1. 引言
合成孔径雷达(Synthetic Aperture Radar, SAR)图像具有极强的抗干扰特性,在航空航天工程、地质勘探、测绘和军事侦察中发挥着关键作用。为了确保SAR图像在图像分类和目标识别方面具有良好的性能,可以提高现有SAR图像的分辨率。但是,许多高分辨率图像是从低分辨率图像中重建出来的,很难区分生成的哪一张高分辨率图像效果更好,这对图像超分辨率来说是一个挑战。
现有的超分辨率生成对抗网络,例如SRGAN [1]、ESRGAN [2] 和A-SRGAN [3],仅判别高频特征空间,而忽略低频特征空间的作用。在图像超分辨率重建过程中,生成的高分辨率图像不能保证准确地降采样到最初的低分辨率图像。如果重建的高分辨率图像更接近真实的高分辨率图像,则对生成的高分辨率图像进行降采样后得到的低分辨率图像也更接近真实的低分辨率图像。为了充分利用高分辨率图像和低分辨率图像的信息以获得具有更好视觉效果的高频纹理细节,提出了双重判别的SAR图像超分辨率重建算法。首先,双重判别通过利用高分辨率图像和低分辨率图像之间的相关性,同时判别两种不同分辨率的图像,这使得生成的高分辨率图像更加逼真。其次,考虑到在最近的超分辨率工作中残差密集块RDB [4] 和多层特征融合的优越性能,将这两种技术引入到了双重判别的生成器中,提出了能够融合多层变换特征的生成器网络,有效地提高了参数的利用率。
2. 相关工作
大多数研究工作已致力于图像超分辨率重建的研究。最初,使用插值方法生成高分辨率图像,例如最近邻插值、双线性插值和双三次插值。尽管插值方法简单、方便、易于实现,但是它们容易产生模糊的纹理。后来提出了模型统计的方法,学习从低分辨率图像到高分辨率图像的映射,典型方法包括基于示例的方法 [5]、自相似性方法 [6]、字典对方法 [7] 和卷积稀疏编码方法 [8]。随着卷积神经网络(Convolutional Neural Network, CNN)的出现,许多基于CNN的方法也已应用于图像超分辨率重建中。Dong等人首先提出了SRCNN [9],该方法将三层CNN应用于图像超分辨率重建中,并获得了良好的性能。为了加速网络训练,提出了FSRCNN [10] 和ESPCN [11]。随后,通过去除批归一化层并加深网络,提出了增强的深度残差网络EDSR [4],目的是提高超分辨率的重建性能。密集连接网络 [12] [13] [14] 通过增加每个残差块的复杂度来提高超分辨率性能,并减少由于网络深度过深而导致的训练困难。由于注意力机制 [15] 在图像分类中的出色表现,基于注意力的图像超分辨率重建算法 [16] [17] 也取得了良好的效果。
生成对抗网络 [18] 的提出是深度学习的另一项重大突破,其在图像生成 [19] 和风格迁移 [20] [21] 等方面的出色表现备受关注。SRGAN [1] 是首次在单图像超分辨率重建中使用生成对抗网络的模型,并产生高频纹理细节,从而实现了非常好的视觉效果。SRGAN的生成器是残差神经网络(SRResNet),其视觉效果优于SRResNet,但是SRGAN在客观评估指标(例如峰值信噪比(PSNR)和结构相似性(SSIM))方面表现不佳。可能的原因是,判别器根据图像中是否包含高频纹理信息来确定图像的真实性,却不关注高频纹理信息是否是真实的。因此,SRGAN生成的高频伪像不能用于非常严格的情况下,例如医学诊断和军事目标侦察。后来,提出了增强型SRGAN (ESRGAN [2] ),通过增加每个残差块的复杂度来生成更逼真的高频细节,并使用RaGAN [22] 来确定在超分辨图像和真实图像之间哪个更真实。同时,一些使用特征判别的算法也可以准确地重建高分辨率图像的纹理,例如EnhanceNet [23] 和SRfeat。
