,有效解决数据缺失问题,测算新农保政策的效用。RCM模型建立步骤如下 [9]:
1) 选择协变量
。参考国内外相关研究,将影响农户参与新农保政策的相关因素作为协变量。
2) 估计倾向得分。国内研究一般选择Logit回归或Tobit回归计算倾向得分,但Logit回归形式更加灵活,可加入分析
的高次项,更加贴合本文所选协变量的特征。
3) 进行倾向得分匹配。倾向得分平衡性较好,对
进行匹配后则可以均衡样本在处理组和控制组之间的分布。目前学术界对于最优匹配方法尚无定论,因此本文利用五种主流匹配方法进行综合比较分析:① 近邻匹配,即将处理组中某个体与控制组中n个差异最小的样本进行匹配,本文设定n为4 (n = 4);② 半径匹配,又称卡尺匹配,对样本筛选和匹配有一定的半径范围和限制。经过计算,本文设定半径为0.01 (cal = 4);③ 卡尺内近邻匹配,即在卡尺(半径)为0.01的限制下进行一对四的匹配;④ 核匹配,根据不同样本个体的距离赋予不同权重,对距离进行加权平均,能够体现协变量的相似程度;⑤ 马氏匹配,计算在n = 4下的马氏距离。
4) 计算平均处理效应。在满足均值可忽略性假设条件下,本文选择更加贴合研究目的的处理组平均处理效应(ATT)进行分析,充分聚焦参保农户处于未参保状态时贫困程度的变化。ATT的表达式为:
(2)
式(2)中,
代表参与新农保政策的个体数;
表示新农保政策对参与个体效用的加总;
表示参与新农保政策个体未参与时的贫困程度估计值。
2.2. 变量选取
本文定义贫困程度为被解释变量,选择四个维度、九个指标,以贫困发生率、贫困剥夺份额和多维贫困指数表征总体的贫困状况,以个体贫困维度表征样本个体的贫困状况。核心解释变量是农户是否参与新农保政策的虚拟变量
,若参加,记作1;反之,记作0。
借鉴王慧玲等学者对政策影响变量选取 [10],本文以个体特征、家庭特征和区域特征等为控制变量,即协变量,厘清农户参与新农保政策的影响因素,进一步探究新农保政策对农户贫困程度的改善作用,评估新农保的政策效用。
3. 数据来源与实证分析
3.1. 数据来源与样本分布
本文选择2018年中国健康与养老追踪调查(China Health and Retirement Longitudinal Study, CHARLS)项目的全国基线调查截面数据,以保证样本的时效性和代表性 [11]。在排除无参保资格和相关信息缺失的样本个体后,以“是否参与新农保”的行为依据划分为已参保的处理组和未参保的控制组。处理后的样本数据一共包括4128个受访者,其中参与新农保的处理组个体为3239人,未参保的控制组个体为889位。
3.2. 多维贫困指标测算分析
本文根据多维贫困测量方法,计算了样本在不同维度k下的相对贫困程度。结果如表2显示,样本的贫困发生率和多维贫困指数随着贫困维度k值限制而增加。当控制贫困维度k = 3时,处理组的贫困发生率、贫困剥夺指数和多维贫困指数都大于控制组,两组多维贫困指数的差距为0.098,小于调整后的贫
Table 2. The result of Multidimensional Poverty Index
表2. 多维贫困测量结果
困发生率的组别差额0.109,可见处理组的贫困广度对样本贫困程度的影响更大。通过对比分析,当贫困维度控制在3时,贫困剥夺和分布的敏感度更高,相对更为科学客观。
测算结果中处理组的多维贫困指数始终高于控制组,这与新农保政策能带来扶贫效用的预期和假设不符。由于“是否参与新农保”这一行为很大程度上是农村老年人的自主性行为,加之存在遗漏变量和反向因果问题,上述结果则很可能是由有偏估计和选择性偏误等内生性问题导致。因此,下文将运用得分倾向匹配方法(PSM)以解决样本数据存在的内生性问题。
