1. 引言
学生课堂学习状态的研究与学生课堂学习效率及教师授课情况反馈息息相关,可作为学生课堂学习效率及教师授课情况的评价指标之一。目前课堂场景中对于学生课堂学习状态的研究主要从课堂学习行为 [1]、课堂疲劳状态 [2]、课堂人脸检测及关注度研究方面 [3] 展开,本文主要的工作是在已经检测出学生头部的基础上,对课堂中学生头部状态进行分类判别。
在计算机视觉和模式识别中,图像分类常用基于卷积神经网络的分类模型进行研究,1998年,LeNet模型 [4] 诞生,是最早的卷积神经网络之一,最早应用与MNIST [5] 手写识别数字的识别;该模型参数少且结构单一,并不适用于复杂的图像分类任务。2012年,AlexNet模型 [6] 作为ILSVR的冠军网络被人们认识,该模型使用ReLU [7] 激活函数,大大提高了训练速度,同时使用了随机失活操作,避免了一定程度上的过拟合,但对图像特征的描述及提取仍然有限。GoogLeNet模型 [8] 是ILSVR2014的冠军网络,最大特点在于引入Inception模块,该模块有四个分支且可以跨通道组织信息,大大提高了参数的利用效率,但同时也增加了计算量和出现过拟合。VGGNet模型 [9] 是ILSVR2014的亚军网络,由AlexNet模型发展而来,在卷积层使用较小的卷积核并采用多尺度训练策略,但是模型深度增加导致训练速度缓慢。ILSVR2015的冠军网络是ResNet模型 [10],该模型旨在解决网络模型加深而错误率提高的问题,当模型复杂以后,随机梯度下降(SGD) [11] 的优化变得更加困难,而模型达不到好的学习效果。Residual结构的提出,对卷积神经网路的发展产生了重要的意义。2016年,ResNeXt [12] 通过重复一个构建块来构建,聚合了一组具有相同拓扑结构的转换,在保持复杂的限制条件下,增加基数也能很好地提高分类精度。SENet模型 [13] 是ILSVR2017的冠军网络,该网络通过额外的分支来得到每个通道的权重,自适应地校正原各通道激活值响应。2017年Mobilenet模型 [14] 提出,作为Mobilenet系列的第一个版本,该模型主要采取可分离卷积的方式,降低参数量却不降低精度。2018年Mobilenetv2模型 [15] 在Mobilenetv1的基础上加入倒残差结构,从原来的残差结构进行降维到升维变成从升维到降维。保留了低维的信息特征。
图像分类虽然层出不穷,但是对于不同的研究目标有不同的适用网络,本文针对教室场景,以学生头部为目标,改进Mobilenetv2模型对学生头部图像进行分类,最后进行学习状态的判别。
2. 基本原理
2.1. Mobilenetv2
MobileNetv2 [15] 网络由google团队在2018年提出,在MobileNetv2网络中的重点是倒残差结构,如图1所示,(a)是Resnet网络中的残差结构,(b)是MobileNetv2中的倒残差结构。在残差结构中是1 × 1卷积降维到3 × 3卷积再到1 × 1卷积升维,在倒残差结构中正好相反,是1 × 1卷积升维到3 × 3卷积再到1 × 1卷积降维。这样做的原因在于高维信息通过ReLU激活函数后丢失的信息更少,而低维的运用ReLU激活函数信息丢失比较多,所以在最后一个1 × 1的卷积层使用线性激活函数,来保留低维的信息特征。
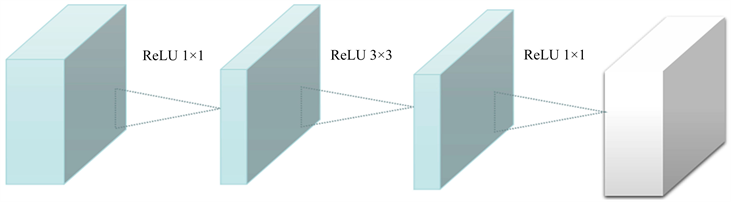 (a) Residual block
(a) Residual block (b) Inverted residual block
(b) Inverted residual block
Figure 1. Residual block and inverted residual block
图1. 残差块与倒残差块
表1是MobileNetv2网络的结构表,其中t代表的是扩展因子(倒残差结构中第一个1 × 1卷积的扩展因子),c代表输出特征矩阵的通道,n代表倒残差结构重复的次数,s代表步距(注意:这里的步距只是针对重复n次的第一层倒残差结构,后面的都默认为1)。步距不同的网络结构如图2所示。

Table 1. MobileNet v2 network structure
表1. MobileNet v2网络结构

Figure 2. Different network structures of Stride
图2. Stride不同的网络结构
2.2. 激活函数
2.2.1. ReLU函数
ReLU函数是目前深度学习中用得较多且广受欢迎的非线性激活函数。在
时才有非零输出,在
时输出为0,将ReLU函数定义为:
(1)
且函数曲线如图3所示。