3. 方法
从低分辨率图像
中恢复相应的高分辨率图像
是单图像超分辨率重建的主要目标。高分辨率图像的重建基于双重判别。生成器G的主要目的是通过生成类似于真实高分辨率图像的超分辨图像
来欺骗这两个鉴别器,使高分判别器
无法将伪造的高分辨率图像与真实的高分辨率图像区分开,并使低分判别器
无法区分伪造的低分辨率图像和真实的低分辨率图像。高分判别器和低分判别器的训练目标是防止被生成器欺骗。生成器和两个判别器的目标函数如下。
(1)
(2)
(3)
其中,
表示生成的高分辨率图像降采样后得到的低分辨率图像。
和
分别表示真实的高分辨率图像和真实的低分辨率图像的分布,
表示降采样得到的低分辨率图像的分布。生成器和两个判别器以交替的方式训练。训练生成器时,两个判别器保持不变,并且生成器生成尽可能真实的高分辨率图像。当重建的高分辨率图像更接近实际的高分辨率图像时,真实的低分辨率图像和重建高分辨率图像的降采样图像也更接近。当训练两个判别器时,生成器保持不变。高分判别器判别重建的高分辨图像与真实的高分辨率图像,低分判别器判别超分辨图像的降采样图像与真实的低分辨率图像。
下面将详细讨论生成器和判别器的网络结构以及双重判别的判别原理。
3.1. 生成器网络
在SRGAN和ESRGAN中,用于恢复高分辨率图像的信息只是从最后一个残差块中提取的深层特征,而忽略了前面残差块提取的浅层特征。最后一个残差块不能代表前面所有残差块的贡献。经过一系列卷积运算后,网络前端提取的特征将发生变换、改变甚至丢失。将这些特征传输到网络末端后,它们与网络前端的浅层特征有很大的不同。浅层特征很难保留,但这些特征对于高分辨率图像的重建并非没有意义。因此,为了利用不同层的特征,将从每个残差块提取的特征直接传送到网络的末端。然而,每个残差块位于网络的不同位置,这些位置代表特征演化的不同阶段。因此,不同残差块提取的特征对图像超分辨率重建性能的影响不同。因此,必须变换这些特征,然后再将其直接送到网络末端进行融合,以重建准确的高分辨率图像。RDB用作基本残差块。提出的生成器网络模型在图1中进行了说明。生成器网络简记为TRDN。k表示卷积核的大小,n表示卷积核的数目,s表示卷积的步长。
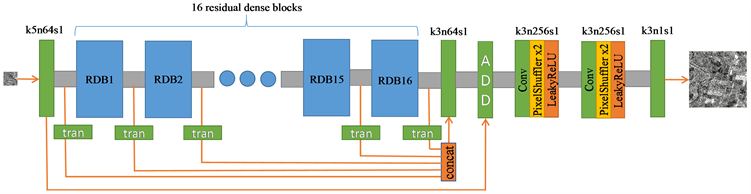
Figure 1. The structure of the generator network
图1. 生成器网络结构
生成器网络包括浅层特征提取、多层变换特征融合、全局残差学习和上采样操作。
3.1.1. 浅层特征提取
首先,提取输入的低分辨率图像的浅层特征:
(4)
其中
表示浅层特征提取操作,并且
表示浅层特征。
3.1.2. 多层变换特征融合
提取的浅层特征用于多层特征提取:
(5)
其中
表示多层特征提取操作,并且
和
分别表示第i个残差块的输入特征和输出特征。然后,获得的浅层特征
和特征
被变换:
(6)
其中,
表示变换操作,并且
表示变换后的多层特征。变换操作的目的是使每个残差块提取的不同层的特征发挥不同的作用,而不是被同等对待。为了简化计算,使用大小为3 × 3的卷积核完成此变换操作。然后将变换后的特征进行融合以获得多层特征:
(7)
其中
表示在特征在通道维度上的叠加,
表示3 × 3卷积运算,
并且表示多层特征。
3.1.3. 全局残差学习
为了促进网络中信息的有效传输,执行全局残差学习:
(8)
其中G表示全局特征。
3.1.4. 上采样操作