3.3. 新农保政策对扶贫效果的评估测算
3.3.1. PSM匹配结果分布
在处理组和控制组样本个体匹配得分的基础上,PSM利用样本个体参与新农保的倾向性的差值作为距离来对样本进行匹配,结果分布的如表3所示。在五种主流匹配方法的测算下,最大损失为67个样本,保留了3786个匹配样本,损失比为1:56.51。
Table 3. The observation result of propensity score matching
表3. 得分倾向匹配(PSM)观测结果
同时,结合倾向得分的共同取值范围图1所示,可以直观地看出大部分观测值都在共同取值范围内(On Support),即确保了处理组和控制组的倾向得分取值分布存在重叠,使得测算中样本损失小,匹配效果良好。
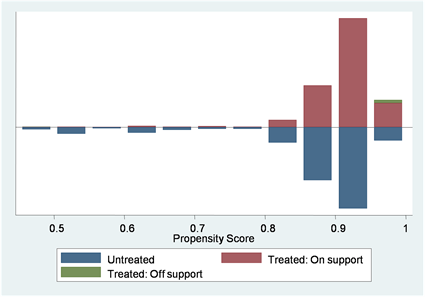
Figure 1. The common range of propensity score matching
图1. 得分倾向的共同取值范围
3.3.2. 平衡性检验
为了保证PSM匹配结果的稳健性,应对解释变量的平衡性进行检验。解释变量的平衡性要求在经过匹配后,控制组和处理组在协变量上不存在显著性差异。在倾向得分匹配之后,平衡性检验结果如下表4,
从0.054下降到0.001~0.009,LR统计量由匹配前的129.59下降到10.500~87.670,标准化偏差在匹配前后也有不同程度地减小。由指标分析可知,样本在倾向得分匹配法下有效地减少了变量自选择带来的偏误,使得样本分析结果更具有可信度。纵向对比五种匹配方法,发现近邻匹配、近邻卡尺匹配、核匹配和马氏匹配的平衡性检验指标相近,半径匹配与平均水平偏离程度较高。因此,在测算新农保政策影响效应时,选择近邻匹配、近邻卡尺匹配和马氏匹配方法更为有说服力。
Table 4. The balance test results of variables
表4. 解释变量平衡性检验结果
3.3.3. 参加新农保政策对农户贫困程度的影响效应
1) 平均处理效应测算。一般来说,利用倾向得分匹配后的数据测算平均处理效应,即项目效用评估,可以更准确地估计新农保政策对农户的效益。处理组和控制组的平均处理效应估计,如表5所示。从表格中可以直观地看出,近邻匹配、近邻卡尺匹配、核匹配和马氏匹配四种方法的估计结果相差不大,表明样本数据以及测算结果具有良好的可靠性和稳健性。
Table 5. The average treatment effect of PSM
表5. PSM的平均处理效应
注:*,**,***分别代表估计结果在1%,5%,10%的水平上显著。
从表5可以看出,平均处理效应(ATT)均值为0.052,说明在消除一定程度的自选择问题和内生性问题后,参与新农保政策的农户个体比不参与时的效益提高了5.2%。通过对核匹配的结果的进一步分析,获得控制组和处理组的箱线图和核密度图。结果显示,参保的处理组在效益的平均水平高和波动幅度较小,对比控制组具有较为明显的优势,说明新农保政策不仅能够提高农户生活的平均效益水平,也能保证为农户退休生活提供稳定的保障。总的来说,新农保政策对农户所得效益即缓解贫困程度有着积极作用,但是从实际出发,新农保政策的正向作用仍然有限,效益提升幅度普遍不高。
