1. 引言
行人重识别(person re-identification, Re-ID)由于在视频监控、人机交互领域的重要应用,近年来受到了越来越多的关注。在视频监控中,由于相机分辨率和拍摄角度的缘故,通常无法得到高质量的人脸图片,此时人脸识别 [1] [2] [3] 失效。行人重识别就成了一个非常重要的替代技术,它广泛被认为是一个图像检索的子任务,给定目标人物的图像,行人重识别的目标是找到不同相机或同一相机在不同时间捕捉到的同一人的其他图像。
最近几年,越来越多的研究者尝试将行人重识别的研究与深度学习 [4] [5] [6] 结合在一起,并取得了很好的效果。现有的行人重识别的工作大部分聚焦于监督学习 [7] - [14],它们假设可以为每一对相机视图提供大量手动标记的匹配对,来学习该相机相对优化的特征表示或匹配度量函数。然而,这种规模的手动标签不仅在现实世界中收集起来非常困难,而且在许多情况下是不可行。例如可能没有足够的训练人员在每对相机视图中重新出现。这限制了它在真实应用场景中的扩展性和可用性。
针对上述问题,一种通用的解决方案是设计无监督模型 [15] - [26]。虽然一些无监督行人重识别算法已经被提出,但是与监督学习方法相比,它们的识别效果较弱。一个主要的原因是,如果没有跨视图的标记数据,则无监督方法由于不同的视角、背景和照明而缺乏跨视图下相同身份视觉特征变化所需要的必要知识。对此,我们提出了一个多维注意力模块来解决行人图片中的视角、背景等的干扰,该模块可以去除图片中杂乱无章的背景噪声,从而提取出具有鲁棒性的嵌入特征。
此外,在行人重识别中一些基于部件生成的方法 [12] [14] 被提出来并超过了基于全局特征的方法。例如,Rahul等人 [12] 提出了基于图像切块的方法,将图像块按顺序送到一个LSTM网络中,最后进行特征融合。Wei等人 [14] 提出了一种全局–局部对齐的特征描述子,来解决行人姿态变化的问题。虽然基于部件匹配效果超过了基于全局特征的方法,但是我们也发现了部件匹配存在的问题。那就是部件无法进行很好地对齐,从而影响了效果。为此,我们提出了部件关注模块来解决部件对齐的问题。该模块可以使部件能够很好地进行匹配,从而提取出具有鲁棒性的局部特征。
基于以上分析,本文提出了一个多维注意力网络和部件关注网络联合学习的无监督行人重识别方法。首先通过一个多维注意力模块来解决行人图片中的背景噪声的干扰;然后是一个部件关注网络,将它部署到一个改进的STN后,使得每个分支可以关注人体不同的部件,包括头部特征、上半身特征和下半身特征。
分别在两个已知的行人重识别的数据集上对本文提出的方法进行了评估,包括Market-151和DukeMTMC-reID。结果表明本文提出的方法取得了非常好的效果。
2. 相关工作
在本节中,简要叙述行人重识别之前的工作,包括监督的行人重识别、无监督的行人重识别和行人重识别中的注意力机制。
2.1. 监督行人重识别
监督学习方法是解决行人重识别问题最常用的方法,包括基于表征的学习 [7] [8]、基于度量学习 [9] [10] [11]、基于局部特征学习 [12] [13] [14] 的行人重识别,它们主要得益于卷积神经网络的快速发展。
表征学习的方法是一种非常常见的行人重识别方法,它主要得益于卷积神经网络的快速发展。由于卷积神经网络可以自动从原始图像数据中根据任务需求自动提取表征特征,所以一些研究者把行人重识别问题看作分类或验证问题。例如,Zheng等人 [7] 提出使用两种模型来学习行人描述符,分别是分类模型和验证模型。其中分类模型对输入图片进行预测,根据预测的ID来计算分类误差损失。验证模型融合两张图片的特征,判断两张图片是否为同一身份。Lin等人 [8] 提出了基于属性和身份学习的方法,提出的模型不仅会学习到行人的ID特征,还可以学习到行人的属性特征,这大大增强了模型的泛化能力。