最后,将获得的全局特征上采样两次:
(9)
其中
表示上采样操作,上采样因子为2。
3.2. 双重判别
对抗损失的使用使生成的高分辨率图像有更多的高频纹理细节。一些现有的判别算法(例如SRGAN,ESRGAN和A-SRGAN)仅包括高分辨率图像的判别,却忽略了低分辨率图像的作用。根据一张低分辨率图像,可以获得许多高分辨率图像。但是,根据一张高分辨率图像,只能获得一张低分辨率图像。实验中使用的低分辨率图像都是通过双三次插值方法进行降采样得到的。如果重建的高分辨率图像足够准确,则对超分辨图像进行降采样获得的低分辨率图像也应该与最初的低分辨率图像相同。因此,通过对低分辨率图像的判别保证了生成的高分辨率图像可以被正确地降采样到原始的低分辨率图像,以此来指导超分辨图像的生成。判别器网络包含高分判别器和低分判别器,分别用来判别高分辨率图像和低分辨率图像。高分判别器和低分判别器的网络结构如图2所示。

Figure 2. The structure of the discriminator network
图2. 判别器网络结构
生成器损失函数包含内容损失和对抗损失的加权总和:
(10)
其中
。
内容损失定义为真实的高分辨率图像和生成的高分辨率图像之间的均方误差(MSE):
(11)
其中W和H分别表示低分辨率图像的宽和高,r表示上采样因子。
对抗损失包括高分辨率图像和低分辨率图像的判别,定义为:
(12)
根据输入的低分辨率图像,生成器生成尽可能真实的超分辨图像。如果超分辨图像足够准确,则超分辨图像的降采样图像也应与真实的低分辨率图像一致。
高分判别器和低分判别器分别区分高分辨率图像和低分辨率图像的特征,并且将损失函数定义为
(13)
(14)
高分判别器区分真实和重建的高分辨率图像,低分判别器区分真实的低分辨率图像和超分辨图像的降采样图像。
4. 实验
4.1. 实验设置和数据集
在本实验中使用的SAR图像来自哨兵1号(Sentinel-1),分别包括500张图像的训练集和100张图像的测试集。图像均为单波段。高分辨率图像的大小为256 × 256,低分辨率图像的大小64 × 64。低分辨率图像都是真实的高分辨率图像通过双三次插值降采样得到的。
本实验中使用的神经网络框架是TensorFlow 1.14。两个判别器和生成器以交替方式训练。所有网络模型都是从头开始进行训练,而且不依赖任何的基础训练模型。批大小为4,训练迭代次数为106,使用Adam优化器,学习率为0.001,对抗损失权重α为0.00001。
4.2. 评估方法
算法的有效性评估分为客观和主观两个方面。算法的重建性能由超分辨率工作中通常使用的客观评估指标(PSNR和SSIM)来衡量。PSNR从像素级角度衡量真实的高分辨率图像和重建的高分辨率图像之间的差异,其计算公式为
(15)
PSNR包含真实高分辨率图像和超分辨图像之间的均方误差。较高的PSNR表明生成的高分辨率图像的像素值更接近于真实的高分辨率图像。
SSIM从图像结构的角度评估重建的高分辨率图像和实际高分辨率图像之间的相似度,其计算公式如下:
(16)
其中
和
分别表示真实高分辨率图像和重建高分辨率图像的像素平均值;
和
分别表示真实高分辨率图像和重建高分辨率图像的像素标准差,并且
表示真实的高分辨率图像和生成的高分辨率图像的像素协方差。
和
是常数。
,
,其中
,
,
。当两个图像的SSIM接近1时,两个图像更相似。
除了客观评估,还比较了主观效果。生成对抗网络的优势在于其视觉效果。因此,主观效果的比较更好地反映了重建算法的性能。在Sentinel-1数据集上进行的实验在第4.3和4.4节中介绍。