经过求导计算,可得(1)的导函数为:
(2)
由(2)可知,ReLU函数其实上是最大值函数,与Sigmoid及Tanh函数相比,当输入值为正数时,ReLU函数运算非常简单且快速,同时也避免了梯度消失。拥有更加好的网络性能。当输入为负数时,ReLU是完全不被激活的,ReLU函数就会和Sigmoid及Tanh函数存在一样的问题。
2.2.2. Swish函数
Swish函数是x与sigmoid函数的结合,公式为
 (3)
(3)
且函数曲线如图4。

Figure 4. Swish function curve (β =1)
图4. Swish函数曲线(β = 1)
对(3)求导可得:
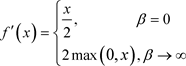 (4)
(4)
由(4)可以看出,β是个常数且Swish激活函数具备有下界、平滑、非单调的特性。其也被看成是介于线性函数与ReLU函数之间的平滑函数。Swish激活函数在正值区域可以达到任何高度,避免了由于封顶而导致的梯度饱和。对负值区域,与ReLU相比,有轻微的梯度流。平滑的激活函数允许更好的信息深入神经网络,从而得到更好的准确性和泛化。
3. 方法
3.1. 数据增强
在深度学习中,样本数量越多,训练出来的模型效果越好,模型的泛化能力越强。由于自建数据集的样本数量不是很多,为了提高模型的泛化能力,本文采用了三种方法对原有的数据进行增强,包括颜色扰动、高斯噪声滤波以及水平翻转。颜色扰动,指在某一个颜色空间通过增加或减少某些颜色分量,或者更改颜色通道的顺序。高斯噪声就是符合高斯正态分布的误差。有时我们需向标准数据中加入合适的高斯噪声来让数据变得有一定误差,从而让数据变得更具有实验价值。水平翻转是翻转中的一种,它是以坐标y轴为对称轴进行操作的过程,我们在这里使用水平翻转而没有使用全方位翻转的原因在于我们的数据具有一定程度的相似性,而且我们识别抬头低头的状态多数都是从正常的视觉出发,为了让数据增强具有合理性,我们使用了水平翻转。操作效果图如图5。
其中(a)表示原图,(b)表示经过颜色扰动后的图,(c)表示添加高斯噪声后的图,(d)表示水平翻转后的图。
3.2. 更换激活函数
激活函数是在激活层起主要作用的非线性函数,Mobilenetv2模型用到的激活函数为ReLU6,ReLU6其实是ReLU函数的变形,它的定义如下式:
 (5)
(5)
且函数曲线如图6。
ReLU6函数实际上是把ReLU函数取了上界,但当在负值区域,容易出现函数失活的问题,所以考虑一种更好的激活函数Swish来替代ReLU6。
 (a)
(a)  (b)
(b)  (c)
(c)  (d)
(d)
Figure 5. Data enhancement effect diagram
图5. 数据增强效果图
4. 实验结果
4.1. 实验环境
本节实验软件为Python3.6计算机编程语言,框架Tensorflow2.2.0及Keras2.2.4环境,硬件为64位Windows操作系统,Intel(R)Core(TM)i7-9700 CPU和16GB RAM,独立显卡AMD Radeon Pro WX3100。
4.2. 实验数据
本文实验用到的数据集由模型Yolov4与DropBlock结合算法检测到的学生头部结果图片制成,抬头低头图片数量各为1065张,总计2130张,命名为ClassUD。数据增强以后的数据集命名为ClassUD-A,每一种增强方法对每一种状态的数据都进行一次操作,抬头与低头状态的数据集扩增到了4260张,总计8520张图片。数据分布如表2。本文分类所需的数据皆是模仿监控视角的位置与高度拍摄所得,范围为一个教室的3至4排左右,且240张图片由40分钟视频以10秒一张图片的截取方式获得,对每张图片出现的学生头部进行裁剪且对不同的学生头部进行编号,此编号就代表这位学生,制成的数据集命名为ClassTest,依此类推,每一个编号的图片数应为240张,有些编号少于240张是由于在某些帧中头部存在被遮挡的情况,数据分布如表3所示。
Table 2. Training experiment data distribution
表2. 训练实验数据分布
4.3. 实验对比
4.3.1. 数据增强实验
本节中的实验分别在五个深度学习分类模型上进行,迭代次数为80次,批量输入尺寸为32。第一个实验用Vgg16模型进行训练及测试,第二个实验用Googlenet模型进行训练及测试,第三个实验是在Resnet50模型下进行训练及测试,第四个实验在Mobilenev2模型下进行训练及测试。第五个实验用Alexnet模型进行训练及测试,所有实验均在数据集ClassUD及ClassUD-A上进行。学习率是深度学习中的一个重要的超参,如何设置学习率是训练出好模型的关键要素之一。为了在五个模型上对同一数据集做实验对比分析,需要在同一实验条件下进行实验,所以对于模型的学习率,根据经验分别设置了0.001及0.0001两个不同的值。