2) 多维度效用差异分析。事实上,新农保政策对于处于不同贫困维度的人群也存在着不同的作用。本文首先利用多维贫困测度方法对新农保政策的扶贫效用进行分析,发现贫困维度k越大时,贫困发生率和被剥削率也随之越高。综合数据对比,选择贫困维度来测算农户参保对整体样本贫困程度的影响效应更加科学:当贫困维度小于3 (k < 3)时,整体样本处于相对不贫困状态;当贫困维度大于且等于3 (k ≥ 3)时,整体样本处于相对贫困状态。
本文依据多维贫困指标体系,分析了在整体状况和具体不同维度下政策的平均处理效应(如表6)。从整体情况来看,新农保政策对两个群体都具有正向的效益,分别能为其日常生活带来平均4.5%和5.7%的增益。其中,参保的相对贫困群体受益更大,说明新农保政策的积极作用对相对贫困群体更加显著且有效。分解到具体维度来分析,除了卫生厕所维度,新农保政策都能为相对贫困群体带来积极效用,对处于非健康状态和需要医疗保险的相对贫困人群效用更大。例如,在控制其他变量影响的情况下,参保农户(处理组)的健康状况比不参与时改善了16.1%,医疗保险维度的贫困减少了103.8%。相比相对不贫困状态,在生活水平(食品消费与耐用消费品)、教育水平和住房水平(燃料与卫生厕所)等贫困维度下,新农保政策对为相对贫困农户能带来的效用较低。这可能是因为在养老保险金有限的情况下,参保农户的健康维度支出对其他维度支出产生了“挤出效应”,同时由于思想观念和节俭习惯,许多农村老人通常对大笔的、“非必要”的支出产生排斥心理,少有对生活质量提升的意识和诉求。
Table 6. The average treatment effect of multidimensional poverty
表6. 多维度平均处理效应
注:*,**,***分别代表估计结果在1%,5%,10%的水平上显著。
4. 研究结论与启示
本文基于2018年中国健康与养老追踪调查项目的数据,从相对贫困的角度探析了新农保政策对农户的扶贫效用。根据多维贫困指标体系,在不同维度的限制下,分别测算了参保处理组和未参保控制组的贫困发生率、贫困剥夺份额和多维贫困指数,发现样本存在选择性偏误等内生性问题。因此,本文采用倾向得分匹配法(PSM)对样本进行修正和进一步研究,并测算政策对农户的扶贫效用和比较贫困程度差异群组的影响净效应。研究结果显示,新农保政策不仅能够提高参保农户生活的平均效益水平,对相对贫困群体作用也更加显著,能保证为农户退休生活提供稳定的保障;从多维效用角度分析,相比于健康维度,新农保政策在生活水平、教育水平和住房水平等贫困维度的作用效率低,主要的可能性是养老金的数量限制使农户的健康支出对其他支出存在一定的“挤出效应”。
基于研究结果,为进一步稳固消除绝对贫困的战略成果,利用新农保政策夯实基础,与相对贫困作长期斗争,本文提出如下建议:一是完善新农保政策,合理解决部分贫困农村老人因“捆绑”规则、不了解政策等原因无法参保的情况,增强青中年人的养老观念,扩大政策的惠及范围;二是提高补贴力度或适当降低补贴领取要求,提高相对贫困农户的经济水平和生活质量,降低贫困剥削,提高政策的惠及力度;三是重视贫困农户思想观念的转变,提倡参与式扶贫,让贫困农户有自我意识地提高生活质量,发挥主观能动性,积极参与社会发展,共享减贫和改革的发展成果;四是在贫困农户建档立卡的信息中切入多维贫困评估,结合工作、医保、其他养老保险等其他信息,建立动态追踪机制,针对不同贫困程度的参保户实行针对性帮扶措施,多层次全方面地建立社会养老保障体系,不仅能提高退休老年人生活的经济水平和质量水平,也能为劳动人民描绘一幅美好愿景和蓝图,提高群众社会建设的积极性;五是关注政策的人文情怀,给予人民物质和精神上的双重关怀,增强人民的民族自信心和自豪感。
基金项目
安徽大学大学生创新创业训练计划(202010357627)。