度量学习旨在通过网络学习出两张图片的相似度。在行人重识别问题上,具体表现为同一个人的不同图片相似度大于不同人图片的相似度。例如,Rahul等人 [9] 提出了一个基于Siamese网络的方法,将一对图片输入到孪生网络中,使用交叉熵损失判断两张图片的相似度,使得正样本对之间的距离逐渐变小,负样本对之间的距离逐渐变大。Cheng等人 [10] 提出了基于三元组损失的网络,需要输入三张图片(一对正样本对,一对负样本对),使用三元组损失拉近正样本对的距离,推开负样本对的距离。Alexander等人 [11] 提出了一个难样本采样三元组损失,主要解决的是三元组损失采样抽取出来的都是简单易区分样本对的问题。
早期行人重识别的研究大家只关注全局特征,就是用整张图片得到一个特征向量进行图像检索。但是仅仅使用全局特征达不到理想的效果,所以一些研究者开始关注局部特征。例如,Rahul等人 [12] 提出了基于图像切块的方法,将图片垂直切割为若干块,按顺序送到一个LSTM网络中,最后进行特征融合。为了解决图像切块无法对齐问题,Zheng等人 [13] 提出了基于姿态估计与关节点定位的方法,首先使用姿态估计模型估计出行人的14个关键点,然后使用仿射变换使得相同的关键点对齐,这些关键点可以将人体分为不同的部位。Wei等人 [14] 提出了一种全局–局部对齐的特征描述子,来解决行人姿态变化的问题。
2.2. 无监督行人重识别
近年来一些研究者提出了具有手工特征的非监督方法 [15] [16] [17] [18] [19]。然而,与监督学习方法相比,它们的再识别性能较差。例如,Zheng等人 [15] 提出了一种无监督的BOW描述符,受图像搜索系统的启发,将每个行人图片表示成视觉词汇直方图,并支持全局快速匹配。Liao等人 [17] 提出一个特征提取方法LOMO,主要着眼于光照和视角问题,基于HSV颜色直方图和XQDA度量学习。Tetsu等人 [19] 提出了一种基于像素特征的层次分布描述符,通过分层高斯分布描述图像中的局部区域。
由于卷积神经网络在监督行人重识别领域中取得了无可比拟的性能,因此一些研究者在无监督行人重识别中也使用了深度学习的方法,并取得了一定的效果。目前基于深度学习的无监督方法主要分为基于聚类的无监督行人重识别和基于跨域的无监督行人重识别。
聚类分析 [20] [21] [22] 是一种长期存在的无监督深度学习方法,近几年,基于聚类的无监督行人重识别被提出。例如,Fan等人 [20] 提出了基于聚类和微调的无监督学习方法,采用K-means聚类进行标签估计,逐步选取可靠的图像,并利用这些图像对深度神经网络进行微调,学习识别特征。Yu等人 [21] 提出了无监督非对称距离度量学习的方法,基于非对称的K-means聚类来实现试图不变性。Lin等人 [22] 提出了一种自底向上的聚类框架,该框架根据预定义的标准将聚类分层组合,基于一个非常简单的最小距离准则和一个集群大小正则化项。然而,聚类得到的图像的伪标签可能是有噪声的,因为它可能会将相同的标签分配给具有不同身份的相似图片,使得区分相似的人更加困难。
最近,一些研究者提出了跨域迁移学习的无监督行人重识别 [23] [24] [25] [26] 的方法,主要利用带有标签的数据集来提高模型在目标数据集上的性能。例如,Peng等人 [23] 提出了无监督跨数据集的迁移学习,通过字典学习机制将人的外观视图不变表示从带有标签的源数据集转移到无标签的目标数据集中,并获得了更好的性能。Zhong等人 [24] 引入了摄像机样式转换方法来处理多个视图中的图像样式变化,并学习了一个摄像机不变的描述子空间。Wang等人 [25] 首先利用源域上的属性进行训练,然后学习身份和属性的联合特征表示。
Gao等人 [26] 首先提出了“相机感知”域适应,以减少源域和目标域之间的差异,然后利用目标域中每个摄像机的时间连续性来创建有区别的信息。
2.3. 行人重识别中的注意力机制
最近几年,注意力机制在计算机视觉 [27] 领域取得了巨大的成功,例如目标检测 [28]、图像分割 [29] 和姿态估计 [30]。对于行人重识别 [31] - [39],也存在着许多基于注意力机制的方法。