4.3. 消融实验
消融实验的目的是分别验证TRDN和双重判别的作用。首先验证TRDN的作用。RDN用作基准模型。为了确保在公平的环境中进行实验,TRDN中每个残差密集块包含三个卷积操作,而RDN中的残差密集块包含四个卷积操作。此设置可确保TRDN和RDN具有相同的参数。从客观和主观两个角度评估了这两个网络的性能。计算结果列于表1。整个图像和局部区域的放大效果如图3所示。

Table 1. Objective evaluation of RDN and TRDN
表1. RDN和TRDN的客观评价
从以上实验结果来看,虽然TRDN使用的参数数量与RDN使用的参数数量相同,但是TRDN网络的重建性能优于RDN。RDN将从每个RDB中提取的特征直接送到网络的末端,以进行特征融合,而没有区别对待。变换操作通过对每个特征应用带权重的卷积运算,区别对待从每个残差密集块中提取的特征。TRDN考虑了从不同残差块中提取的特征存在差异,通过变换操作将最有用的信息送到网络末端以进行叠加融合。
接下来,验证了双重判别的作用。TRDN作为基本的生成器网络,并验证了单重判别和双重判别的作用。表2列出了计算得出的客观评估指标。主观效果如图4所示。
Table 2. Comparison of objective evaluation between single discrimination and dual discrimination
表2. 单重判别与双重判别的客观评价比较
SGAN是基于TRDN的单重判别的结果。DGAN在TRDN的基础上添加了两个判别器,以执行双重判别。从实验结果来看,单重判别的效果显然不如双重判别。单重判别SGAN仅对高分辨率图像进行判别,而双重判别DGAN不仅考虑了高分辨率图像的判别,而且通过低分辨率图像的判别指导高分辨率图像的合成。在重建高分辨率图像纹理细节方面,双重判别比单重判别具有更好的性能。
4.4. 对比实验
为了验证双重判别算法在重建高频纹理细节方面的优越性能,将其与传统方法(双三次插值)和近年来提出的深度学习算法(SRCNN, SRResNet, SRGAN和RDN)进行了比较。对比实验是从客观和主观两个方面进行的,分别为表3中的客观评价指标和图5中的主观效果。
Table 3. Comparison of DGAN with other algorithms
表3. DGAN与其他算法的比较
从以上比较结果可以看出,DGAN重建的图像在客观评价指标(PSNR和SSIM)上具有明显的优势。从整个图像来看,由SRResNet和SRGAN生成的图像具有良好的效果,但是在放大局部纹理细节之后,所得到的纹理细节不如双重判别重建的图像。由于使用了对抗损失,SRGAN的纹理比SRResNet要清晰,但是从客观评估指标(PSNR, SSIM)来看,SRGAN不如SRResNet。这一结果也与Ledig [1] 等人的研究结论一致。此外,在重建高频纹理细节方面,RDN不如DGAN好。融合了多层变换特征的生成器网络和双重判别使DGAN重建的高分辨率图像有更好的视觉效果。
5. 结论
为了充分利用低分辨率图像的作用,提出了双重判别的SAR图像超分辨率重建算法。在高分辨率图像判别的基础上,双重判别利用了低分辨率图像的唯一性并增加了低分辨率图像的判别。双重判别利用高分辨率和低分辨率图像之间的对应关系来指导网络的训练和高频纹理细节的合成。另外,TRDN结合了来自不同层的变换特征,提高了参数利用率。在SAR图像上进行的实验表明,提出的DGAN算法的性能比最新的超分辨算法更好。