当学习率为0.001时,在数据集ClassUD及ClassUD-A上的实验结果如表4及图7所示。
Table 4. Experimental results when the learning rate is 0.001
表4. 学习率为0.001时实验结果
由表4及图7可知,当学习率为0.001时,在数据集ClassUD上,训练耗时最少的模型为Alexnet,约为0.42小时,耗时最多的模型为Vgg16,约为11.50小时,训练与验证精度最高的模型为Mobilenetv2,分别为98.33%与91.33%,训练与验证精度最低的模型为Vgg16,约为49.32%与50.03%。在数据集ClassUD-A上,训练耗时最少的依然是Alexnet模型,约为1.41个小时,耗时最多的依然是模型Vgg16,约为49.22个小时,训练与验证精度最高的模型为Mobilnetv2,分别为99.03%及98.77%,训练及验证精度最低的模型为Vgg16,约为49.54%及50.02%。
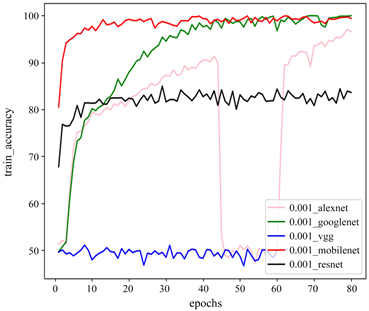 (a) ClassUD训练曲线
(a) ClassUD训练曲线 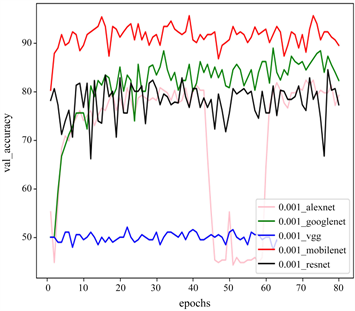 (b) ClassUD验证曲线
(b) ClassUD验证曲线  (c) ClassUD-A训练曲线
(c) ClassUD-A训练曲线  (d) ClassUD-A验证曲线
(d) ClassUD-A验证曲线
Figure 7. Training and validation diagrams of five models
图7. 五个模型的训练及验证图
数据增强后,对于Alexnet、Mobilenetv2及Googlenet模型来说,训练及验证精度都得到了不同程度上的提升;而对于Vgg16模型来说,数据增强几乎没有什么效果;对于Resnet50模型,训练精度反而还下降了;但是训练时间也同时在成倍的增长。Vgg16及Resnet50首先不是我们考虑的模型,其实按照训练时间来说,选择Alexnet模型最为合适,但是它较依赖于数据集的大小,而对于Googlenet及Mobilenetv2模型在ClassUD上表现得比较好,在ClassUD-A上更好,网络相对稳定且在不断的学习。
当学习率为0.0001时,在数据集ClassUD及ClassUD-A上的实验结果如表5及图8。
由表5及图8可知,当学习率为0.0001时,在数据集ClassUD上,训练耗时最少的模型为Alexnet,约为0.42小时,耗时最多的模型为Vgg16,约为11.49小时,训练与验证精度最高的模型为Mobilenetv2,分别为98.92%与87.76%,训练与验证精度最低的模型为Resnet50,约为82.41%与79.13%。在数据集ClassUD-A上,训练耗时最少的依然是Alexnet模型,约为1.47个小时,耗时最多的是模型Vgg16,约为49.22个小时,训练与验证精度最高的模型为Mobilnetv2,分别为99.37%及98.82%,训练及验证精度最低的模型为Resnet50,约为81.94%及85.61%。
Table 5. Experimental results when the learning rate is 0.0001
表5. 学习率为0.0001时实验结果
 (a) ClassUD训练曲线
(a) ClassUD训练曲线  (b) ClassUD验证曲线
(b) ClassUD验证曲线  (c) ClassUD-A训练曲线
(c) ClassUD-A训练曲线  (d) ClassUD-A验证曲线
(d) ClassUD-A验证曲线
Figure 8. Training and validation diagrams of five models
图8. 五个模型的训练及验证图
数据增强以后,对于Alexnet、MobilenetV2、Googlenet及Vgg16模型来说,训练及验证精度都得到了不同程度上的提升;对于Resnet50模型,训练精度反而下降了一点;训练时间也同时在成倍的增长。Resnet50首先不是我们考虑的模型,同时Vgg16的训练时间太长,也不是我们考虑的模型。而Alexnet、Googlenet及Mobilenetv2模型不管是在ClassUD上还是在ClassUD-A上都表现得比较好,网络相对稳定且在不断的学习。