这些方法的共同策略是将注意力机制整合到深层模型中,以解决行人重识别的定位和不对齐问题。Li等人 [34] 提出了一种协调注意力模型(harmonious attention, HA),该模型从全身图像中定位身体部位,同时学习多尺度特征图。Song等人 [31] 提出了MGCAM移除背景、视点和姿态等因素对行人的影响,使网络更关注于前景区域图像。Wang等人 [32] 提出了一种基于新的无参数空间注意力,将特征图上激活之间的空间关系引入到模型中。Cheng等人 [35] 提出了ABD-Net,该模型将注意力模块和多样性正则化融入整个网络,其中注意力机制结合了通道和空间信息,避免注意力机制过度集中于前景,正则化可以增强隐藏激活和权重的多样性。Zhao等人 [37] 提出了一种基于部件映射检测器的部件对齐表示方法,用于每个预定义的身体部件。Si等人 [39] 提出了一种基于类间和类内注意模块的双重注意匹配网络,用于捕获视频序列的上下文信息。
3. 方法
在本节中,详细介绍了改进的无监督行人重识别学习框架,该框架如图1所示,它是基于ResNet-50的卷积神经网络。
首先,是一个多维注意力模块,将ResNet-50分解为两个部分,即P1 (from conv1 to layer2)与P2 (from layer3 to GAP)。P1用于将给定的图像从原始像素空间编码为中层特征空间,P2用于将注意信息编码为高层特征空间,可以对数据进行分类。在P1与P2之间放置不同维度的注意力模块,生成多样化的注意力特征,强化所学知识的丰富性。在Sec.3.1中详细介绍。
其次,使用一个改进的STN形成三个分支,在每个分支后加入一个部件关注模块,并使用带有标签的数据集来预训练部件关注模块,使得每个分支可以关注人体不同的部件,包括头部特征,上半身特征和下半身特征。在本节中的Sec.3.2详细介绍。
最后是损失函数模块,首先使用了一个存储器来存储部件的更新特征,然后是一系列的损失函数来引导部件关注网络学习未标记数据集上的部件特征。在本节的Sec.3.3中详细介绍。
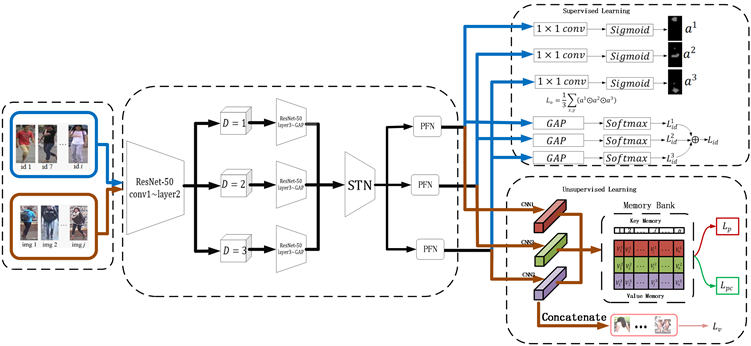
Figure 1. The framework of the proposed approach
图1. 网络结构图
3.1. 多维注意力模块
注意力机制在行人重识别中变得更有吸引力,因为它能够将可用资源分配给输入信号中信息最丰富的部分,同时我们可以得到注意力方法的一般情况。具体的说,对于给定的三维张量X,我们可以得到一个卷积激活输出。其中
,C、H、W分别表示通道数,高度和宽度。我们的目标是将卷积激活输出进行重新加权,将此过程表述为:
(1)
其中
是注意力模块的激活输出,
表示两个矩阵对应元素相乘,
是一个权重项,每个元素的值在区间
之间。
然而,目前这些常用的注意力方法要么是粗糙的,要么是一维的,如图2中
所示,仅限于挖掘简单而粗糙的信息。为此我们提出了高维注意力模块,如图2所示。以
为例,它有三个分支,对于第r个分支,我们使用r组通道数相同的1 × 1的卷积核
生成通道为
的一组特征图
。操作如下:
(2)
其中
为卷积核的权重,X为输入的一个三维张量。
将这组特征图结合在一起可得第r个分支的特征图为:
(3)
然后再使用一组1 × 1的卷积核
来生成通道数为C的特征图,可以得到:
(4)
其中
代表ReLU激活函数,
作为一个权重项,使用sigmoid激活函数将其中的每个元素值映射到
的区间,将
代入公式(1)就可以得到高维注意力激活特征。
最后,将不同维度的注意力模块组合在一起,共同学习更具鲁棒性的特征。
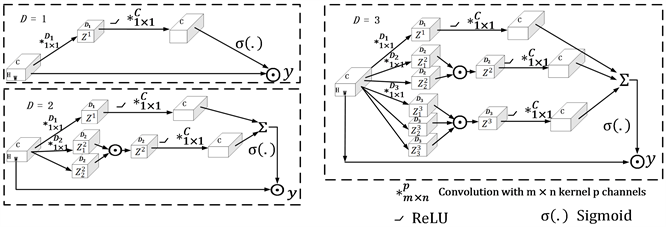
Figure 2. Illustration of Multi-Dimensional Attention Network (MDAN)
图2. 多维注意力模块
3.2. 部件关注模块
我们首先使用一个改进的STN形成三个分支,在每个分支后加入一个部件关注模块,使得每个分支可以关注人体不同的部件。该模块由两部分组成,如图3所示。对于第一个分支,它关注部件的空间信息,对于第二个分支,它关注着部件的通道信息。