通过两个不同学习率及不同数据集下的实验,得出在数据集ClassUD-A上的实验效果比数据集ClassUD效果更好,在学习率为0.0001时比学习率为0.001时效果更好,所以之后的实验将在数据集ClassUD-A及学习率为0.0001的条件下进行。
4.3.2. Swish激活函数实验
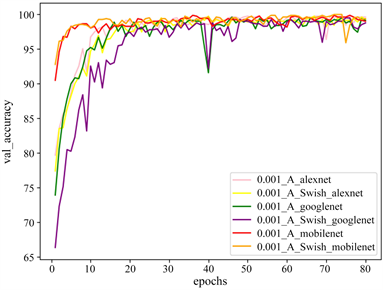
分别进行三个实验,把Alexnet、Googlenet及Mobilenetv2网络模型的激活函数替换为Swish后,称这些网络为Alexnet_S、Googlenet_S及Mobilnetv2_S,并在数据集ClassUD-A上进行了Alexnet、Alexnet_S、Googlenet、Googlenet_S、Mobilenetv2及Mobilenetv2_S实验的对比。实验结果见表6及图9。
Table 6. Experimental results of different models
表6. 不同模型的实验结果
 (a) ClassUD-A训练曲线(b) ClassUD-A验证曲线
(a) ClassUD-A训练曲线(b) ClassUD-A验证曲线
Figure 9. Training and verification diagrams of the three models
图9. 三个模型的训练及验证图
从表6及图9可知,在数据集ClassUD-A上,我们更改模型的激活函数为Swish后,在训练时间上,Alexnet_S比Alexnet多花了0.18 h、Googlenet_S比Googlenet多花了0.72 h、Mobilenetv2_S比Mobilenetv2多花了0.11 h;在平均训练精度上,Alexnet_S比Alexnet减少了0.44%,Googlenet_S比Googlenet减少了1.13%,Mobilenetv2_S比Mobilenetv2提高了0.18%;在平均验证精度上,Alexnet_S比Alexnet增加了0.01%,Googlenet_S比Googlenet减少了1.47%,Mobilenetv2_S比Mobilenetv2提高了0.18%。综合上述分析,在Alexnet_S、Googlenet_S及Mobilenetv2_S模型中,Mobilenetv2_S是训练时间增时最少,也是平均精度增加最多,更是训练精度及验证精度最高的模型。所以对于学生头部状态的判别选用Mobilenetv2_S模型进行实验。
4.3.3. 头部状态分类判别实验
在进行分类判别之前,对学生头部状态数据集ClassTest进行了人工观察,观察结果见表7,进而用Mobilenetv2_S模型对学生头部状态数据集ClassTest进行分类判别,结果见表8。而人工观察与算法分类判别结果的平均值误差对比见表9。规定抬头状态比例达到60%及以上的学生为认真学习状态,低头状态比例达到60%以上的学生为非认真学习状态,若两种状态比例相近且不属于上面两类,判断学生为注意力不集中状态。
Table 7. Manual observation results
表7. 人工观察结果
Table 8. Test data experimental results
表8. 测试数据实验结果
Table 9. Comparison of the results of the student’s head state error of the two different methods
表9. 两种不同方法的学生头部状态结果误差对比
从表7来看,学生1、2、4、7、8、9、10、11、12、13、14在时常40分钟的课堂里为认真学习状态,而学生3、6为非认真学习状态,学生5的抬头比例及低头比例相近,我们认为此学生在课堂里为注意力不集中状态。
从表8分类精度来看,对于14个学生目标,有10个学生头部的分类精度均在92.31%至100%之间,4个学生头部的分类精度均在87.67%至89.58%之间,基本达到检测要求,其中4个低于90%分类精度的原因是学生头部存在部分遮挡,导致检测结果不佳,从检测抬头低头比例来看,学生1、2、4、7、8、9、10、11、12、13、14在课堂中为认真学习状态,而学生3、6为非认真学习状态,学生5为注意力不集中状态。
从表9可知,我们的算法检测结果平均值与人工观察结果平均值相差不大,学生学习状态也大致相同。
综合以上分析,提出的Mobilenetv2_S算法适用于自建数据集并取得了良好的分类效果。
基金项目
本文研究受贵州省教育厅创新群体重大研究项目(KY2018018)的支持。