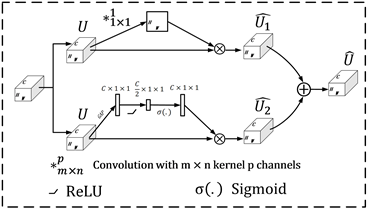
Figure 3. Illustration of Part Focus Network (PFN)
图3. 部件关注网络
对于第一个分支,假设输入层的特征图为U,令
,
对应着
的空间位置,其中
,
。通过通道数为1的1×1卷积实现空间压缩操作,如下:
,其中
为权重,生成一个映射张量
。映射的每一个
表示空间位置
的所有通道C的线性组合,再经过sigmod对其进行归一化操作到
。操作如下:
(5)
每一个
的值代表着特征图中空间位置坐标
的重要性。
对于第二个分支,将输入层特征图
看作是信道
的组合,经过全局池化层之后得到向量
,每个位置k的值为:
(6)
然后经过两次全连接层,过程如下:
(7)
其中
,
,
,
分别为全连接层的权重,
代表着RelU激活操作。再经过sigmod对
进行归一化操作到
。操作如下:
(8)
代表的信息就是第i个通道
的重要性程度。
最后,将上述的两个模块结合从而得到此时的部件特征图
。
为了更好地学习到行人的部件特征,我们使用带有标签的数据集MSMT17 [43] 对部件关注网络进行预训练。对于每一张标签为t的训练图像I,其中t为目标类的索引。对于每个分支i,可以得到部件特征图,即,
,为了使部件关注模块能够更好的关注我们感兴趣的部件,我们在每一个分支后添加1 × 1卷积和一个Sigmoid函数将值映射到(0,1)来获得每个部件的掩码
。
(9)
其中W为1 × 1卷积的权重。由于目标是引导不同的分支来关注不同的身体区域,因此不同分支
的非零区域应该是不重叠的。因此,我们提出了一个损失函数来对重叠区域进行惩罚,定义如下:
(10)
其中
表示逐元素乘法,N表示分支数。
对部件特征
进行全局平均池化后,可以得到部件的类分数
,通过Softmax函数进一步归一化为概率分布
,因此第i个分支的分类损失被计算为预测概率
与真实值之间的交叉熵。
(11)
其中t是目标类的索引,所有分支的损失相加构成了识别损失,
。
最终的损失函数是
和
的加权和。
(12)
其中
是权重,并且在后面的实验中我们令
。
3.3. 损失函数
3.3.1. 特征存储
在此我们使用存储器来存储部件的最新特征,存储器是一个键值对结构(key-value, K-V)。K用来存储每个图像的索引。V用来存储每一张图片的部件特征,包括三部分,分别用来存储行人的头部特
征,上半身特征和下半身特征。如图所示,每个部件特征的存储特征可以表示为:
其中
分别代表着三个部件特征,N表示训练图片的个数。我们通过以下公式对存储体进行更新:
(13)
其中t是训练轮回数(epoch),
表示存储器的初始状态。l是
的学习率,
是第t个轮回时第j张图片的第m个部件的特征。
3.3.2. 基于部件的损失
我们提出了一种基于部件的损失函数(PBL),通过将相似部件的特征拉在一起,将不同的部件推开,从而引导部件提取网络学习未标记数据集上的部件特征。我们可以使用式13对存储器进行不断的更新,在此过程中,我们计算每个x与每个v的差异。详细的说,对于每一个
,通过计算
与存储体
之间的
距离从而获得
的k个最近的集合
,为了拉近特征相似的部件,推远特征不
相似的部件,我们提出了一个基于部件的损失函数,通过下式计算PBL:
(14)
其中s是比例数,最小化
会促使模型将与
相似的部件
拉近,同时在特征空间中将与
不相似的部件
推离。
为了对所有的部件进行约束,我们提出了基于部件约束的损失(BC),它包含三部分,头部与上半身的约束,上半身与下半身的约束及整体的约束。这些约束就是将人体的部件进行融合,从而得到部
件的约束特征。此时的样本约束特征可以表示为
,存储体可以表示为
。可以得到基于部件
约束的损失函数为:
(15)
其中s是比例数,
表示头部与上半身的约束,
表示上半身与下半身的约束,
表示整体的约束。
3.3.3. 基于图像级的损失
为了进一步挖掘图像间的潜在信息并最小化类内差异同时最大化类间差异,我们提出了一个三元组损失对全局特征进一步的约束。在我们的实验中,我们定义了一系列随机变换来生成代理正样本,包括图像的裁剪、缩放、旋转、亮度、对比度和饱和度。然后为每个真实样本生成一个代理正样本。
同时我们通过循环排序挖掘到负样本对,如图4所示:给定一小批量样本特征
,每个样本
的排序结果可以基于成对相似度度量来得到。我们使用
距离来度量成对的相似性,从而得到图像
的排序列表
。然后我们按顺序遍历排序列表
。对于每个候选样本
,我们使用相同的方法来计算排序列表。最后,如果
不是
的top-r最近邻,那么我们认为
很可能是
的负样本。此外,由于难分的负样本对可以更有效地学习判别特征,因此我们只考虑第一个符合上述条件的候选样本
。我们把这个负的候选项表示成负样本
。在这里我们给定三元组损失的定义:
(16)
其中m代表着三元组损失的间隔(margin),
代表正样本,
代表负样本。

Figure 4. Illustration of the cyclic ranking
图4. 循环排序模块
3.3.4. 最终的损失
因此,我们模型中的每一幅图像的总体损失函数可以表示为:
(17)
其中
是部件损失的权重系数,
是部件约束损失的权重系数。
4. 实验
在这一部分中,主要是对所提出的方法进行评估。首先在第4.1节中介绍使用的数据集与评估指标,其次在4.2节中的介绍了实验细节。然后在4.3节中,进行消融实验来验证组件的有效性。最后将本文提出的方法与其他最先进的算法进行比较。
4.1. 数据集与评估指标
Market-1501 [40] 是一个大型的行人重识别数据集,它包含1501个id的32,688张图像。这些图片是在校园里被6台摄像机拍了下来。数据集分为两部分:其中751个id的12,936张图像用于训练,750个id的19,732张图像用于测试。
DukeMTMC-reID [41] 是行人跟踪数据集DukeMTMC [42] 的子集,它包含了从8个相机中收集到的36,411张1812个id的图片。与Market-1501数据集的划分类似,数据集包含来自702个ID的16,522个训练图像样本,来自其他1,110个ID的2228个查询图像样本和17,661个待匹配的图像库样本。
MSMT17 [43] 是目前最大的行人重识别数据集,它包含了15个摄像头中4101个id的126,441张图像。与Market-1501和DukeMTMC-reID类似,数据集被分为两部分:用于训练的1041个id的32,621张图像,用于查询的3060个id的82,161张图像和11,659个待匹配的图像库样本。
Evaluation Metrics:本文使用 rank1、rank5、rank10和平均精度(mAP)来评估这三个数据集。
4.2. 实验细节
实验基于Linux环境下的开源Pytorch框架 [36],硬件基础为NVIDIA GeForce RTX 2080GPU。使用ResNet-50 [44] 作为基本CNN模型,并在ImageNet数据集 [45] 上进行预训练,首先将ResNet-50 [44] 分解成两部分P1和P2,在P1和P2之间放置不同维数的注意力模块,生成不同维度的注意图,每个注意力模块的输出特征的维数为256。然后将不同的注意力模块特征相融合并使用一个改进的空间变换网络(STN)形成三个分支,在每个分支后加入一个部件关注网络,并使用带有标签的数据集MSMT17 [43] 对部件关注网络进行预训练,使之关注人体的不同部件,即生成3个256维的部件特征(头部,上半身,下半身)。对于生成的每个部件,使用特征存储器来进行部件特征存储更新,更新率 设置为0.1。同时将DukeMTMC-reID [41] 数据集上的比例系数s设置为10,Market-1501 [40] 上的设置为30。在对未标记的数据集进行训练时,随机采样图像,并将其大小调整为384 × 128。每个mini-batch由8个真实样本组成,另外还有8个代理正样本用于计算三元组损失。使用SGD [32] 作为优化算法,初始的学习率设置为0.0001,每20个轮回数(epoch)衰减0.1。在未标记的数据集上对模型进行了60个轮回数(epoch)的训练。测试时,将同一幅图像的部件特征拼接在一起,计算出两两距离。
4.3. 消融实验
为了对本文提出的方法性能进行验证,在Market-1501 [40] 和DukeMTMC-reID [41] 数据集上进行了大量的消融实验,来分析每个组件的有效性。实验结果如表所示。
注意力维度个数对实验的影响:从表1可以看出,维度个数为4实验效果最好。
部件个数对实验的影响:从表2可以看出,部件个数对实验有一定的影响。多次实验结果表明,部件个数为3时,效果最好。
不同模块对实验的影响:从表3可以看出,“MDAN”的结果比“基本网络”的结果要好;“PFN”的结果比“基本网络”的结果要好,“MDAN”与“PFN”联合学习的效果最好。

Table 1. The influence of the number of attention dimensions on the experiment (%)
表1. 注意力维度个数对实验的影响
Table 2. The influence of different parts number on experiment (%)
表2. 不同部件个数对实验的影响
Table 3. The influence of different modules (%)
表3. 不同模块对在两个数据集上对实验的影响
4.4. 对比实验
将本文提出的模型与其他先进的无监督行人重识别模型进行了比较,包括:1) 基于手工制作的模型LOMO [17]、BOW [40] 和UDML [24];2) 基于伪标签学习的模型PUL [20]、DBC [21] 和BUC [22];3) 基于无监督域自适应模型TJ-AIDL [25]、HHL [26]、UCDA-CCE [46]、SSL-CCE [47] 和ECN [48]。
其中表4是Market-1501数据集的比较结果,表5是DukeMTMC-reID数据集的比较结果。可以看到,本文提出的方法在两个数据集上都明显优于其他方法。与手工制作的基于特征表示的模型比较时,性能差距最为显著。其主要原因是这些早期的作品大多基于启发式设计,因此无法学习到最优的判别特征;与基于伪标签学习模型的比较时,本文模型明显优于基于伪标签学习的无监督行人重识别模型。一个关键的原因是基于伪标签的方法可能会将不同身份的相似图片分成相同的伪标签,在本文中,即使将不同身份的某一部件拉近,仍然有图像的其他部件进行补充;与基于无监督域自适应的行人重识别模型相比,所提出的模型具有明显的优势,一个关键的原因是源域图像与目标域图像之间的差距大于图像部分之间的差距,所以基于图像的特征学习模型很难转移到目标域。
Table 4. Comparison to the state-of-art unsupervised results in the Market-1501 dataset
表4. 不同算法在 Market-1501 数据集上的性能比较
Table 5. Comparison to the state-of-art unsupervised results in the DukeMTMC-reID dataset
表5. 不同算法在DukeMTMC-reID数据集上的性能比较
5. 结论
在本文中,首先提出了多维注意力网络,对注意机制中复杂的高阶统计信息进行建模和利用,从而捕捉行人之间的细微差异,产生有区别的注意建议。其次,使用一个改进的STN形成三个分支,在每个分支后加入一个部件关注网络,并使用带有标签的数据集来预训练部件关注网络,使得每个分支可以关注人体不同的部件。最后是损失函数,使用了一个存储器来存储部件的更新特征,并通过一系列损失函数来引导部件关注网络学习未标记数据集上的部件特征。大量的实验验证了该方法的有效性。然而目前的行人重识别数据集基本上维持着几万张图片几千个ID的水平上,这大大阻碍了基于深度学习的行人重识别的研究。因此,在下一步的研究中,可以使用GAN来增加数据量的规模从而提高模型泛化的能力。